
实现sysfs中的uevent
需求
- 在
sysfs中实现uevent的逻辑,并在设备驱动模型中,发送通用的uevent. - 然后用户测试程序能够通过
epoll感知到这些uevent,并输出。前置知识
https://www.cnblogs.com/schips/p/linux_device_model.html
Linux内核中设备管理和事件通知机制。
sysfs
要分析sysfs,首先就要分析kobject和kset,因为驱动设备的层次结构的构成就是由这两个东东来完成的。sysfs与kobject密不可分。
kobject
kobject是组成设备模型的基本结构,是所有用来描述设备模型的数据结构的基类。
kobject是一个对象的抽象,它用于管理对象。
kset
ktype
设备驱动模型
(Linux Device Driver Model,LDDM)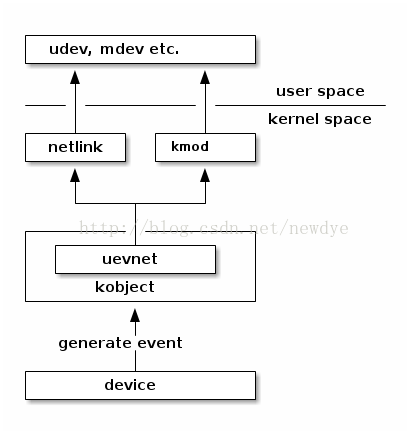
uevent
Uevent只是通过netlink套接字发送的一些特殊格式的字符串。
uevent是kobject的一部分,用于在kobject状态发生改变时,例如增加、移除等,通知用户空间程序。用户空间程序收到这样的事件后,会做相应的处理。
uevent( user space event)是 内核与用户空间的一种基于netlink机制通信机制,主要用于设备驱动模型,常用于设备的热插拔。
例如:U盘插入后,USB相关的驱动软件会动态创建用于表示该U盘的device结构(相应的也包括其中的kobject),并告知用户空间程序,为该U盘动态的创建/dev/目录下的设备节点;更进一步,可以通知其它的应用程序,将该U盘设备mount到系统中,从而动态的支持该设备。
uevent的机制是比较简单的,设备模型中任何设备有事件需要上报时,会触发uevent提供的接口。uevent模块准备好上报事件的格式后,可以通过两个途径把事件上报到用户空间:
- 一种是通过kmod模块,直接调用用户空间的可执行文件;
- 另一种是通过netlink通信机制,将事件从内核空间传递给用户空间。
其中:
netlink是一种socket,专门用来进行内核空间和用户空间的通信;kmod是管理内核模块的工具集,类似busybox,我们熟悉的lsmod,insmod等是指向kmod的链接。
udev
udev是用户空间的守护进程,它监听从内核发送过来的uevent消息,并负责管理设备节点(在/dev目录下),加载所需的驱动程序,以及执行相关的配置脚本和规则。udev确保了设备在用户空间的表示与内核中的状态同步。
mdev
mdev是一个轻量级的udev替代品,它是busybox的一部分,用于在嵌入式系统中管理设备节点。mdev的功能与udev类似,但是更加简单和轻量级,适用于资源有限的嵌入式系统。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# docs/mdev.txt
Mdev has two primary uses: initial population and dynamic updates. Both
require sysfs support in the kernel and have it mounted at /sys. For dynamic
updates, you also need to have hotplugging enabled in your kernel.
Here's a typical code snippet from the init script:
[0] mount -t proc proc /proc
[1] mount -t sysfs sysfs /sys
[2] echo /sbin/mdev > /proc/sys/kernel/hotplug
[3] mdev -s
Alternatively, without procfs the above becomes:
[1] mount -t sysfs sysfs /sys
[2] sysctl -w kernel.hotplug=/sbin/mdev
[3] mdev -s
Of course, a more "full" setup would entail executing this before the previous
code snippet:
[4] mount -t tmpfs -o size=64k,mode=0755 tmpfs /dev
[5] mkdir /dev/pts
[6] mount -t devpts devpts /dev/pts
The simple explanation here is that [1] you need to have /sys mounted before
executing mdev. Then you [2] instruct the kernel to execute /sbin/mdev whenever
a device is added or removed so that the device node can be created or destroyed.
Then you [3] seed /dev with all the device nodes that were created while the system
was booting.
For the "full" setup, you want to [4] make sure /dev is a tmpfs filesystem
(assuming you're running out of flash). Then you want to [5] create the
/dev/pts mount point and finally [6] mount the devpts filesystem on it.
Linux源码分析
https://www.kernel.org/doc/html/next/userspace-api/netlink/intro.html
https://www.man7.org/linux/man-pages/man7/netlink.7.html
https://code.dragonos.org.cn/xref/linux-6.1.9/net/netlink/
kobject.h
kobject_action事件类型
1 | // include/linux/kobject.h |
kobject_action定义了event的类型,包括:
|action|意义|
|—-|—-|
|KOBJ_ADD|表示一个kobject被添加到系统中。这通常意味着一个新的设备被注册或一个新的内核组件被初始化。|
|KOBJ_REMOVE|表示一个kobject从系统中移除。这可能是因为设备被卸载或某个内核组件被销毁。|
|KOBJ_CHANGE|表示一个kobject的状态发生了变化。这个状态的变化可以是很广泛的,比如设备的属性改变。|
|KOBJ_MOVE|表示一个kobject在系统中的位置或归属关系发生了变化。这在设备移动到不同的位置或改变其层次结构时可能发生。|
|KOBJ_ONLINE|表示一个kobject变为在线状态,即它变得可用或激活。这对于需要管理的在线和离线状态的资源特别有用,比如CPU或内存页。|
|KOBJ_OFFLINE|与KOBJ_ONLINE相对,表示一个kobject变为离线状态,即它不再可用或被禁用。|
|KOBJ_MAX|这不是一个实际的操作,而是枚举值的数量。它通常用于数组声明或循环的边界条件,确保处理的操作不会超出定义的范围|
kobject_uevent_env用户环境
1 | // include/linux/kobject.h |
在通过kmod向用户空间上报event事件时,会直接执行用户空间的可执行文件。
而在Linux系统中,可执行文件的执行,依赖于环境变量,因此kobj_uevent_env用于组织此次事件上报时的环境变量。
kset_uevent_ops与策略
1 | // include/linux/kobject.h |
filter:- 参数:struct kset kset, struct kobject kobj
- 返回值:整数
- 功能:
- 这个回调函数用于过滤哪些kobject应该生成uevent通知。在该函数中,您可以根据kset和kobject的信息来决定是否应该生成uevent通知。如果返回值为0,则表示不生成uevent通知;如果返回值为非0,则表示生成uevent通知。
- 当任何kobject需要上报uevent时,它所属的kset可以通过该接口过滤,阻止不希望上报的event,从而达到从整体上管理的目的。
name:- 参数:struct kset kset, struct kobject kobj
- 返回值:指向常量字符的指针(const char *)
- 功能:
- 这个回调函数用于提供生成的uevent通知中的设备名称。它返回一个字符串指针,该字符串指定了与kobject关联的设备的名称。通常,这个名称将在uevent中作为DEVNAME环境变量的值。
- 该接口可以返回kset的名称。如果一个kset没有合法的名称,则其下的所有Kobject将不允许上报
uevent:- 参数:struct kset kset, struct kobject kobj, struct kobj_uevent_env *env
- 返回值:整数
- 功能:
- 这个回调函数用于生成uevent通知。它接收kset、kobject和一个指向kobj_uevent_env结构体的指针作为参数。kobj_uevent_env结构体包含了uevent通知的环境变量信息。在这个回调函数中,您可以设置uevent通知的各种环境变量,例如设备的属性信息。如果生成uevent通知成功,则返回0;否则返回负数。
- 当任何kobject需要上报uevent时,它所属的kset可以通过该接口统一为这些event添加环境变量。因为很多时候上报uevent时的环境变量都是相同的,因此可以由kset统一处理,就不需要让每个kobject独自添加了。
当设备加载或卸载时,是怎么通过这几个uevent的核心类通知用户空间的呢?
通过前面的分析,大家应该知道,设备加载或卸载最直观的体现在/sys下目录的变化,/sys下的目录和kobject是对应的,因此还得从kobject说起。
netlink
目前 netlink 协议族支持32种协议类型,它们定义在 include/uapi/linux/netlink.h 中.
内核Netlink的初始化在系统启动阶段完成,初始化代码在af_netlink.c的netlink_proto_init()函数
af_netlink.c
_netlink_proto_init()
本初始化函数首先向内核注册netlink协议;
然后创建并初始化了nl_table表数组,1
nl_table = kcalloc(MAX_LINKS, sizeof(*nl_table), GFP_KERNEL);
这个表是整个netlink实现的最关键的一步,每种协议类型占数组中的一项,后续内核中创建的不同种协议类型的netlink都将保存在这个表中,由该表统一维护
sock_register(&netlink_family_ops)
调用sock_register向内核注册协议处理函数,即将netlink的socket创建处理函数注册到内核中,如此以后应用层创建netlink类型的socket时将会调用该协议处理函数
register_pernet_subsys(&netlink_net_ops)
调用register_pernet_subsys向内核所有的网络命名空间注册”子系统“的初始化和去初始化函数,这里的”子系统”并非指的是netlink子系统,而是一种通用的处理方式,在网络命名空间创建和注销时会调用这里注册的初始化和去初始化函数,当然对于已经存在的网络命名空间,在注册的过程中也会调用其初始化函数。
网络命名空间
名称空间将全局系统资源包装在一个抽象中,使名称空间中的进程看起来拥有自己的全局资源的独立实例。对全局资源的更改对作为命名空间成员的其他进程可见,但对其他进程不可见。名称空间的一个用途是实现容器。(摘录自Linux man page中对namespace的介绍)
Network namespace允许你在Linux中创建相互隔离的网络视图,每个网络名字空间都有自己独立的网络配置,包括:网络设备、路由表、IPTables规则,路由表、网络协议栈等。新建的网络名字空间与主机默认网络名字空间之间是隔离的。我们平时默认操作的是主机的默认网络名字空间。
rtnetlink_init()
调用rtnetlink_init()创建NETLINK_ROUTE协议类型的netlink,该种类型的netlink才是当初内核设计netlink的初衷,它用来传递网络路由子系统、邻居子系统、接口设置、防火墙等消息。至此整个netlink子系统初始化完成。
内核netlink配置结构:struct netlink_kernel_cfg
netlink属性头:struct nlattr
netlink的消息头后面跟着的是消息的有效载荷部分,它采用的是格式为“类型——长度——值”,简写TLV。
其中类型和长度使用属性头nlattr来表示。其中nla_len表示属性长度;nla_type表示属性类型,它可以取值为以下几种类型(定义在include\net\netlink.h中)。
netlink有效性策略:struct nla_policy
netlink协议可以根据消息属性定义其特定的消息有效性策略,即对于某一种属性,该属性的期望类型是什么,内核将在收到消息以后对该消息的属性进行有效性判断( 如果不设定len值,就不会执行有效性检查),只有判断一致的消息属性才算是合法的,否则只会默默的丢弃。
这种有效性属性使用nla_policy来描述,一般定义为一个有效性对象数组(当前这种netlink协议中的每一种attr属性(指定不是属性类型,而是用户定义的属性)有一个对应的数组项),这里type值同struct nlattr中的nla_type,len字段表示本属性的有效载荷长度。
netlink套接字结构:netlink_sock
本结构用于描述一个netlink套接字,其中portid表示本套接字自己绑定的id号,对于内核来说它就是0,dst_portid表示目的id号,ngroups表示协议支持多播组数量,groups保存组位掩码,netlink_rcv保存接收到用户态数据后的处理函数,netlink_bind和netlink_unbind用于协议子协议自身特有的绑定和解绑定处理函数。
netlink消息报头:struct nlmsghdr
netlink消息同TCP/UDP消息一样,也需要遵循协议要求的格式,每个netlink消息的开头是固定长度的netlink报头,报头后才是实际的载荷。
netlink报头一共占16个字节,具体内容即同struct nlmsghdr中定义的一样。
(1)nlmsg_len:整个netlink消息的长度(包含消息头);
(2)nlmsg_type:消息状态,内核在include/uapi/linux/netlink.h中定义了以下4种通用的消息类型。1
2
3
4
除了这4种类型的消息以外,不同的netlink协议也可以自行添加自己所特有的消息类型,但是内核定义了类型保留宏(#define NLMSG_MIN_TYPE 0x10),即小于该值的消息类型值由内核保留,不可用。
(3)nlmsg_flags:消息标记,它们用以表示消息的类型,同样定义在include/uapi/linux/netlink.h中
(4)nlmsg_seq:消息序列号,用于标识消息的序列号,用于消息的重传和确认。
(5)nlmsg_pid:发送端口的ID号,对于内核来说该值就是0,对于用户进程来说就是其socket所绑定的ID号。
socket消息数据包结构:struct msghdr
DragonOS中的rust实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16pub struct MsgHdr {
/// 指向一个SockAddr结构体的指针
pub msg_name: *mut SockAddr,
/// SockAddr结构体的大小
pub msg_namelen: u32,
/// scatter/gather array
pub msg_iov: *mut IoVec,
/// elements in msg_iov
pub msg_iovlen: usize,
/// 辅助数据
pub msg_control: *mut u8,
/// 辅助数据长度
pub msg_controllen: usize,
/// 接收到的消息的标志
pub msg_flags: u32,
}
应用层向内核传递消息可以使用sendto()或sendmsg()函数,其中sendmsg函数需要应用程序手动封装msghdr消息结构,而sendto()函数则会由内核代为分配。其中
(1)msg_name:指向数据包的目的地址;
(2)msg_namelen:目的地址数据结构的长度;
(3)msg_iov:消息包的实际数据块,定义如下:1
2
3
4
5struct iovec
{
void *iov_base; /* BSD uses caddr_t (1003.1g requires void *) */
__kernel_size_t iov_len; /* Must be size_t (1003.1g) */
};
DragonOS中的rust实现:1
2
3
4
5
6pub struct IoVec {
/// 缓冲区的起始地址
pub iov_base: *mut u8,
/// 缓冲区的长度
pub iov_len: usize,
}
iov_base:消息包实际载荷的首地址;iov_len:消息实际载荷的长度。
(4)msg_control:消息的辅助数据;
(5)msg_controllen:消息辅助数据的大小;
(6)msg_flags:接收消息的标识。
对于该结构,我们更需要关注的是前三个变量参数,对于netlink数据包来说其中msg_name指向的就是目的sockaddr_nl地址结构实例的首地址,iov_base指向的就是消息实体中的nlmsghdr消息头的地址,而iov_len赋值为nlmsghdr中的nlmsg_len即可(消息头+实际数据)。
netlink消息处理宏
Linux为了处理netlink消息方便,在 include/uapi/linux/netlink.h中定义了以上消息处理宏,用于各种场合。对于Netlink消息来说,处理如下格式(见netlink.h):1
2
3
4
5
6
7
8
9
10
11
12
问题分析
内核与用户空间的通信:uevent机制是在Linux内核中用来通知用户空间有特定事件发生的一种机制。通常,当内核中的某个驱动发生特定事件时(比如,挂载或卸载文件系统),它会生成一个uevent,并通过netlink socket发送到用户空间。
Netlink Sockets:Netlink是Linux内核提供的一个机制,允许用户空间程序与内核模块进行双向通信。实现uevent机制时,你需要在内核中创建一个netlink socket,并实现相应的协议来处理消息的发送和接收。
uevent触发条件:确定何时应该触发uevent,这通常与特定的内核事件相关联,如设备添加、删除、属性变更等。
安全性:uevent机制通常涉及到系统安全,因此你需要确保uevent传输过程的安全性,防止未授权访问。
uevent触发条件
找到并标记需要触发uevent的地方,这通常涉及到内核中的特定事件,如设备添加、删除、属性变更等。一旦确定了触发条件,就可以在相应的地方调用uevent机制来发送通知。
netlink(需要自己实现)
在Linux内核中,netlink是一种用于内核与用户空间通信的机制。它提供了一种可靠的、高效的通信方式,允许用户空间程序与内核模块进行双向通信。在实现uevent机制时,需要使用netlink socket来发送和接收uevent消息。
配合方式:uevent和Netlink之间的配合主要体现在uevent消息的发送和接收。当内核检测到一个热插拔事件时,它会创建一个Netlink套接字,并通过该套接字向用户空间发送uevent消息。
参考:
generic netlink是netlink的一种扩展。etlink仅支持32种协议类型,这在实际应用中可能并不足够。因此产生了generic netlink(以下简称为genl)。
generic netlink支持1023个子协议号,弥补了netlink协议类型较少的缺陷。支持协议号自动分配。它基于netlink,但是在内核中,generic netlink的接口与netlink并不相同。
https://www.cnblogs.com/CasonChan/p/4867587.html
netlink socket开发进度
Netlink 是一种特殊的 socket,它是 Linux 所特有的,类似于 BSD 中的AF_ROUTE 但又远比它的功能强大,目前在Linux 内核中使用netlink 进行应用与内核通信的应用很多; 包括:路由 daemon(NETLINK_ROUTE),用户态 socket 协议(NETLINK_USERSOCK).
Netlink 是一种在内核与用户应用间进行双向数据传输的非常好的方式,用户态应用使用标准的 socket API 就可以使用 netlink 提供的强大功能,内核态需要使用专门的内核 API 来使用 netlink。
防火墙(NETLINK_FIREWALL),netfilter 子系统(NETLINK_NETFILTER),内核事件向用户态通知(NETLINK_KOBJECT_UEVENT),通用 netlink(NETLINK_GENERIC)等。
数据结构
- [已有] msghdr: 用于发送和接收消息的数据结构。
- [X] sockaddr_nl: 用于指定netlink地址的数据结构。
- [X] nlmsghdr: Netlink的报文由消息头和消息体构成,struct nlmsghdr即为消息头。消息头定义在文件里,由结构体nlmsghdr表示
struct net网络设备命名空间指针。struct sock是套接口在网络层的表示。struct sk_buff结构是Linux网络代码中重要的数据结构,它管理和控制接收或发送数据包的信息。struct sockaddr_nl是netlink通信地址。struct netlink_kernel_cfgnetlink的配置结构体。struct nlmsghdr是netlink提供的协议头,netlink协议是面向消息的,需要定义自己的协议。自定义协议按照协议头格式填充协议头内容,并定义自己的payload,通常自定义的协议体包含自定义协议头与额外的属性。
用户空间Netlink socket API
- [已有] socket: 创建一个netlink socket。
- [已有] bind: 将socket绑定到一个netlink地址。
- [已有] sendto: 发送消息到指定的netlink地址。
- [已有] recvfrom: 从指定的netlink地址接收消息。
- …
内核空间Netlink socket API
- [x] netlink_kernel_create()/netlink_kernel_release() 创建/销毁struct sock
- [x] netlink_unicast: 发送单播消息
- [√] netlink_broadcast: 发送广播消息
查找kobj本身或者其parent是否从属于某个kset,如果不是,则报错返回(注2:由此可以说明,如果一个kobject没有加入kset,是不允许上报uevent的)
查看kobj->uevent_suppress是否设置,如果设置,则忽略所有的uevent上报并返回(注3:由此可知,可以通过Kobject的uevent_suppress标志,管控Kobject的uevent的上报)
如果所属的kset有kset->filter函数,则调用该函数,过滤此次上报(注4:这佐证了3.2小节有关filter接口的说明,kset可以通过filter接口过滤不希望上报的event,从而达到整体的管理效果)
判断所属的kset是否有合法的名称(称作subsystem,和前期的内核版本有区别),否则不允许上报uevent
分配一个用于此次上报的、存储环境变量的buffer(结果保存在env指针中),并获得该Kobject在sysfs中路径信息(用户空间软件需要依据该路径信息在sysfs中访问它)
调用add_uevent_var接口(下面会介绍),将Action、路径信息、subsystem等信息,添加到env指针中
如果传入的envp不空,则解析传入的环境变量中,同样调用add_uevent_var接口,添加到env指针中
如果所属的kset存在kset->uevent接口,调用该接口,添加kset统一的环境变量到env指针
根据ACTION的类型,设置kobj->state_add_uevent_sent和kobj->state_remove_uevent_sent变量,以记录正确的状态
调用add_uevent_var接口,添加格式为”SEQNUM=%llu”的序列号
如果定义了”CONFIG_NET”,则使用netlink发送该uevent
以uevent_helper、subsystem以及添加了标准环境变量(HOME=/,PATH=/sbin:/bin:/usr/sbin:/usr/bin)的env指针为参数,调用kmod模块提供的call_usermodehelper函数,上报uevent。
其中uevent_helper的内容是由内核配置项CONFIG_UEVENT_HELPER_PATH(位于./drivers/base/Kconfig)决定的(可参考lib/kobject_uevent.c, line 32),该配置项指定了一个用户空间程序(或者脚本),用于解析上报的uevent,例如”/sbin/hotplug”。
call_usermodehelper的作用,就是fork一个进程,以uevent为参数,执行uevent_helper。
测试
对netlink的测试分为两部分,一部分是内核提供接收用户空间消息,并响应发送功能;另一部分是用户空间发送netlink到内核,并等待回复。
uevent机制
uevent使用的netlink协议是:pub const NETLINK_KOBJECT_UEVENT: u32 = 15;
设计思路
trait NetlinkSocket
NetlinkSocket是netlink机制特定的内核抽象,不同于原本内核中实现的trait Socket,他们之间没有继承关系。1
2
3
4
5
6
7
8
9// netlink机制特定的内核抽象,不同于标准的trait Socket
pub trait NetlinkSocket :Sync + Send + Debug + Any{
// fn sk_prot(&self) -> &dyn proto;
fn sk_family(&self) -> i32;
fn sk_state(&self) -> i32;
fn sk_protocol(&self) -> usize;
fn is_kernel(&self) -> bool;
fn equals(&self, other: &dyn NetlinkSocket) -> bool;
}
struct NetlinkSock
NetlinkSock实现了自己的一套作为socket特有的经典的收发、绑定、解绑和注册等方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/* linux:struct sock has to be the first member of netlink_sock */
pub struct NetlinkSock {
sk: Box<dyn NetlinkSocket>,
portid: u32,
dst_portid: u32,
dst_group: u32,
flags: u32,
subscriptions: u32,
ngroups: u64,
groups: Vec<u64>,
state: u64,
max_recvmsg_len: usize,
dump_done_errno: i32,
cb_running: bool,
}
struct UeventSock
UeventSock结构体包含了一个NetlinkSock结构体对象字段,这是因为在linux内核中,uevent socket属于一种特殊的netlinksocket,用于接收内核的uevent消息。因此把UeventSock定义为一种特殊的NetlinkSock。他作为NetlinkSock的一种,也需要实现NetlinkSocket的trait。1
2
3
4
5
pub struct UeventSock {
netlinksock:NetlinkSock,
list: Vec<ListHead>,
}
一些暂时不支持的特性
- struct Net 网络空间命名
与linux实现不同的地方
- gfp_mask: 内核中的gfp_mask是一个用于内存分配的标志,用于指定内存分配的行为。在Rust中,我们可以使用
Box或Rc来分配内存,而不需要使用gfp_mask。
总结转译Linux代码的方法
以kobject为例,我们可以通过以下几个步骤来转译Linux内核代码:
- 根据继承关系来转译结构体中的数据成员。通过行为继承(fn)来实现数据继承
- 数据成员结构体(如
struct kobject: *parent和struct ket:*ket)->fn1
2
3
4fn parent(&self) -> Option<Weak<dyn KObject>>;
/// 设置当前kobject的parent kobject(不一定与kset相同)
fn set_parent(&self, parent: Option<Weak<dyn KObject>>); - 函数指针-> fn
- trait->
- struct->
- goto->闭包?
数据类型对应关系替代
整型 (Integers)
char (C 中的无符号字符): char 在 Rust 中是无符号的,范围通常在 0 到 255 之间。
- short->i16,
- int->i32,
- long->i64,
- long long ->i128,
- unsigned char->u8,
- unsigned short-> u16,
- unsigned int-> u32,
- unsigned long-> u64,
- unsigned long long (C 中的无符号整数)->u128
浮点型 (Floating-Point Numbers)
float, double, long double (C 中的浮点数): Rust 中的相应类型是 f32, f64, f64 是 Rust 的默认浮点数精度。
布尔型 (Booleans)
_Bool (C 中的布尔类型): Rust 中的 bool 类型。
字符串 (Strings)
C 中的字符串通常是 char 或 const char 类型。Rust 使用 String 类型,这是一个可变的、动态大小的字符串类型,通常使用 String::from 或 String::new 创建。
指针 (Pointers)
C 中的指针通过 Rust 中的引用和 Box 来实现。普通引用用于可变或不可变的值,而 Box
是 Rust 的堆分配机制。
关于引用和所有权等
在Rust中,函数参数的类型(值、共享引用或引用计数)取决于函数需要做什么。以下是一些一般的指导原则:
如果函数只需要读取参数的值,不需要修改它,那么你应该使用共享引用(
&T)。这样,函数可以读取值,但不能修改它。这也意味着你可以在函数调用后继续使用这个值。如果函数需要修改参数的值,那么你应该使用可变引用(
&mut T)。这样,函数可以读取和修改值。但是,你不能在函数调用后继续使用这个值,除非你再次借用它。如果函数需要拥有参数的所有权,那么你应该使用值(
T)。这样,函数可以读取、修改和销毁值。但是,你不能在函数调用后继续使用这个值,因为它的所有权已经被移动。如果函数需要共享参数的所有权,那么你应该使用引用计数(
Arc<T>或Rc<T>)。**这样,函数可以读取和修改值,而且你可以在函数调用后继续使用这个值,因为它的所有权被共享,而不是被移动。
关于所有权的规划,Rust的所有权规则是为了保证内存安全而设计的。以下是一些一般的指导原则:
尽量避免克隆值。克隆值会消耗额外的内存和CPU时间。如果可能,你应该使用引用或引用计数。
尽量避免使用
Rc<T>或Arc<T>。虽然它们可以让你共享所有权,但是它们会增加引用计数的开销,并且可能导致循环引用。如果可能,你应该使用引用。尽量避免使用
RefCell<T>或Mutex<T>。虽然它们可以让你在运行时检查借用规则,但是它们会增加运行时的开销。如果可能,你应该在编译时检查借用规则。尽量让函数拥有它们需要的所有权。这样,你可以避免不必要的引用和克隆。但是,你也需要确保你在函数调用后不再需要这个值。
尽量让结构体拥有它们的字段的所有权。这样,你可以避免不必要的引用和克隆。但是,你也需要确保你在结构体被销毁后不再需要这些字段。
尽量让变量拥有它们的值的所有权。这样,你可以避免不必要的引用和克隆。但是,你也需要确保你在变量离开作用域后不再需要这个值。
以上的指导原则并不是绝对的。在某些情况下,你可能需要违反这些原则,例如,为了避免数据竞争,你可能需要使用Mutex<T>,或者为了共享大型数据结构,你可能需要使用Arc<T>。你应该根据你的具体需求来决定使用哪种类型。
问题
Arc
这个错误信息表明你尝试在多线程环境中使用了一个不满足线程安全要求的
Arc。Arc是用于提供线程安全引用计数的智能指针,但是它包含的类型也必须是线程安全的。在Rust中,线程安全主要通过Send和Sync这两个trait来保证:Send表示类型的所有权可以安全地从一个线程传递到另一个线程。Sync表示类型的不可变引用可以安全地在多个线程之间共享。RefCell<T>并不是线程安全的,因为它允许在运行时对借用的数据进行可变访问,而没有编译时的线程安全保证。因此,RefCell<T>不实现Synctrait,这意味着Arc<RefCell<T>>也不是线程安全的。
错误信息建议的解决方案有两个:
- 使用
Rc代替Arc:如果你的代码实际上不需要跨线程共享这个RefCell,你可以使用Rc代替Arc。Rc是一个非线程安全的引用计数指针,适用于单线程场景。但是,如果你的应用确实需要跨线程共享数据,这个方法就不适用了。 - 使用
Mutex或RwLock来包装内部类型:如果你需要在多线程环境中共享和修改SkBuff,你可以使用Mutex<T>或RwLock<T>来包装SkBuff。这两个类型提供了线程安全的内部可变性,使得Arc<Mutex<SkBuff>>或Arc<RwLock<SkBuff>>可以安全地在多个线程之间共享和修改。
下面是使用Mutex的示例代码:这样,你就可以在多线程环境中安全地共享和修改1
2
3
4>use std::sync::{Arc, Mutex};
>use std::cell::RefCell;
>let skb = Arc::new(Mutex::new(SkBuff::new()));SkBuff了。
mutex不支持borrow()和borrow_mut()方法,遂采用Rc
参考driver解决nlk_sk的问题
- inet没有实现网络协议族的操作集。https://code.dragonos.org.cn/xref/linux-6.1.9/include/net/sock.h#1230
- classic netlink还是generic netlink?
- generic netlink使用classic netlink的API。generic netlink是netlink的一种扩展,它支持1023个子协议号,弥补了netlink协议类型较少的缺陷。generic netlink基于netlink,但是在内核中,generic netlink的接口与netlink并不相同。generic netlink的API是通过netlink的API来实现的,因此generic netlink使用classic netlink的API。
- 经典Netlink和通用Netlink之间的主要区别是子系统标识符的动态分配和自省的可用性。 在理论上,协议没有显著的区别,然而,在实践中,经典Netlink实验了通用Netlink中被放弃的概念(实际上,它们通常只在一个单一子系统的一小角落中使用)。本节旨在解释一些这样的概念, 其明确的目标是让通用Netlink用户在阅读uAPI头时有信心忽略它们。
- 图解NETLINK_ROUTE和NETLINK_GENERIC调用过程


kset_uevent_ops结构体
1
2
3
4
5
6
7
8
9
10
11
12struct kset_uevent_ops {
int (* const filter)(struct kset *kset, struct kobject *kobj);
//filter,当任何Kobject需要上报uevent时,它所属的kset可以通过该接口过滤,
//阻止不希望上报的event,从而达到从整体上管理的目的。
const char *(* const name)(struct kset *kset, struct kobject *kobj);
//name,该接口可以返回kset的名称。如果一个kset没有合法的名称,
//则其下的所有Kobject将不允许上报uvent
int (* const uevent)(struct kset *kset, struct kobject *kobj,
struct kobj_uevent_env *env);
//uevent,当任何Kobject需要上报uevent时,它所属的kset可以通过该接口统一为这些event添加环境变量。
//因为很多时候上报uevent时的环境变量都是相同的,因此可以由kset统一处理,就不需要让每个Kobject独自添加了。
};用户空间使用netlink套接字和内核通信,和传统的套接字是一样首先使用socket系统调用要创建用户空间套接字,不同的是内核也要创建对应的内核套接字,两者通过 nl_table 链表进行绑定;创建内核套接字时,要定义接收用户空间 netlink 消息的 input 函数,如 NETLINK_ROUTE 簇的 input 函数就是 rtnetlink_rcv。 nl_table 是 netlink 机制的核心数据结构,围绕此结构的内核活动有:
- 用户空间应用程序使用 socket 系统调用创建套接字,然后在 bind 系统调用时,内核netlink_bind 函数将调用 netlink_insert(sk, portid) 将此用户态套接字和应用程序的进程 pid 插入 nl_table,这里参数 portid 就是进程 pid;
- 创建内核套接字时,调用 netlink_insert(sk, 0) 将此用户态套接字插入 nl_table(因为是内核套接字,这里 portid 是0);
- 用户空间向内核发送 netlink 消息时,调用 netlink_lookup 函数,根据协议簇和 portid 在nl_table 快速查找对应的内核套接字对象;
- 当内核空间向用户空间发送 netlink 消息时,调用netlink_lookup 函数,根据协议簇和 portid 在 nl_table 快速查找对应的用户套接字对象.
初始化数组nl_table 每个netlink协议簇对应nl_table数组的一个条目(struct netlink_table类型),一共32个。nl_table是netlink子系统的实现的一个关键表结构,其实是一个hash链结构,只要创建netlink套接字,不管是内核的还是用户空间的,都要调用netlink_insert将netlink套接字本身和它的信息一并插入到这个链表结构中(用户态套接字在bind系统调用的时候调用netlink_insert插入nl_table;内核套接字是在创建的时候调用netlink_insert插入nl_table),然后在发送时,只要调用netlink_lookup遍历这个表就可以快速定位要发送的目标套接字。
- 在Linux6.1.9中,netlink_table 的 hash 是重新实现的 rhashtable,为了方便先使用 HashMap 实现,后续如果有需要再替换为 rhashtable。
- lazy<>初始化的问题
- nltable 如果用 Arc 无法修改,转为使用RWLock
- 如何借鉴rust-netlink?
- 借鉴rust for linux?
- 关于sk_buff的实现,原本是在 PacketBuffer 的基础上封装了一层,但是缺少需要的接口和字段(如 len() 和 sk),因此需要调研一下是否需要重新封装或者用别的库。
- skb的类型
Arc<RwLock<>> - sk的类型
Arc<dyn NetlinkSocket>? ->Arc<RwLock<Box<dyn NetlinkSocket>>>,解决了Arc内部可变性 - Borrowed data escapes outside of function
- 更换SkBuff的实现方式
- new方法循环初始化
- 解决方法:Option
初始化为None
- 解决方法:Option
- 套接字中的回调函数为 sk_data_ready()
- 默认的 ->sk_data_ready() 回调函数是 sock_def_readable()。
1
2
3
4
5
6void sock_init_data(struct socket *sock, struct sock *sk)
{
sk->sk_data_ready = sock_def_readable;
sk->sk_write_space = sock_def_write_space;
sk->sk_error_report = sock_def_error_report;
}1
2
3
4
5
6
7
8
9
10
11
12static void sock_def_readable(struct sock *sk, int len)
{
struct socket_wq *wq;
rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
if (wq_has_sleeper(wq))
wake_up_interruptible_sync_poll(&wq->wait, POLLIN | POLLPRI |
POLLRDNORM | POLLRDBAND);
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
- 默认的 ->sk_data_ready() 回调函数是 sock_def_readable()。
- 回调函数是否需要通知链?

- 事件等待队列
- netlink_rcv 回调
- static const struct proto_ops netlink_ops 规定接口的操作的具体执行函数,-》实现socket trait
由于netlink_bind 函数接受的是 NetlinkSocket ,而 Socket 似乎是无法转换为 NetlinkSocket 的
- 解决方法:
可以使用intertrait库来做,参考“dyn device转 dyn platformDevice(或者I8042PlatformDevice)”:
https://code.dragonos.org.cn/xref/DragonOS/kernel/src/driver/input/serio/i8042/i8042_device.rs?r=da152319797436368304cbc3f85a3b9ec049134b#22
device继承KObject,实现了CastFromSync https://code.dragonos.org.cn/xref/DragonOS/kernel/src/driver/base/kobject.rs?r=2eab6dd743e94a86a685f1f3c01e599adf86610a#26
dyn Device向上转换 https://code.dragonos.org.cn/xref/DragonOS/kernel/src/driver/base/platform/subsys.rs?r=2eab6dd743e94a86a685f1f3c01e599adf86610a#134
- 解决方法:
bind 如何调用到 netlink_bind 函数?
- 用户空间传递正确的 SockAddr 对象
发生 panic
- metadata()
- posix_item()
8.10: socket_handle() todo!
socket trait 中基于smoltcp 的 socket 结构体构造了一个 GlobalSocketHandle 类型的变量 handle 作为数据成员。在handle 初始化的时候需要该 socket 结构体对象传入;而由于 NetlinkSock 不包含 smoltcp 的 socket 结构体,无法直接通过添加 handle 字段并初始化的方式来实现该方法,从而引发了 panic。 - socketInode
- GlobalSocketHandle
网络子系统重构后
在 netlink 中有两套发送及接收数据的接口,分别是 sendto和recvfrom、sendmsg和recvmsg
在Linux 6.1.9中,sendmsg和recvmsg对应的是应该对应实现为netlinksocket的read和write方法。1
2static int netlink_sendmsg(struct socket *sock, struct msghdr *msg, size_t len)
static int netlink_recvmsg(struct socket *sock, struct msghdr *msg, size_t len, int flags)
暂时不实现:scm,SCM(Socket Control Message)用于传递额外的控制信息
这个SYS_RECVMSG系统调用传递的参数是不是太少了?只有buf
socketfs文件系统
在 Netlink 通信中,每个消息都包含一个 nlmsghdr 头部,后面跟随的是协议特定的数据。Netlink 协议本身并不区分数据报和原始套接字(raw sockets),即使用 SOCK_RAW 或 SOCK_DGRAM 作为 socket 类型都是可行的。
Netlink 套接字接收数据时,每个消息必须作为独立的数据报接收。如果用户空间提供的缓冲区太小,不足以容纳整个消息,消息将会被截断,recvmsg() 系统调用的 msghdr 结构中的 MSG_TRUNC 标志将被设置。如果发生截断,消息的其余部分将被丢弃。为了避免消息截断,建议用户空间的接收缓冲区至少为 8kB 或 CPU 架构的页面大小,以较大者为准。对于大多数情况,推荐使用 32kB 的缓冲区,这样可以更高效地处理大量数据
今天被一个事情困扰了:之前写netlink这一块的时候主要是参照Linux的sk_buff结构,来作为网络数据包,然后参照了aya_ebpf的库,搞了一个sk_buff, 涉及到比较多的相关的操作。然后今晚看zcore和aster好像都是直接没有这个数据包的结构?直接用vec进行数据的读取。我们的inet里的datagram参考他们似乎也是这样的,不过看到后面是smoltcp的recv_slice调用。就我现在有点不知道是该继续沿用Linux或者aya_ebpf这一套去操作底层的unsafe实现一大堆sk_buff的这个操作还是全都简化成类似于Arc
没有实现异步
简化!前面很多跟skb有关的代码都暂时没用了
内存异步没实现呢
可以默认一切内存读写都是同步的
Endpoint这个东西到底怎么说

msghdr这个结构在socket变成中就会用到,并不算Netlink专有的,这里不在过多说明。只说明一下如何更好理解这个结构的功能。我们知道socket消息的发送和接收函数一般有这几对:recv/send、readv/writev、recvfrom/sendto。当然还有recvmsg/sendmsg,前面三对函数各有各的特点功能,而recvmsg/sendmsg就是要囊括前面三对的所有功能,当然还有自己特殊的用途。msghdr的前两个成员就是为了满足recvfrom/sendto的功能,中间两个成员msg_iov和msg_iovlen则是为了满足readv/writev的功能,而最后的msg_flags则是为了满足recv/send中flag的功能,剩下的msg_control和msg_controllen则是满足recvmsg/sendmsg特有的功能。
这一行出现了Location: File: src/driver/base/uevent/kobject_uevent.rs Line: 116, Column: 38 Message: called Option::unwrap() on a None value
更改:let mut top_kobj = kobj.clone();
用户空间的库函数期望返回的值跟内核不兼容
NetlinkEndpoint 和 SockAddr 之间的转换
the trait bound
NetlinkEndpoint: socket::addr::private::SockaddrLikePrivis not satisfied
the following other types implement traitsocket::addr::private::SockaddrLikePriv:
()
AlgAddr
LinkAddr
NetlinkAddr
SockAddr
SockaddrIn
SockaddrIn6
SockaddrStorage
and 2 othersSockaddrLikeis a “sealed trait”, because to implement it you also need to implementnix::sys::socket::addr::private::SockaddrLikePriv, which is not accessible; this is usually done to force you to use one of the provided types that already implement it
the following types implement the trait:
nix::sys::socket::UnixAddr
()
nix::sys::socket::SockaddrIn
nix::sys::socket::SockaddrIn6
nix::sys::socket::SockaddrStorage
nix::sys::socket::SockAddr
nix::sys::socket::NetlinkAddr
nix::sys::socket::AlgAddr
闭包、泛型的定义和限制
回调函数?
跑通现有的函数;监听?udev!
udev
udev通过对sysfs下的文件读/写来实现对设备的控制。
比如udevadm trigger,会对/sys/devices/pci0000:00/../uevent写入’add’,’remove’或’change’等命令,调用到sysfs的ops接口,最终操纵到对应的device。
同时,当device发生变化时,比如接入/拔出了一个设备,又会通过内核的uevent机制,将这个变化通知到udev。udev根据uevent中的内容,与/lib/udev/rules.d/下的规则做匹配。匹配到相同类型的device后,可以在/sys/下创建设备或是执行一些命令。
前面在提及/sys/devices的初始化函数devices_init时,涉及到了结构体kset与入参device_uevent_ops。
kset下有成员uevent_ops,即这个目录对应的uevent操作。device_uevent_ops就是当/sys/devices这个目录发生变化时会调用的uevent操作。
发送uevent后,udev就能够用env中的字符串同.rules中的规则进行匹配,匹配到相同规则的device后可以进行处理。
通过netlink广播uevent事件。udev监听socket,sysfs通过socket将uevent广播,事件最终被udev接收到。
内核态在uevent_net_init创建netlink的socket:
在uevent_net_broadcast_untagged中遍历uevent_sock_list的所有socket并广播uevent:
Netlink socket是内核和用户进程之间的一种通信方式,同时它也用于在不同的用户进程间进行通讯,在这一点上有点像Unix domain sockets。
跟Unix domain sockets(apue-第17.3章)一样,Netlink socket也只能用于同一主机上的进程通讯,不能像 INET sockets(网络套接字)一样可以用于不同主机间的进程通讯。因此,Netlink socket的效率比 INET sockets高。
Netlink socket和Unix domain sockets挺相似的,它们区别在于:
while the Unix domain sockets use the file system namespace, Netlink processes are usually addressed by process identifiers
捋一下,目前已经实现的:
- 用户态和内核态 netlink socket 的读写(u8)
- uevent核心的几个函数(部分还是修改的skb,待迁移到修改buffer)
- uevent文件写入改动触发uevent事件(待测试)
- /sys下设备目录的uevent文件,必备的基础信息可能还缺少
还未实现的: - 监听
- udev?
还没看见有uevent的:
- acpi
- tty0
20241003
- nlk的转换,参考cfg那一次commit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24let nlk: Arc<NetlinkSock> = Arc::clone(&sk)
.arc_any()
.downcast()
.map_err(|_| SystemError::EINVAL)?;
let nlk = Arc::new(RwLock::new(
sk.lock()
.deref()
.as_any()
.downcast_ref::<NetlinkSock>()
.ok_or(SystemError::EINVAL)?
.clone(),
));
let nlk = {
let sock_guard = sock.lock();
let netlink_sock = sock_guard
.deref()
.as_any()
.downcast_ref::<NetlinkSock>()
.ok_or(SystemError::EINVAL)?
.clone();
Arc::new(SpinLock::new(netlink_sock))
}; - masks?的长度
- registered?在什么时候注册
- gruops?咋内容这么奇怪
20241005
- 整理一下回调函数这一块的内容
- 接下来需要做的:清理日志
- 清理好废弃的设计
- 着手准备文档
20241007
- 具体块设备/字符设备的结构体中是不是需要添加一个ops字段,用于让块设备和字符设备对象能够调用BlockDeviceOps/CharDeviceOps的方法
20241008
- 不需要,请教了谢润霖之后知道了通过idtable来实现获取设备号
- 块设备和字符设备是不是还没有在sysfs下创建目录?
20241013
设备类型转换失败没有显示捕获,定位费了很多时间。
1 | let char_device = match device.cast::<dyn CharDevice>() { |
1016
- 中断上下文中使用了mutex,NO!换成spinklock
- rust Vec<> 类型用vec![]初始化数组被污染
1017
- 要怎么测试呢,内核启动的时候没有监听者,用户程序监听之后,内核如何产生uevent呢?
- setsocketopt: NETLINK_ADD_MEMBERSHIP
- 非常奇怪,portid为什么插入之后变了: 初始化为0了
1020
- uevent 应该由谁返回给用户空间?skb 还是 Netlinksock 的字段?
1023 - 内核空间的套接字接收到消息了,怎么传递给用户空间?
- todo: 用户空间发往内核需要完善sendmsg函数,调用 unicast 单播函数
- netlink_unicast 函数则用于向特定的用户空间进程发送单播消息,这在 uevent 机制中通常不是必需的,因为 uevent 通常需要被多个用户空间程序接收
- udev作为一个用户空间的设备管理程序,由驱动程序向内核捕获Uevent。当udev收到内核的Uevent事件时,它首先会侦听内核事件,然后在匹配设备节点和正则表达式方面执行是否需要更改udev规则,从而在设备节点中添加或删除属性。同时,udev会随时保持与内核同步,以确保设备变化的信息是实时的。
Netlink相对于其他的通信机制具有以下优点:
1)使用Netlink通过自定义一种新的协议并加入协议族即可通过socket API使用Netlink协议2)完成数据交换,而ioctl和proc文件系统均需要通过程序加入相应的设备或文件。
3)Netlink使用socket缓存队列,是一种异步通信机制,而ioctl是同步通信机制,如果传输的数据量较大,会影响系统性能。
4)Netlink支持多播,属于一个Netlink组的模块和进程都能获得该多播消息。
5)Netlink允许内核发起会话,而ioctl和系统调用只能由用户空间进程发起。
1024
3个问题
- bind的时候,portid的改变没有反应到 fd 对应的socket上。
- data没有复制到对应的地方
- 面向对象风格
1025
- 重构NetlinkSock
1029

- 输出的内容有点问题
- system
- <0000000< 是什么东西
- 如果读取的是一个字符串,怎么给udev处理?不能空格吗?
- 多消息的处理,需要添加一个队列?
- 组播消息不支持阻塞?
1 | // 创建一个用于环境变量的缓冲区 |
1 | [ INFO ] (src/driver/base/uevent/kobject_uevent.rs:159) init: buf: [0, 0, 0, 0, 60, 0, 48, 0, 48, 0, 48, 0, 48, 0, 48, 0, 48, 0, 48, 0, 48, 0, 60, 0, 0, 0, 0, 0, 0, 0, 0, 0] |
初始化问题
