
操作系统复习笔记
操作系统复习笔记
Introduction
What is an OS
OS is a collection of one or more software modules that manages and controls the resources of a computer or other computing or electronic device, and gives users and programs an interface to utilize those resources.
操作系统是一个或多个软件模块的集合,它管理和控制计算机或其他计算或电子设备的资源,并为用户和程序提供利用这些资源的界面。
- an extended machine
- top-down view
- provide standard library
- implements a VM on top of machine
- top-down view
- a resource manager
- 1st generation: no OS,真空管和穿孔卡片
- 2nd generation: early batch system,晶体管和批处理系统
- 3rd generation: multiprogramming, spooling and time-sharing 集成电路和多道程序设计
- 4th generation: personal computing
- 5th generation: 1990-now, mobile computing
syscall
- syscall是用于请求系统服务的
- 通过系统 API 调用系统服务:
Fork是 POSIX 中创建新进程的唯一方式Fork创建了原进程的一个副本,被创建的副本是原进程的子进程Fork被调用一次但是会返回两次:- 在子进程中返回
0,在父进程中返回子进程的PID,错误返回-1
- 在子进程中返回
execve被用于fork后,来把进程的内存空间让给一个新的程序,可以用于让子进程来执行与父进程不同的内容exec有很多类型的调用(execl、execle等等)
waitpid用于等待一个子进程的结束(有多个参数,第一个参数为pid,第二个参数statloc,第三……其他)- the big mess
- All operating system operations are put into a single file. The OS is a clloection of procedures that each of which can call each other.
- 例如: BSD, UNIX, System V
Layered structure 层次式系统
- 例如:THE OS
- 每个layer的OS都有不同的任务
- 每一层都可以访问底层,但是不能访问更高层
- hide info at each layer
- 优点:modularity, easy debugging/update
- 缺点:complex
Microkernel structure 微内核
- 把操作系统的大部分功能放在用户空间,提供最小功能
- 优点:easy to extend system(add app 不会 disturb kernel)
- 缺点:overhead performance性能开销
Client-Server 客户端-服务器模式
- 是微内核系统的一个变种
- 把processes分为client和server,make kernel 最小 to 支持 communication between client and server
- OS is a collection of servers that provide services to clients
- 优点:adaptability to use in distributed systems
- 缺点:doing OS function in the user space is different?
虚拟机
- 虚拟机软件是位于硬件层上
- 每个虚拟机都相当于一台单独的硬件设备,每个虚拟机上安装的操作系统都认为自己拥有单独的硬件
- 有两种类型的 hypervisor:type1和type2
- type1 hypervisor:直接运行在硬件上,没有操作系统。如VM/370。
- type2 hypervisor:运行在宿主操作系统上,客户操作系统和宿主操作系统之间哦有模拟器(machine simulator)
- JVM:Java编译器将结果给到JVM解释器,JVM代码可以通过网络传输到其他有JVM的机器上运行
外核exokernel
外核机制的优点是减少了映像层。在其他设计中,每个虚拟机都认为自己有从盘块号0到最大编号的磁盘,这样虚拟机监控程序必须维护一张表来重映像硬件资源。
有了外核就不需要这个重映像处理了,外核只需要记录已经分配给虚拟机的有关资源即可。这个方法还可以把多道程序(在外核内)与用户操作系统代码(用户空间内)加以分离,而且负载并不重,因为外核只需要保持虚拟机彼此不发生冲突。chapter 2 Processes and Threads
Process Model
- a mode of operation that provides for the interleaving(交错) execution of multiple programs by single processor
- allows multiple apps to run at the same time
进程和程序的区别
- 程序是一个指令的集合,是一个静态的概念,进程描述并发,是一个动态的概念
- 进程包括程序、数据和 PCB
- 进程是临时的,程序是持久的
- 一个程序可以是一个多进程的执行程序,一个进程也可以调用多个程序
- 进程可以创建子进程
进程的创建
4种主要事件会导致进程的创建: - 系统初始化
- 正在运行的程序执行了创建进程的系统调用
- 用户请求创建一个新进程
- 一个批处理作业的初始化
在unix子系统上,进程的创建是通过fork()系统调用来实现的。fork()系统调用会创建一个新的进程,新进程是调用进程的一个副本,但是有不同的PID。新进程的代码段、数据段和堆栈段都是调用进程的副本,但是新进程有自己的进程控制块(PCB)。
- 刚开始时父子进程有完全相同的内存映像(memory https://github.com/val213/val213.github.io/blob/hexo_source/source/_posts/image),相同的运行环境,相同的打开文件。
- 在调用 execve()后,子程序加载一个新的程序,否则将执行父进程的相同程序
- 父子进程之间的区别在于fork()的返回值,父进程返回子进程的PID,子进程返回0
在 Windows 中,CreateProcess 处理了创建和加载新应用到进程两个过程。
- 前台进程是指直接与用户交互的进程。这些进程通常是用户主动启动的,用于执行需要用户输入或显示输出给用户的任务。
- 后台进程通常由系统或其他程序启动,执行一些如日志记录、系统监控、定时任务等不需要用户直接干预的任务。被称为守护进程(daemons)
进程的终止
- 正常退出(自愿的 voluntary):UNIX 中的 Exit 和 Windows 中的 ExitProcess
- 错误退出(自愿):如编译错误
- 致命错误退出(Fatal error,非自愿):除以 0,执行非法指令,段错误
- 被其他进程 killed(非自愿):UNIX 中的 Kill 和 Windows 的 TerminateProcess
进程的层次结构
- 在UNIX中,进程和它所有的子进程以及后裔构成一个进程组。init 进程是所有进程的祖先,整个系统的进程都属于以init为根的树。
- 在Windows中没有进程层次的概念,所有进程的地位相同。唯一类似于进程层次的暗示是在创建进程的时候,父进程得到一个特别的令牌(句柄),该句柄可以用来控制子进程。但是这个令牌可以被传递给其他进程,这样就没有了层次结构。但是在UNIX中,进程不能剥夺其子进程的“继承权”。
进程的状态
基本进程状态:
- Running:正在使用 CPU
- Ready:可运行的(处于 ready queue 中)
- Blocked:没有外部事件发生时无法运行(例如等待某个按键被按下)
进程状态转换
- Process blocks for I/O(Running->Blocked)
- Scheduler selects another process(Running->Ready)
- Scheduler picks this process to run(Ready->Running)
- Input becomes available(Blocked->Ready)
进程的实现
process table,每个进程都有一个进程表项(也称为PCB,进程控制块)。进程表项的字段包括进程管理、存储管理和文件管理的有关字段。⭐PCB(Process Control Block)
- A data structure in kernel that contains information about the process needed to manage a particular process 内核中的数据结构,包含管理特定进程所需的进程信息
- OS maintains a PCB for each process
- PCB 的结构,不同的操作系统有不同的结构,但是有一些共同的信息
PCB contains
- Process ID
- Process state
- Pointer to parent process
- Priority of a process
- Program counter (PC):指向下一条要执行的指令
- CPU registers,various CPU registers where process need to be stored for execution for running state
- I/O Info I/O status information includes a list of I/O devices allocated to the process
- Accounting information: CPU used, clock time, time limits etc.
Process Context Switch 进程上下文切换
- Switching the CPU to another process, performed by scheduler
- Expensive(1~1000ms),no useful work is done(pure overhead), can be a bottleneck
- need hardware support
步骤包括:
- 保存旧进程的 PCB 状态
- 加载新进程的 PCB 状态
- 刷新内存缓存
- 更改内存映射
线程Thread
为了减小进程切换带来的额外开销,将进程资源分配和调度这两个基本属性分开,把进程调度交给线程执行,让拥有资源的基本单位——进程,不进行频繁的切换。
定义:线程是进程中的执行单元,是操作系统进行调度的最小单位。一个进程可以包含多个线程,它们共享进程的地址空间和资源,但每个线程有自己的执行栈和程序计数器。
特点:线程间的数据共享和通信更为方便,但这也可能导致数据同步和死锁问题。线程的创建、切换开销小于进程。
线程的使用
- 一个或多个线程(进程在创建时一般同时创建好第一个线程,其他线程按需要由用户程序请求创建)
- 线程不拥有系统资源,只有其运行必须的一些数据结构:TCB, a program counter, aregister set, a stack,它与该进程内其他线程共享该进程所拥有的全部资源
- 堆栈和寄存器用来存储线程内的局部变量
- 线程控制块 TCB 用来说明线程存在的标识,记录线程属性和调度信息
⭐线程的实现
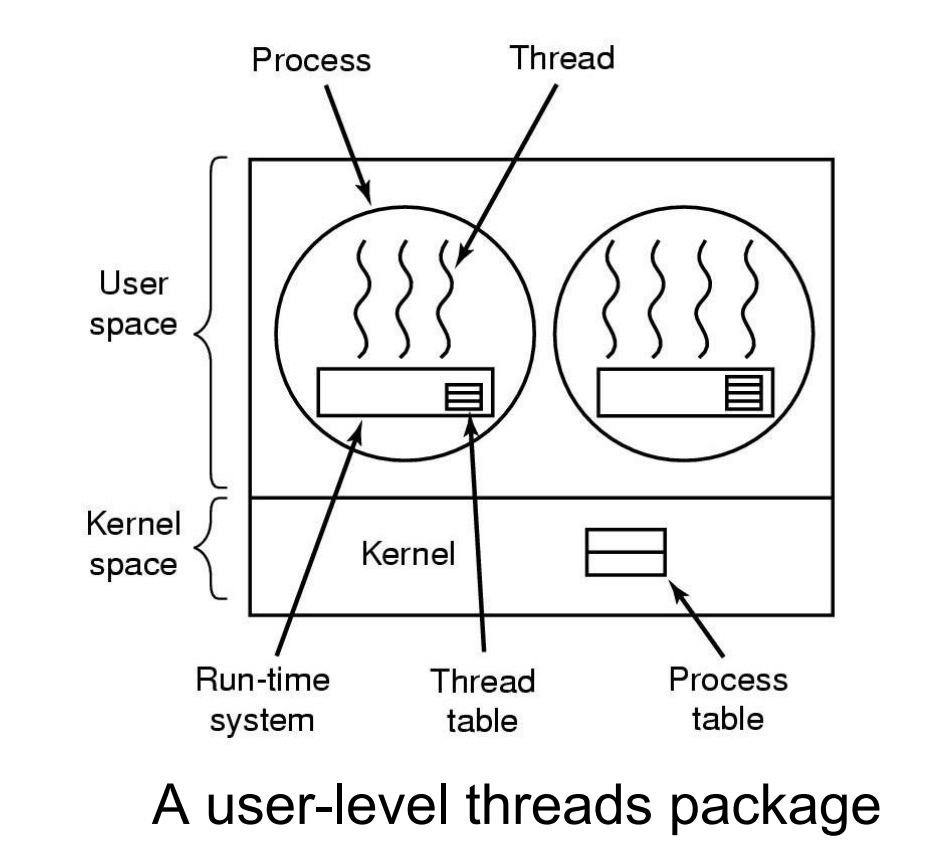
- 用户级线程
- 内核级线程
- 混合实现
在用户空间实现线程User Threads(ULT)
- 完全存在于用户空间,内核不知道线程的存在
- 完全由用户空间进行管理,能实现快速的创建和管理,可以使用
#include<pthread.h>库 - 用户级线程包可以在不支持线程的操作系统上实现
- 每个进程需要一个线程表,用来跟踪该进程的所有线程
- 问题:假如内核是单线程的,如果用户进程的某个线程执行了一个 blocked 的系统调用时,会导致整个进程都 blocked
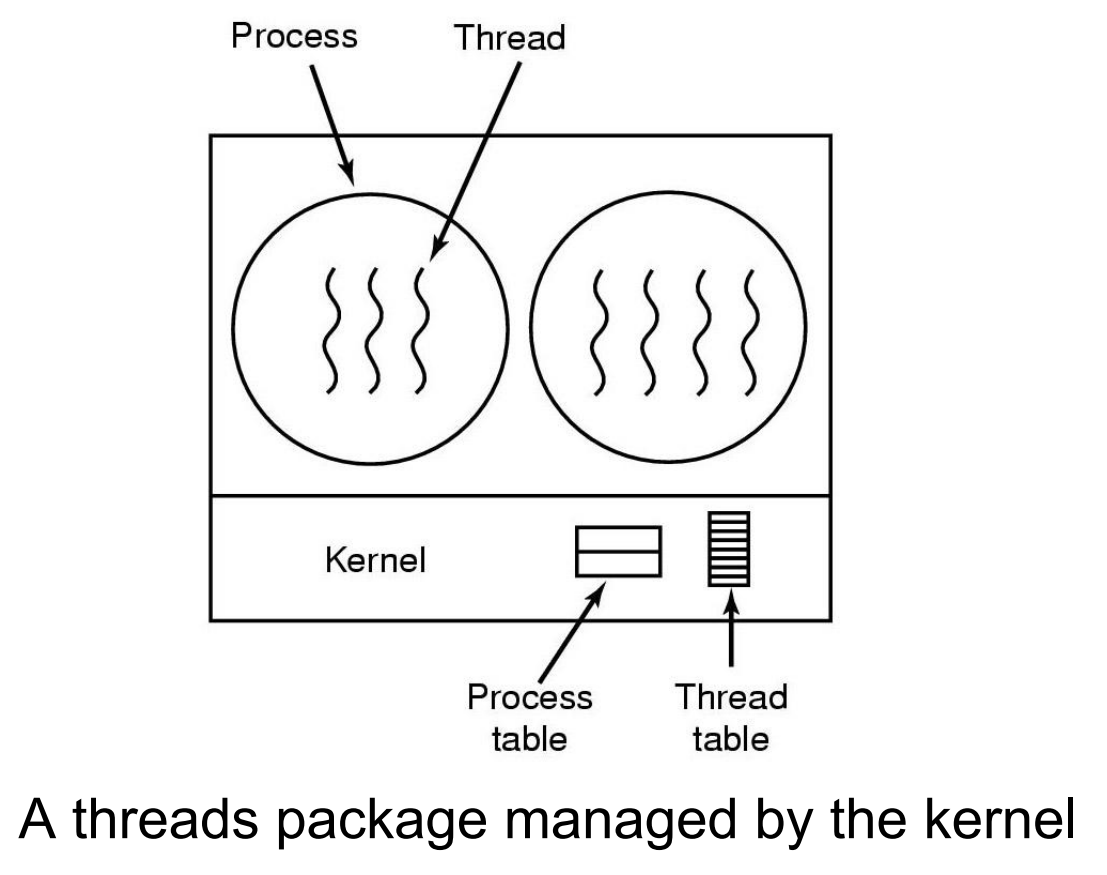
在kernel中实现线程Kernel Threads(KLT)
- 基于内核支持的,由内核控制线程的创建、调度和管理
- 没有 thread library,由内核提供 API
- 内核维护线程和进程的上下文
- 线程的切换需要内核
- 调度的基本单位是线程
- 缺点是高消耗
混合实现

⭐进程和线程比较
- 进程是资源分配的基本单位,所有与该进程有关的资源分配情况,如打印机、I/O 缓冲队列等,均记录在进程控制块 PCB 中,进程也是分配主存的基本单位,它拥有一个完整 的虚拟地址空间。而线程与资源分配无关,它属于某一个 进程,并与该进程内的其它线程一起共享进程的资源。
- 不同的进程拥有不同的虚拟地址空间,而同一进程中的多个线程共享同一地址空间。
- 进程调度的切换将涉及到有关资源指针的保存及进程地址 空间的转换等问题。而线程的切换将不涉及资源指针的保 存和地址空间的变化。所以,线程切换的开销要比进程切 换的开销小得多
- 进程的调度与切换都是由操作系统内核完成,而线程则既可由操作系统内核完成,也可由用户程序进行。
- 进程可以动态创建进程。被进程创建的线程也可以创建其它线程。
- 进程有创建、执行、消亡的生命周期。线程也有类似的生命周期
⭐ipc(Inter-process Communication)进程间通信
Three issues are involved in IPC
- How one process can pass information to another.进程怎么把消息传递给另一个进程
- Resource shared (e.g. printer) 资源的共用(互斥)
- How to make sure two or more processes do not get into each other’s way when engaging in critical activities. (Mutual Exclusion,互斥)
- Process cooperation 进程合作
- Proper sequencing when dependencies are present. (Synchronization) (协调进程的顺序以解决互相依赖或互相等待——进程同步)
临界资源 (Critical Resource):一次仅允许一个进程访问的资源称为临界资源,如硬件中的打印机,软件中的变量、表格、队列、文件。
临界区 (Critical Region 或 Critical Section):程序中的一段访问临界资源的的代码,两个进程不同时在临界区中就能做到不同时访问临界资源
互斥
- Four conditions to provide mutual exclusion 互斥的四个条件:
- 不能有两个及以上的线程同时访问临界区
- 不能对 CPU 的数量和速度做出任何假设
- 在临界区之外运行的进程不能够阻塞其他进程进入临界区
- 不能有进程被一直阻塞于临界区之外
- 互斥的可能实现方法:
- 在一个进程刚进入临界区时,关闭所有中断,然后在即将离开时再开启中断
- 原理:一旦关闭所有中断,包括时钟中断,基于时间片的进程切换也不会发生,也就是在这段时间中这个进程将独占 CPU
- 问题
- 一旦忘记打开中断,系统将瘫痪
- 多 CPU 下,只会影响当前执行进程的 CPU,无法影响其他 CPU
- 应用:通常只用于 OS 内部
Lock Variables
- 对共享变量添加 lock 字段,每个进程访问时查询是否为 0,若为 0 则执行,且把 lock 值置 1,退出执行时置 0,若为 1 则继续不断查询锁的值,直到锁的值为 0。
- 问题
- 问题
- Mutual exclusion: Enter critical section if and only if
- Other process does not want to enter.
- Other process wants to enter, but your turn.
- A process can enter its critical section twice.
- The process running outside its critical region can not block another process.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#
#
#
int turn; /*whose turn is it?*/
int interested[N] /*all values initially 0(FALSE)*/
void enter_region(int process)
{
int other;
other = 1-process;
interested[process]=TRUE;
turn = process;
while(turn == process && interested[other] == TRUE)/*null statement*/
}
/*critical region*/
void leave_region(int process)
{
interested[process] = FALSE;
}

TSL (Test and Set Lock)
- Hardware solution 需要硬件支持的一种方案——TSL(test-and-set lock): 一个原子指令,可以保证在多线程环境下,对共享变量的操作是原子的。在多线程环境下,可以用它来实现互斥。原子地完成了两个操作:
1
tsl register, flag
(a) copy a value in memory (flag) to a CPU register
(b) set flag to 1
use xchg:
- 问题
- 解决忙等待问题的方法是当进程不被允许进入临界区时,让进程进入睡眠(Block)状态,直到满足进入临界区的条件时被唤醒。
- 例如,生产者-消费者问题
- 假设两个进程共享一个可容纳 N 个项目的循环缓冲区。
- 生产者将项目添加到缓冲区,消费者从缓冲区中移除项目。
- 问题
- Semaphores introduced by
E.W.Dijkstrain 1965 to count the number of “wakeups” saved.1
2
3
4struct sem_struct{
int count//资源计数
queue Q//阻塞/等待队列
}semaphores - count 有两种类型,用来表示某种资源的数量,例如有 N 台打印机
- 计数信号量(Counting Semaphores):可以取任意非负整数值
- 二元信号量 (Binary Semaphores):只能取 0 或 1
- 任何信号量操作都是不可分割的,必须原子地执行。
- 信号量有且只有两种操作(两个操作都是原子的):
- P(sem S) or wait(sem S) or down (sem S): used to acquire a resource and decrements count. 申请资源并减少计数
- V(sem S) or signal(sem S) or up(sem S): used to release a resource and increments count. 释放资源并增加计数
- 执行一次P操作后,若 $S.count<0$ ,则 $|S.count|$ 等于Q队列中等待S资源的进程数。
1
2
3
4
5down(sem S){
S.count=S.count-1//
if(S.count<0)
block(P);
} - 执行一次V操作后,若 $S.count≤0$ ,则表明Q队列中仍有因等待S资源而被阻塞的进程,所以需要唤醒(wakeup)Q队列中的进程。
1
2
3
4up(sem S){
S.count=S.count+1;
if(S.count<=0) wakeup(P in S.Q)
}
- 关于信号量的层次和适用场景
- Higher-level synchronization mechanism
- Higher than disabling interrupts.
- Fine for short sequences of code in kernel.
- Not fine for application-level use.
- In conclusion, we use semaphores in two different ways:
- mutual exclusion (mutex);
- process synchronization (full, empty).
- 信号量的使用
- P,V操作必须成对出现,有一个P操作就一定有一个V操作
- 当为互斥操作时,它们同处于同一进程;
- 当为同步操作时,则不在同一进程中出现。
- 如果P(S1)和P(S2)两个操作在一起,那么P操作的顺序至关重要,一个同步P操作与一个互斥P操作在一起时同步P操作在互斥P操作前;而两个V操作的顺序无关紧要。
- 如果缓冲区大小大于 1,就必须专门设置一个互斥信号量来保证互斥访问缓冲区
- 如果缓冲区大小为 1,有可能不需要设置互斥信号量就可以互斥访问缓冲区

- 信号量同步的缺点
- 用信号量可实现进程间的同步,但由于信号量的控制分布在整个程序中,其正确性分析很困难。
- 引入管程(很少考)
• 1973年,Hoare和Hanson提出一种高级同步原语——管程;其基本思想是把信号量及其操作原语封装在一个对象内部。
• 管程是管理进程间同步的机制,它保证进程互斥地访问共享变量,并方便地阻塞和唤醒进程。
• 管程可以函数库的形式实现。相比之下,管程比信号量好控制。消息传递(Message passing)
- 进程间通信的方法:
- 一种同步机制,用于等待所有进程都到达某个点,然后再继续执行

- 使用方法:
- Bounded-Buffer (Producer-Consumer) Problem
- Dining-Philosophers Problem
- Readers and Writers Problem
哲学家就餐问题


读者写者问题

变体
- 两队士兵过独木桥:读写者问题,但两队士兵均为读者
- 定义两个整型变量count1、count2,分别用于计数每组士兵过桥人数,初值都为0。
- 定义两个二元信号量mutex1、mutex2,用于控制对count1、count2的互斥访问,初值都为1。
- 定义二元信号量bridge,用于两队士兵间的互斥,初值为1。
- 该问题的一个变体,称为弱读者偏好,就是在写入器等待期间暂停传入的读者。
Process Scheduling 进程调度
Process Behavior
- CPU 突发(burst):进程需要 CPU 的一段时间被称为 CPU burst
- I/O 突发(burst):进程需要 I/O 的一段时间被称为 I/O burst
进程类型
- CPU 密集型(CPU-bound)进程
- 长 CPU burst,少 I/O waits
- 例如:数据计算,图像处理
- I/O 密集型(I/O-bound)进程
- A new process is created
- The running process exits
- The running process is blocked
- I/O interrupt (some processes will be ready)
- Clock interrupt (every 10 milliseconds)
可抢占式(preemptive) vs 不可抢占式(Non-preemptive)
- 可抢占式:The running process can be interrupted and must release the CPU (can be forced to give up CPU)
- 不可抢占式:The running process keeps the CPU until it voluntarily gives up the CPU
- Non-preemptive algorithms
- Preemptive algorithms with long time periods for each process
Interactive System
- Preemption is essential
Real-Time System
- Preemption is sometimes not needed
调度算法
Properties of a GOOD Scheduling Algorithm: - Fair (nobody cries)
- Priority (lady first)
- Efficiency (make best use of equipment)
- Encourage good behavior (good boy/girl)
- Support heavy loads (degrade gracefully)
- Adapt to different environments (interactive, realtime…)
算法的选择取决于不同系统和不同的侧重点需求
对所有系统都要满足公平(Fairness)、效率(Efficiency)和策略强制执行(Policy Enforcement)
Batch systems
- First-Come First-Served (FCFS)
- Also called FIFO. Process that requests the CPU FIRST is allocated the CPU FIRST.
- 非抢占式
- 用于批处理系统中
- 实现:维护一个 FIFO 队列,新进程入队尾,调度器从头部取出进程运行
- 表现度量:平均等待/周转时间
- 不可抢占
- 不是最优的 AWT(Average Waiting Time)
- 无法并行利用资源:会引起护航效应(Convoy effect),例如只有一个 CPU 密集型和多个 I/O 密集型进程,会导致低 CPU 使用率和 I/O 使用率,因为当 CPU 在执行 CPU 密集型进程时,I/O 密集型需要等待使用 CPU,导致 I/O 设备的空闲,当在执行 I/O 密集型时,CPU 就空闲了。
- Shortest Job First (SJF)
- Schedule the job with the shortest elapse time first
- Scheduling in Batch Systems
- Two types:
- Non-preemptive
- Preemptive
- Requirement: the elapse time needs to know in advance需要事先知道各个进程的周转时间
- Optimal if all the jobs are available simultaneously (provable)
- Gives the best possible AWT (average waiting time)
- Non-preemptive SJF
- 需要所有进程都同时抵达等待调度才能最短,如果不是,可能不是最优的
- Preemptive SJF
- Preemptive SJF Also called Shortest Remaining Time First
- Schedule the job with the shortest remaining time required to complete
- 问题
- Usually preemptive
- Time is sliced into quantum (time intervals)
- Scheduling decision is also made at the beginning of each quantum
- Performance Criteria
- Min Response Time
- best proportionality
- Representative algorithms:
- Round-robin
- Priority-based
- Multi Queue & Multi-level Feedback
- Guaranteed Scheduling
- Lottery Scheduling
- Fair Sharing Scheduling
Round Robin (RR)
- 所有进程轮换执行
Time Quantum时间片长度- Time slice too large
- FCFS behavior 退化为 FCFS
- Poor response time 响应时间差
- Time slice too small
- Too many context switches (overheads) 过多的上下文切换导致开销
- Inefficient CPU utilization CPU 利用率低
- Heuristic: 70-80% of jobs block within timeslice : 70-80%的进程在时间片内会阻塞
- Typical time-slice 10 to 100 ms
- Time slice too large
- 问题
- 没有考虑到进程的优先级
- 频繁的进程上下文切换带来大量的开销
- 如何计算平均周转时间
- Each job is assigned a priority. 每个进程都有一个优先级
- FCFS within each priority level. 在每个优先级内部使用 FCFS
- Select highest priority job over lower ones. 优先选择优先级最高的进程
- Rational: higher priority jobs are more mission-critical. 高优先级的进程更重要
- Problems:
- May not give the best AWT. 可能不会给出最佳的平均等待时间
- indefinite blocking or starving a process. 无限制的阻塞或饿死进程
- Set Priority 关于优先级的设置
- Two approaches 两种方法
- Static (for system with well known and regular application behaviors) 静态
- Dynamic (otherwise) 动态
- Priority may be based on:
- Two approaches 两种方法
- Hybrid between priority and round-robin 优先级和轮转的混合
- Used in scenarios where the processes can be classified into groups based on property like process type, CPU time, IO access, memory size, etc. 用于可以根据进程类型、CPU 时间、IO 访问、内存大小等属性将进程分类的场景。
- Split the Ready Queue in several queues, processes assigned to one queue permanently 将就绪队列拆分为多个队列,进程永久分配给一个队列
- Each queue with its own scheduling algorithm 每个队列都有自己的调度算法
- E.g. interactive processes: RR, background processes: FCFS/SRTF
- Scheduling between queues 在队列之间调度
- 多级队列的变种
- 每个队列都有相同的 CPU 使用率
- 每个进程都从最高优先级的队列开始执行,每执行完一次 CPU burst 就移动到下一个队列(优先级低一级)
- 某个队列中的每个任务都执行固定长度的时间片(RR 调度)
- Multi Queue和Multi-level Feedback
- Guaranteed Scheduling(保证调度, QoS)
- 会给进程以确定的 CPU 时间,例如 n 个运行中的进程,就给每个进程 1/n 的 CPU 时间
- Lottery Scheduling 彩票调度
Real-time systems
- The scheduler makes real promises to the user in terms of deadlines or CPU utilization.
- Schedulable real-time system
- Given $m$ periodic events, event $i$ occurs within period $Pi$ and requires $C_i$ seconds, Then the load can only be handled if $\sum\limits^m{i=1}\frac{C_i}{P_i}\le 1$
Threads
- 可抢占式(preemptable)资源:可以被从一个进程中拿走而不带来负面影响(例如 CPU、内存)。
- 不可抢占式(Nonpreemptable)资源:会导致进程失败如果被拿走(例如 CD 刻录机)。
资源的取用
每个进程会按以下步骤利用资源:

- 请求资源
- 使用资源
- 释放资源
如果请求资源被拒绝就一定要等待,请求资源的进程阻塞,可能会因此 fail with error code
- 进程需要以合理的顺序访问资源
假设一个进程拥有资源 A(例如扫描仪)并请求资源 B(例如 CD 刻录机),与此同时,另一个进程拥有资源 B 并请求资源 A,两者都被阻塞并保持阻塞状态——当进程被授予对设备的独占访问权限(granted exclusive access)时发生死锁
死锁
介绍
- 死锁是指两个或多个进程互相等待对方持有的资源,导致它们都无法继续执行。
- 死锁是一种资源分配问题,当系统中的进程无法继续执行时,就会发生死锁。
死锁的条件
如果四个条件同时成立,则会出现死锁 - 互斥条件:资源被分配给了一个进程或者是可用的
- 持有且等待条件:持有资源的进程还可以额外请求资源
- 不可抢占条件:资源必须是不可抢占的
- 环路等待条件:两个及以上的资源被环路请求资源
死锁的判断
- 图上没有环>>>没有死锁
- 图上有环且每个资源只有一个实例>>>有死锁
- 图上有环但是资源有不止一个实例>>>可能有可能没
资源分配图

死锁的处理
- 忽略问题,假装系统中永远不会发生死锁
- 允许系统进入死锁状态,然后恢复。
- 检测和恢复
- 确保系统永远不会进入死锁状态
- 假装没有问题,如果
- 允许系统进入死锁状态
- 定期运行死锁检测算法
- 检测到死锁后,运行恢复算法
Detection with One Resource of Each Type 每种资源只有一个实例

(拓扑排序)
- 初始化一个空链表,把所有边初始化为未标记
- 将当前节点添加到 L 的末尾,并检查 L 中是否出现了这个节点两次,如果出现,则图中包含一个循环,算法中止
- 从给定的节点,查看是否有任何未标记的出边,如果有,转到步骤四,没有,转到步骤五
- 随机选择一个未标记的出边标记它,然后沿这条边到下一个节点,重复步骤 2
- 现在进入了死胡同,将其移出并返回到前一个节点,使其称为当前节点,然后转到步骤三,如果这个节点是初始节点,则图中不包含循环,算法中止
Detection with Multiple Resources of Each Type 每种资源有多个实例
- 初始化时,所有进程都是未标记状态
- 找一个未标记的进程$P_i$,使得需求矩阵中的第$i$行中的每一项都小于等于可用矩阵每一项的值
- 如果找到了这样一个进程,就把分配矩阵中的第$i$行全部加回到可用矩阵$A$中。标记这个进程,回到第二步。
- 如果没找到,剩下的所有未标记的进程都将陷入死锁,
分配矩阵
- $resources\;in\;existence:E=(E_1,E_2,…,E_M)$
- $c{ij}$表示第$i$个进程已经被分配了$c{ij}$个$E_j$资源
需求矩阵
- $resource\;available:A=(A_1,A_2,…,A_m)$(可用资源矩阵)
- $Am=E_m-\sum\limits^n{i=1}c_{im}(exist的减去已分配的)$
- $R{ij}第i个进程需求R{ij}个R_j资源$
死锁的恢复
考过简答题
- 重启
- 杀死进程
- 回滚
- 什么都不做
抢占的方法(Preemption)
- 出现死锁的时候从别的进程抢占资源
- 但是这种方法能否可行取决于资源的类型
回滚的方法(rollback)
- 周期性的在进程中设立检查点
- 当出现死锁的时候,从检查点开始恢复
杀死进程的方法(kill processes)
- 杀死一个死锁环中的进程
- 杀死的进程应当是一个能从头开始重新运行而不带来负面影响的。
避免死锁(Avoidance)
死锁避免算法动态地检查资源分配状态,以确保永远不会出现循环等待的情况。 - 要求系统有一些额外的先验信息可用。
- 最简单、最有用的模型要求每个进程声明它可能需要的每种类型的最大资源数量
- 避免死锁的算法是基于安全状态的。
Safe and Unsafe States
- 如果某个状态不是死锁,并且有办法通过按某种顺序运行进程来满足所有待处理的请求,则该状态是安全的。
- 如果所有进程都存在安全的顺序,则系统处于安全状态。
- 当进程请求可用资源时,系统必须决定立即分配是否会使系统处于安全状态。
示例: - safe
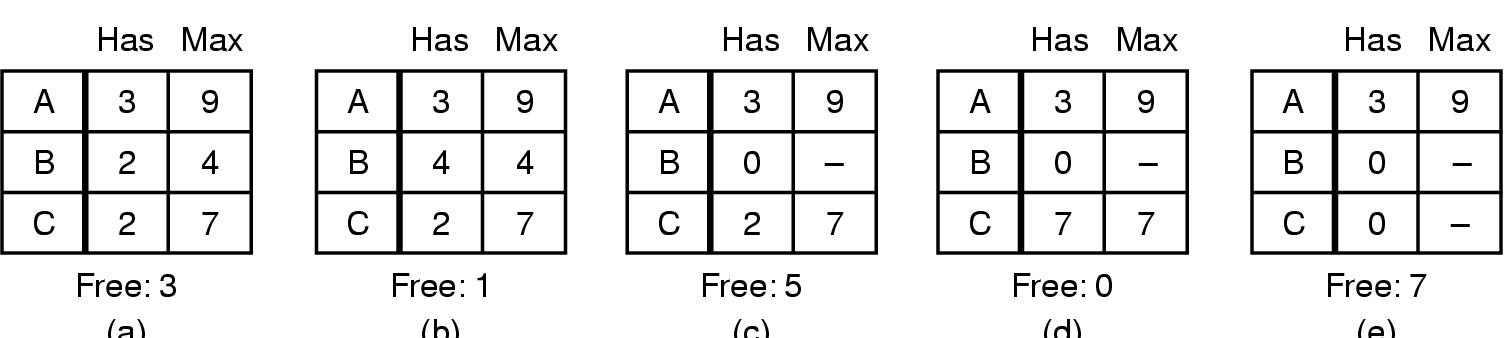
- unsafe

- 如果系统处于安全状态 >>> 没有死锁。
- 如果系统处于不安全状态 >>> 可能出现死锁。
- 死锁避免 >>> 确保系统永远不会进入不安全状态。
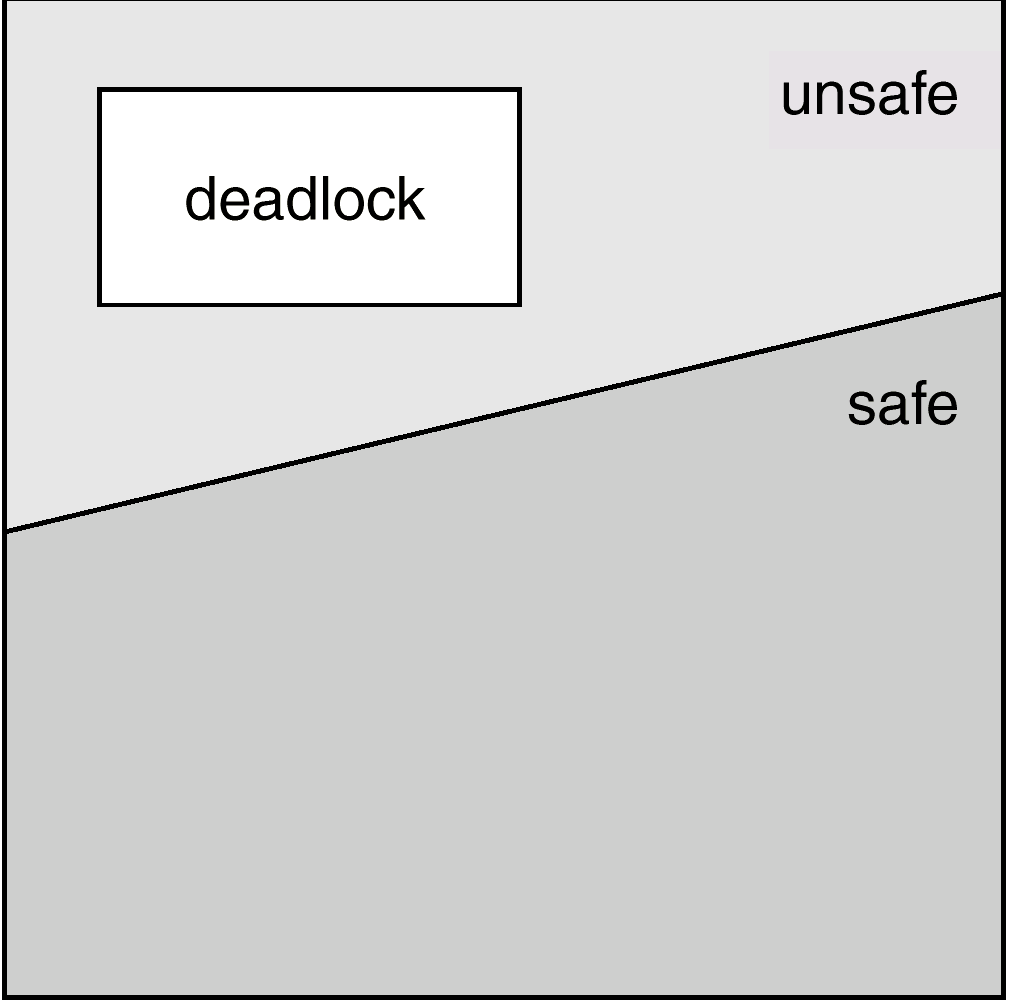
银行家算法 bank algorithm
- 每个客户告诉银行家其所需的最大资源数量
- 客户从银行家借入资源
- 客户将资源归还给银行家
- 客户最终偿还贷款
- 银行家仅在贷款后系统处于安全状态时才借出资源
- 安全状态 - 存在借贷顺序,使得所有客户都可以贷款
- 不安全状态 - 存在死锁的可能性
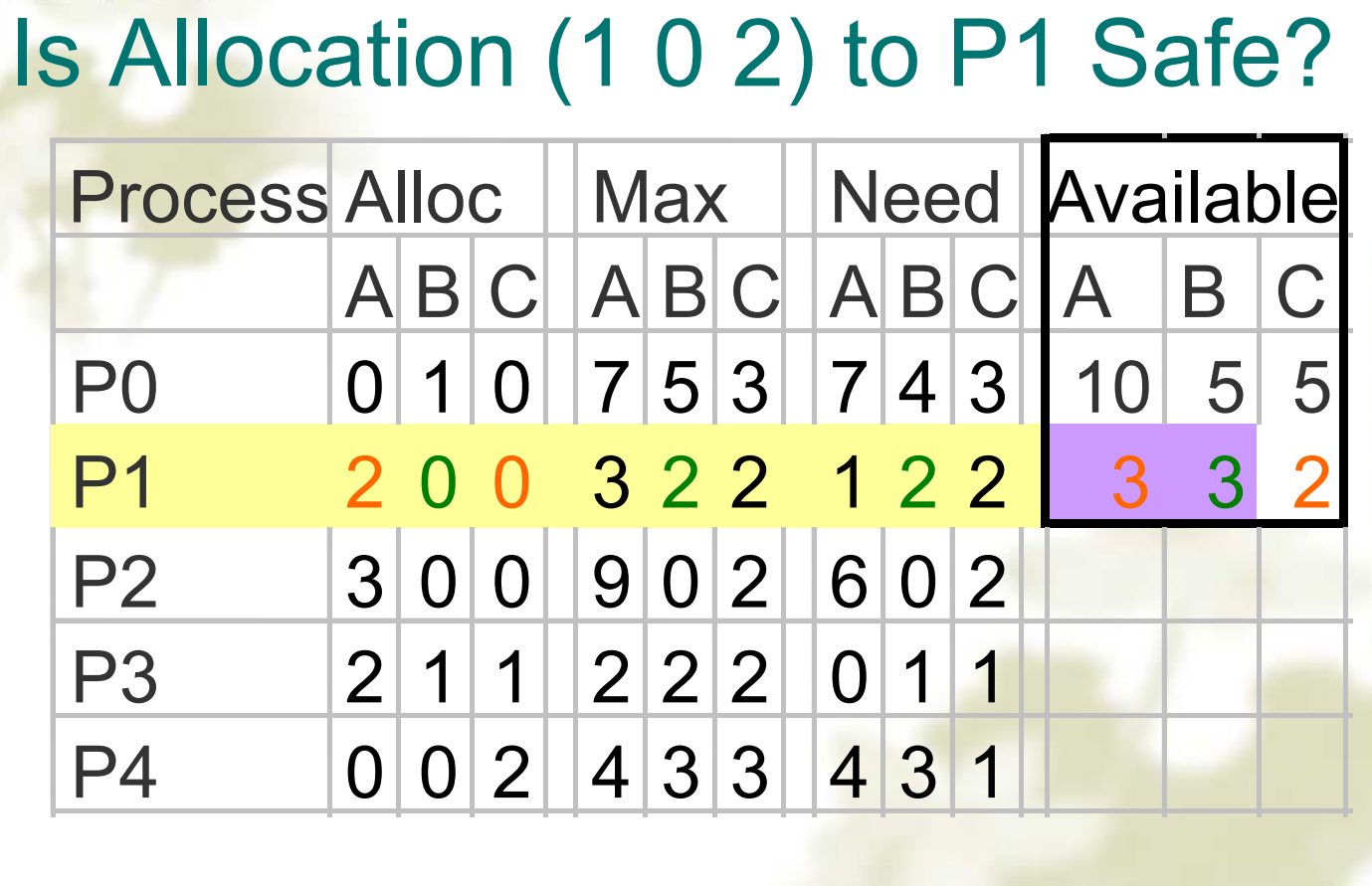
矩阵列:alloc、max、need、available。
首先计算出need矩阵。
进程p完成的时候,把 alloc 列中的资源还给了available ,然后判断是否有进程可以完成,如果有就继续,没有就说明发生了死锁。
用文字方式描述:
检查状态是否安全:
- 在 R 中寻找小于A 的新行。如果不存在这样的行,系统将最终死锁 ==> 不安全。
- 如果存在这样的行,则该过程可能完成。将该过程(行)标记为终止并将其所有资源添加到 A。
- 重复步骤 1 和 2,直到所有行都标记为 == > 安全状态或未标记 == > 不安全。
单一资源实例的银行家算法
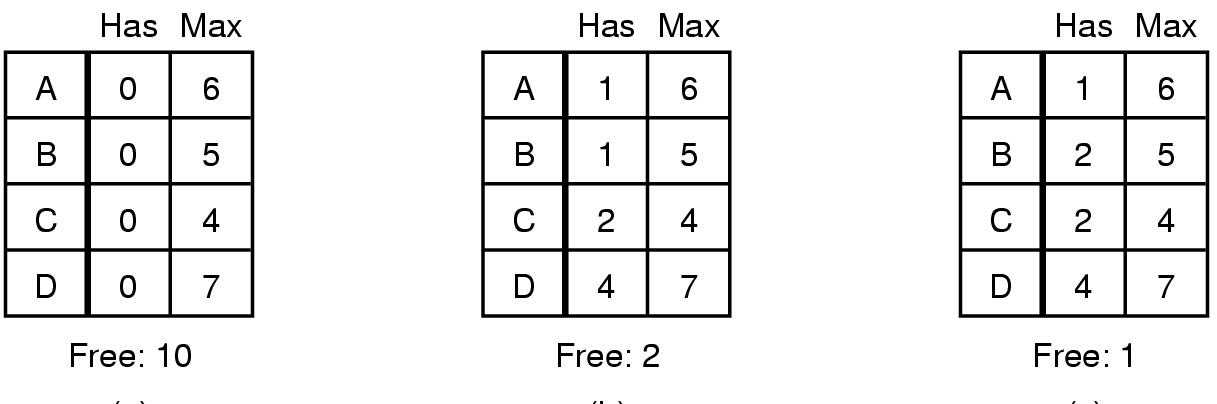
(a) safe
(b) safe
(c) unsafe多个资源实例的银行家算法
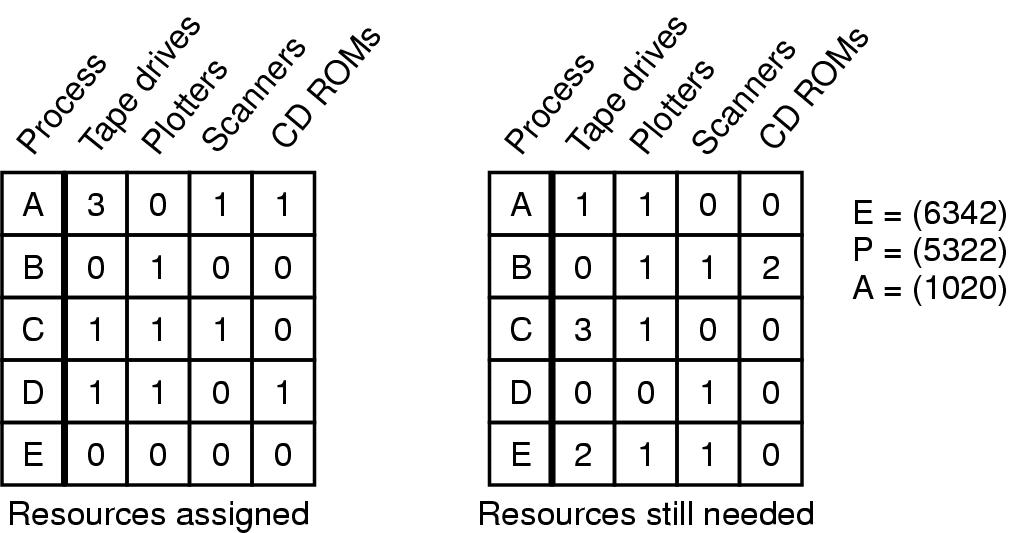
银行家算法的问题
- 银行家算法比较保守,为了安全起见,它降低了并行性
不太实用
Mutual Exclusion:Spool everything. 这意味着将所有资源都放入一个缓冲池(Spool)中,让每个进程在需要时从池中取用,用完后再放回。这样,资源就可以被多个进程共享,从而破坏了互斥条件。
- 某些设备(如打印机)可以假脱机,并非所有设备都可以假脱机
- 只有打印机守护程序使用打印机资源
- 打印机守护程序不请求其他资源,因此消除了打印机死锁
- 假脱机空间有限,因此使用此决定仍然可能出现死锁
- 两个进程各自占满一半可用空间,无法继续,因此磁盘上出现死锁
- 如果不是绝对必要,请避免分配资源, 尽可能少的进程实际占用资源
Spooling(Simultaneous Peripheral Operations On-Line)是一种数据管理技术,主要用于打印等I/O操作。其基本原理如下:
当一个进程需要打印数据时,它不直接发送数据到打印机,而是将数据写入到一个磁盘文件中。这个文件通常被称为”spool”或”spool file”。
打印机守护进程(printer daemon)会监视这些spool文件。当它发现有新的spool文件时,它会从文件中读取数据,并发送到打印机。
打印机守护进程和打印机之间的通信通常是异步的。也就是说,打印机守护进程发送数据后,不需要等待打印机完成打印,就可以开始处理下一个spool文件。
通过这种方式,多个进程可以同时”使用”打印机。实际上,它们是在向磁盘文件中写入数据,而打印机守护进程负责将这些数据发送到打印机。这就是Spooling的基本原理。
Hold and Wait:Request all resources at once. 这意味着进程在开始执行前,一次性请求所有需要的资源。这样,进程就不会在执行过程中持有一部分资源并等待其他资源,从而破坏了占有并等待条件。
- 要求进程在启动前请求所有资源
- 进程永远不必等待它需要的东西
- 问题
- 在运行开始时可能不知道所需的资源
- 还占用其他进程可能使用的资源
- 变化:
- 请求资源的进程必须放弃当前拥有的所有资源,然后请求所有立即需要的资源
No Preemption:Take resources away. 这意味着操作系统可以强行从一个进程中取走其占有的资源,然后分配给其他进程。这样,就破坏了非剥夺条件。
- Virtualization of Resources
- Spooling printer output to the disk
- Allow only the printer daemon access to the real printer.
- Problem
- Not all resources can be virtualized
- Virtualization of Resources
Circular Wait:Order resources numerically. 这意味着将所有资源进行编号,每个进程都按照编号顺序请求资源。这样,就不会形成循环等待,从而破坏了循环等待条件。
- Approach 1: Request one resource at a time.
- Release the current resource when request the next one
- Approach 2: Global ordering of resources
- Requests have to made in increasing order
- Approach 3: Variation of Approach 2
- No process request a resource lower than what it is already holding.
- Problem:
- Approach 1: Request one resource at a time.
- Two-Phase Locking 两阶段锁定
- Communication Deadlocks 通信死锁
- Livelock 活锁
- Starvation 饥饿
两阶段锁定 Two-Phase Locking
- 第一阶段
- 进程尝试锁定它需要的所有记录,一次一个
- 如果发现需要的记录被锁定,则重新开始
- 如果第一阶段成功,则开始第二阶段,
- 执行更新
- 释放锁定
- 注意与一次请求所有资源的相似性
- 算法在程序员可以安排的地方工作
- 程序可以停止,重新启动
两阶段锁定协议(Two-Phase Locking Protocol)是一种并发控制方法,用于确保事务的隔离性和一致性。
- 两阶段锁定协议分为两个阶段:增长阶段(Growing Phase)和缩减阶段(Shrinking Phase)。
- 在增长阶段,事务可以获取锁,但不能释放锁;在缩减阶段,事务可以释放锁,但不能获取锁。
- 两阶段锁定协议可以防止死锁,但不能防止饥饿。
通信死锁 Communication Deadlocks
- 通信死锁是指在分布式系统中,由于通信通道的限制或者通信协议的问题,导致进程之间无法正常通信,从而陷入死锁状态。
- 通信死锁的原因包括:通信通道的限制、通信协议的问题、通信消息的丢失、通信消息的延迟等。
- 避免通信死锁的方法包括:超时重传等。
活锁 Livelock
- 活锁(Livelock)是指系统中的进程或线程由于某种原因一直在忙碌地执行,但无法取得进展,从而无法完成任务。
- 活锁通常是由于进程之间的竞争条件、资源争用、消息传递等问题导致的。
- 死锁:进程被阻塞
- 活锁:进程运行但没有进展
- 轮询(忙等待),用于进入关键区域或访问资源,可能导致活锁
饥饿 Starvation
- 分配资源的算法
- 可能首先分配给最短的任务
- 非常适合系统中的多个短任务
- 可能导致长任务无限期推迟即使没有被阻止
解决方案:
- 先到先得政策
饥饿(Starvation)是指系统中的进程或线程由于某种原因无法获得所需的资源,从而无法继续执行任务。
- 饥饿通常是由于资源分配不公平、资源争用、优先级反转等问题导致的。
总结
- 一般而言,死锁检测或避免的成本很高
- 必须评估死锁成本与检测或避免成本
- 死锁避免和恢复可能会导致无限期推迟
- Unix 和 Windows 使用鸵鸟算法
chapter 3 Memory Management
Storage Hierarchy
- Registers
- Cache
- Main Memory
- Magnetic Disk
- Magnetic tape
Memory Management Schema 内存管理模式
No Memory Abstraction
- Every program simply saw the physical memory 所有程序必须硬编码硬件物理地址
- It is not possible to run two programs in memory at the same time. 内存中不可能同时运行两个应用程序
static relocation 静态重定位
- 通过修改程序的地址来适应不同的内存地址
- Modify addresses statically when load process.
- Example: two programs, each is 16KB
- 28+16384=16412
- Advantage
不需要硬件支持 - Disadvantages
- Protection
- -How does the system prevent processes interfering with each other? 如何防止进程相互干扰?
- Relocation
- -How does a task or process run in different locations in main memory? 任务或进程如何在主存储器的不同位置运行?
为了解决这两个问题,引入了地址空间(Address Space)的概念。Address Space 指的是一组能被一个进程所使用的内存地址。
- -How does a task or process run in different locations in main memory? 任务或进程如何在主存储器的不同位置运行?
- 每个进程都有自己的地址空间,独立于其他进程的地址空间。
- Logical address space, range (0 to max)
- Logical addresses, Virtual addresses
- Logical address space, range (0 to max)
- Address Binding 地址绑定
- Protection & Relocation: base and limit register
Dynamic Relocation 动态重定位
- 将每个进程的地址空间映射到物理内存的不同部分。
- 物理地址空间,基值 R 的范围(R+0 到 R+max)
- 物理地址,实地址
- 需要硬件支持:为 CPU 配备两个特殊硬件寄存器:base and limit registers
- base 寄存器:地址空间的起始位置
- limit 寄存器:地址空间的大小限制


- 优点
- 操作系统可以在执行时简单地移动进程
- 操作系统可以动态地改变进程的大小(通过改变 limit register 或者移动位置)
- 简单,硬件速度块
- 缺点
- 程序很多,总大小超出内存
- Swapping:将整个进程放入内存,运行一段时间,然后将其移回磁盘。
- Virtual memory:即使程序只有部分在主内存中,也可以运行。
- 交换允许多个进程共享一个分区
动态分配内存
- 当一个进程到来时,如果有足够的空间,则按其需求分配空间;或者进程在磁盘上等待;
- 在不断的换进换出中未被使用的内存,会带来大量的
holes(外部碎片,External Fragmentation), the holes need be compacted together to generate a large free space.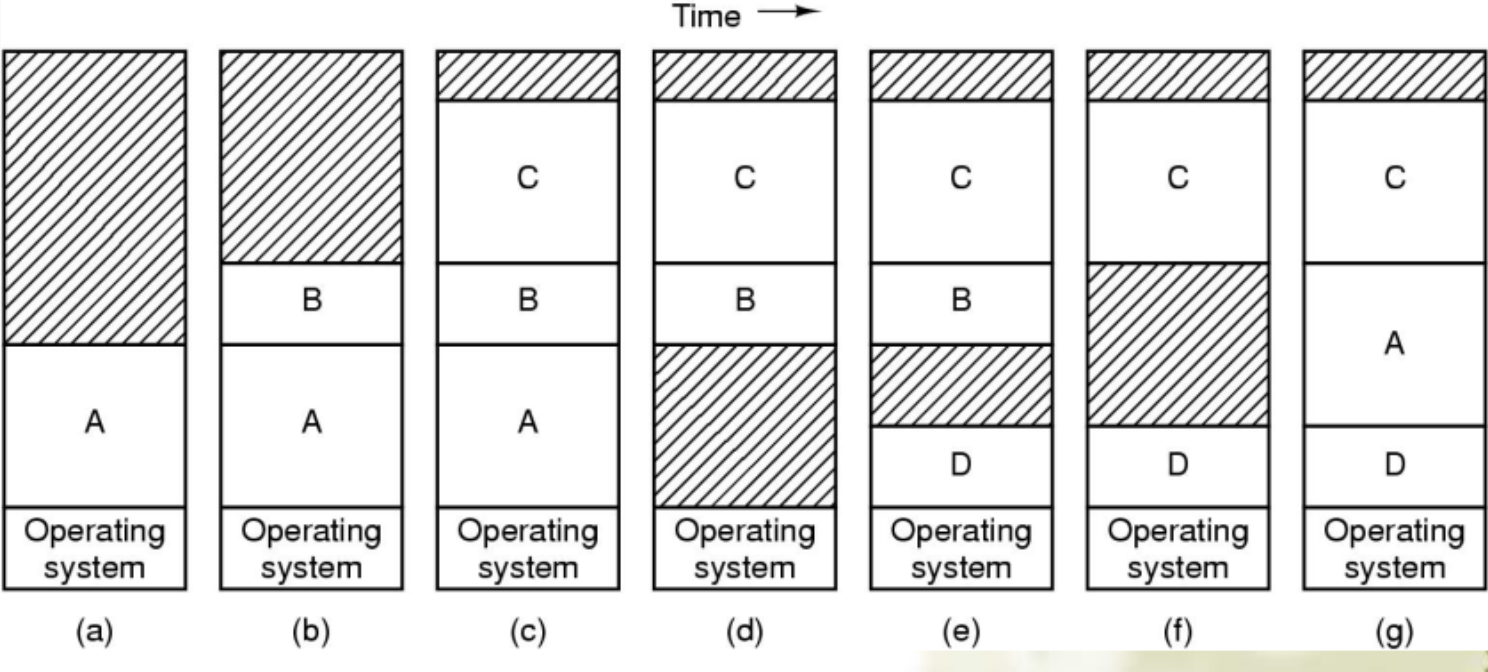
- 如果大多数进程在运行时会增长怎么办?
- 如何跟踪内存使用情况?
- 位图或链表
- 内存被划分为分配单元。
位图
- 一个分配单元对应位图中的 1bit
- 0: 空闲,1:已分配
- 分配单元的大小
- 分配单元越小,位图越大。
- 问题:分配
- 每个链表项表示一个 hole(连续的空闲段)或者一个进程(已分配的端),包括这个段的大小和指向下个 entry 的指针。
- 可以单独维护一个空闲链表来节约查找时间
- 有按大小和按地址排序这两种方式
- 按地址排序的优点是当一个进程终止或被换出时,可以线性地向前更新链表。
这句话讲述的是在操作系统中,进程管理和内存管理的一个具体策略:按地址排序的方式来组织进程或内存块的链表。
按地址排序:指的是在进程的链表或内存块的链表中,元素(进程或内存块)是根据它们在内存中的地址顺序来排列的。这意味着链表中的每个元素的地址都小于其后继元素的地址。
优点:当一个进程终止或被换出(即从内存中移除以便为其他进程腾出空间)时,操作系统需要更新内存管理的数据结构,以反映内存的新状态。如果进程或内存块是按地址排序的,那么这种更新可以更加高效地进行。因为在这种情况下,操作系统只需要从被终止或换出的进程(或内存块)的位置开始,线性地向前(或向后)遍历链表,直到找到相应的位置进行更新。这种方法简化了内存空间的合并和分配过程,因为相邻的空闲内存块更容易在物理地址上相邻,从而更容易合并。
Partition Allocation:
Storage Placement Strategies
- 按地址排序的优点是当一个进程终止或被换出时,可以线性地向前更新链表。
- First fit:每次遍历都从链表头开始,遇到一个可用的就分配,但是会产生一些新的 holes(average)
- Next fit:每次遍历都从上次分配的位置开始遍历,遇到一个可用的就分配,但是比 First Fit 的表现还稍差一点。
- Best fit: 分配时分配冗余量最少的内存空间,但是可能会带来一些无法使用的外部碎片分配时分配冗余量最少的内存空间,但是可能会带来一些无法使用的外部碎片
- Worst fit: 分配时直接分配最大的空间,但是会导致大空间可能分配给了小程序,导致大程序运行不了。
- Quick fit:维护一个索引表,把一些大小范围内的空间用一个索引串起来,当有放置请求时,它会找到最接近的匹配。但是因为这些内存空间往往不连续,所以合并的复杂度高。
Overlaying 覆盖段
- 程序的内存中有一部分被分配为覆盖段,当程序执行时,将外存中的其他覆盖段按需覆盖到内存的覆盖段中
- 允许内存中同时存在一个或多个覆盖,多个覆盖可以使用公共内存空间。
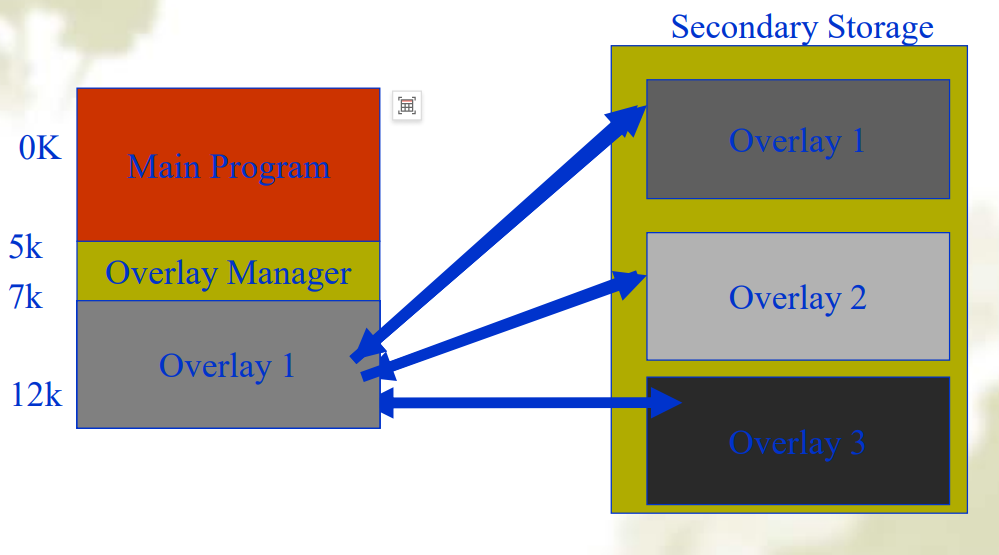

- 覆盖段的切换是由操作系统完成的,但是覆盖段的划分要由用户划分。增加了编程的复杂性。


Virtual Memory
- Principal
- 局部性原理
- 时间局部性:数据被访问后大概率在时间局部范围内还会被访问
- 空间局部性:数据被访问后其前后的的数据也会大概率被访问
- 局部性原理
- Implementation: Paging, Segmentation with paging
Paging 分页
- the virtual address is divided up into units. Its size is power of 2, e.g. 512 bytes –64KB
- 通过 MMU(Memory Management Unit)来把一个虚拟地址映射到物理地址


Page tables
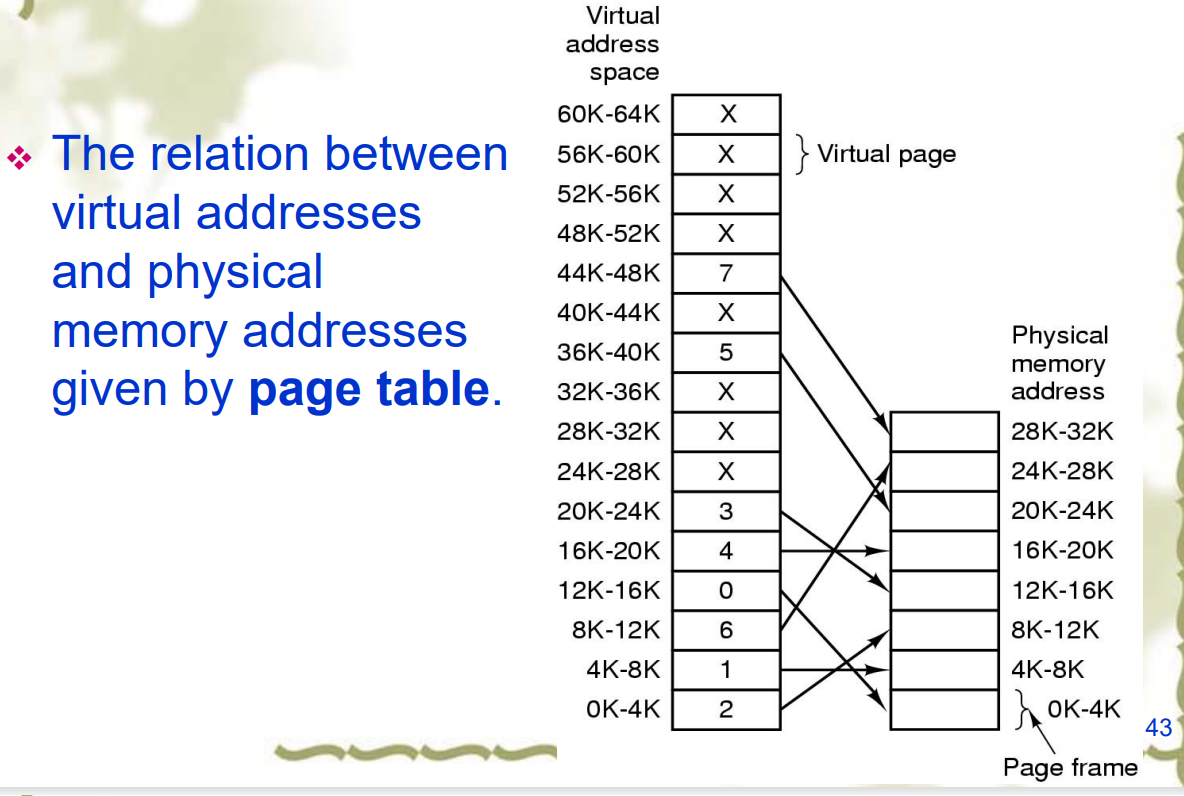
- 用来从虚页映射到页帧(主存中)
- 由虚页号(高位)和页内偏移量(低位)决定
- Page number 虚页号: Used as an index into the page table
- 逻辑地址空间$2^m$
- 页大小为$2^n$,也就是offset 页内偏移量位数d为$n$;
- 页表大小为$2^{m-n}$,也就是虚页号p为$m-n$位
- 物理地址分为
- 帧号
- 页面偏移量
- 页表的作用是将虚拟页面映射到页框上。
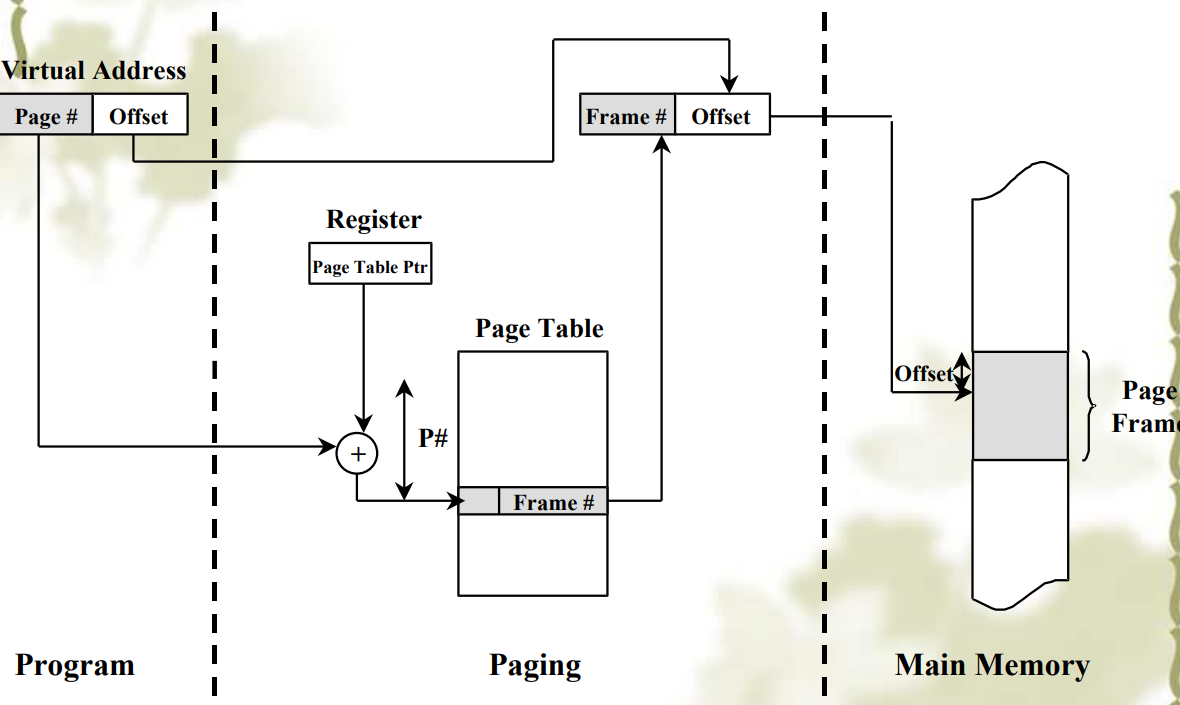
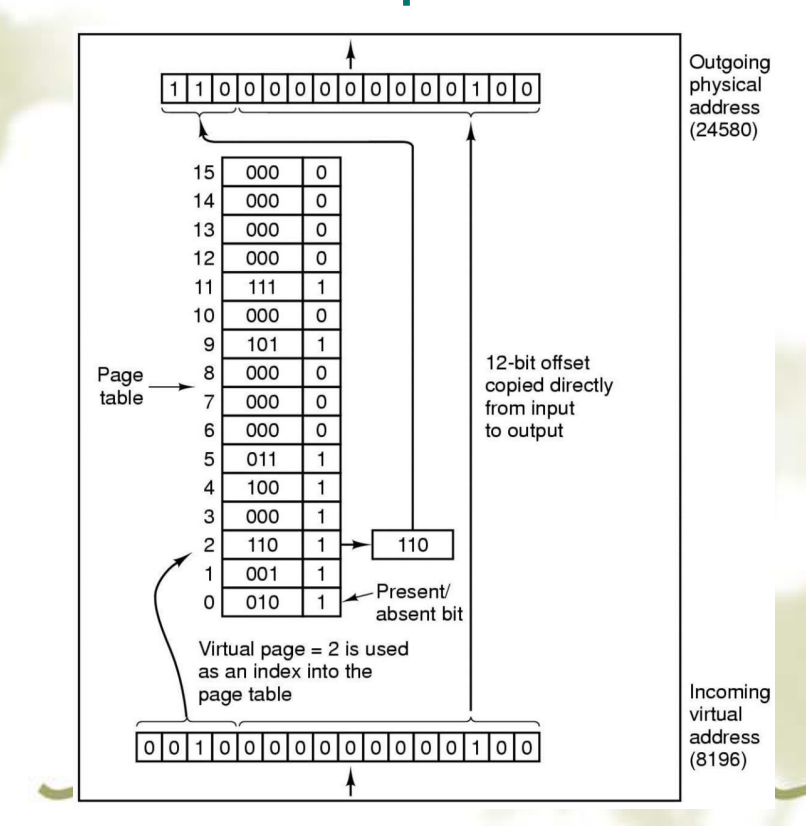
- 将 VPN(虚页号)映射到 PFN
- VPN 是确定 PFN 的表的索引
- 虚拟地址空间中每页一个页表条目 (PTE),即每个 VPN 一个 PTE。
- 大多数操作系统为每个进程分配一个页表。
- 页表项中具体还有其他的字段,如下图:
- 页面帧号 - 映射帧号
- 存在/不存在位 - 1/0 表示有效/无效条目
- 保护位 - 允许哪些类型的访问。
- 修改位(脏位) - 修改并写入磁盘时设置
- 引用位 - 引用页面时设置(帮助决定驱逐哪个页面)
- 缓存禁用 - 缓存用于将逻辑上属于磁盘的数据保存在内存中以提高性能

- 问题
- 需要尽可能快地进行映射,因为每次内存访问都需要用 page table 进行映射
- page table 可能很大
TLB
- cache “active” part of page table 把 page table 活跃的部分缓存到 TLB 中,提高访问速度
- Translation Look-aside Buffers (TLBs)
- TLB also called “associative memory
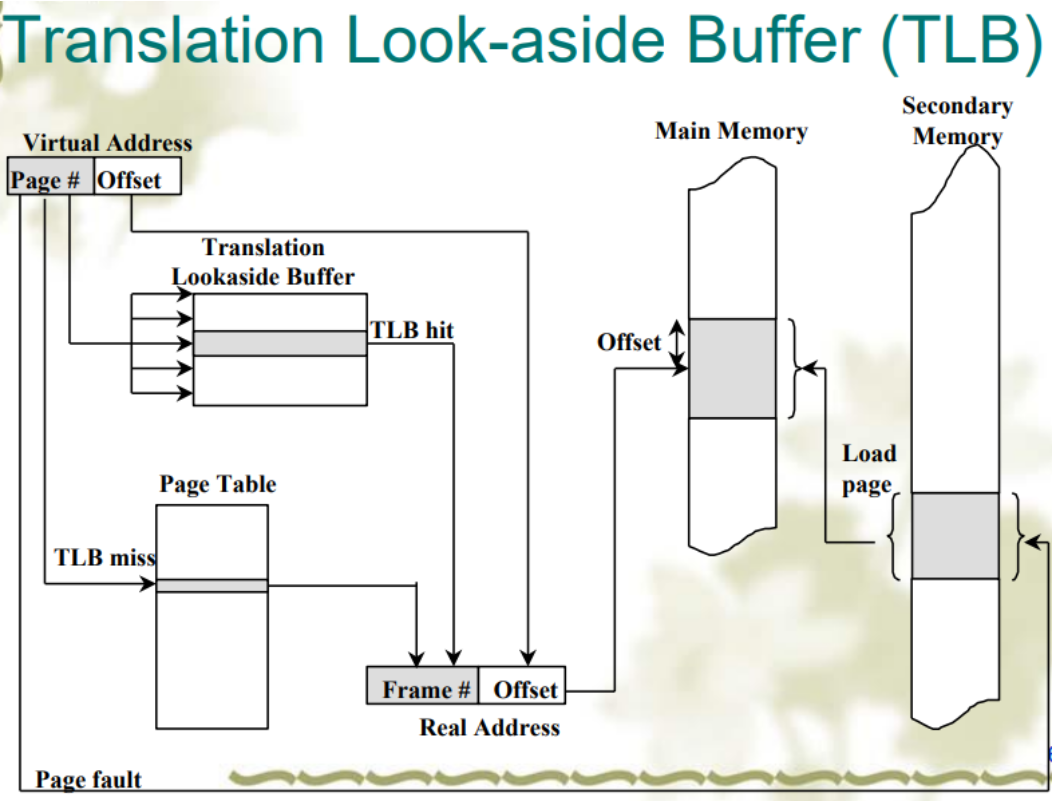
software-controlled TLB

hardware-controlled TLB

又被称为相联存储器(associated memory),是基于内容而不是索引进行访问,而且由于硬件特性,可以并行比较Multi-level page tables 多级页表
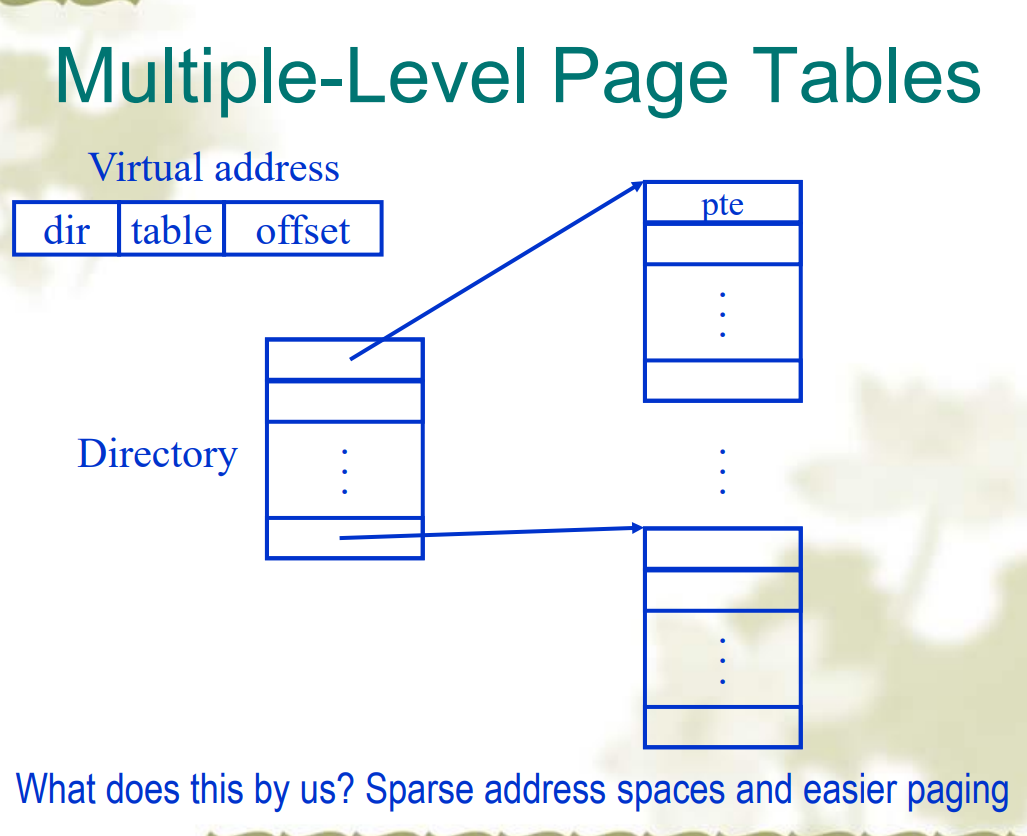
- 为了解决页表过大的问题,可以使用多级页表
- 可以减少表的大小,而且内存可以只保存部分需要的页表,但是减慢了内存访问的速度。
- 页表分为多个级别,每个级别的页表只包含下一级页表的地址
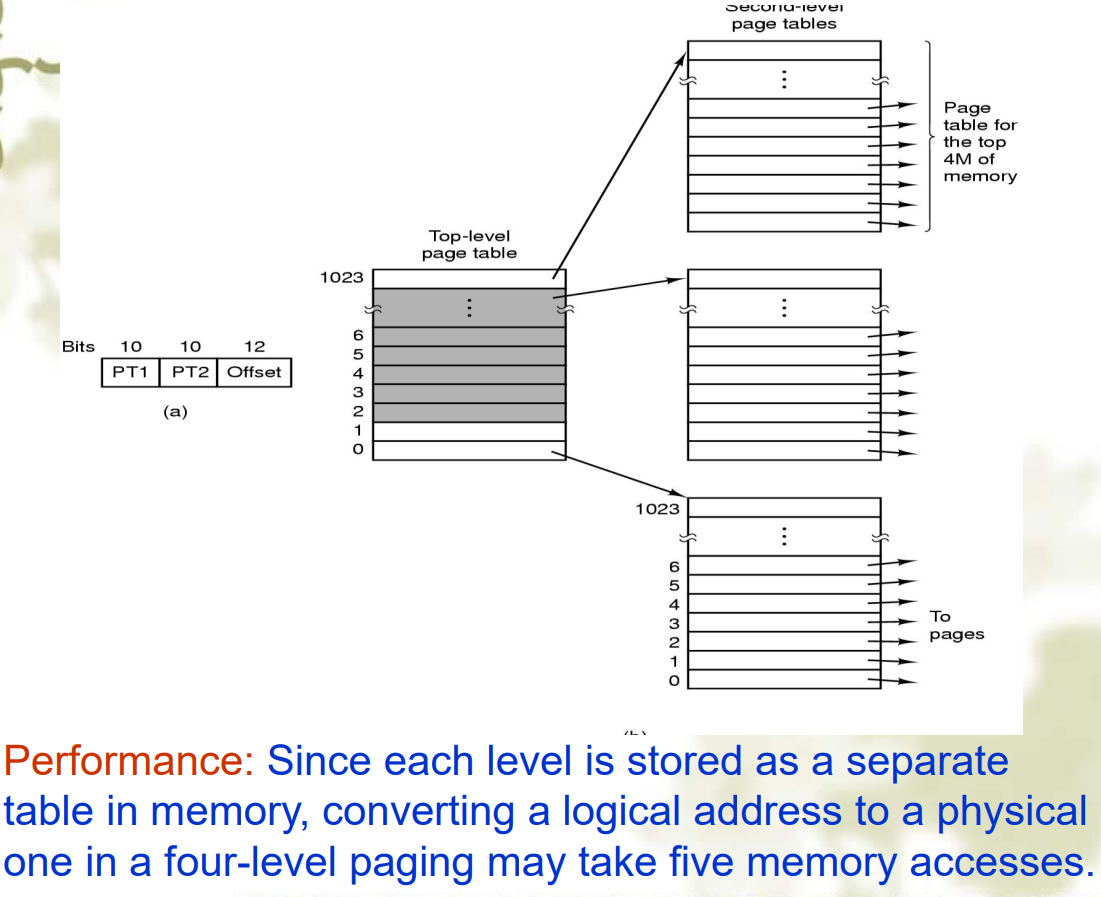
Inverted page tables 倒排页表

- 为了解决页表过大的问题,可以使用倒排页表
- 倒排页表是一个全局的页表,每个页表项包含了虚拟地址和物理地址的映射
- 物理页框索引:在倒排页表中,表的每一项代表一个物理页框,而不是虚拟页。每个条目包含了映射到该物理页框的某个虚拟页的信息(如虚拟地址和相关进程标识符)。
- 储存的是每个物理页框的信息,因为物理内存大小往往远小于虚拟内存,因此能节约空间,好处是可以用较小地页表获得一个较大地地址空间,缺点是难以查找,哈希表项的链表可能过长
- 倒排页表的缺点是查找速度慢,因为需要遍历整个页表来查找一个页表项
- 倒排页表的优点是节省内存,因为不需要为每个进程分配一个页表,而是为所有进程共享一个页表

7JJK_3ALVY}W9[BX`7%MXJ.png>)
线性倒排页表
- 优点
- 大地址空间,小页表
- 缺点
- 优点
- 使用良好的哈希方案和与物理内存大小成比例的哈希图,时间复杂度为 O(1)。非常高效!
- 缺点
- A Present/Absent bit keeps track of whether or not the page is mapped.
- Reference to an unmapped page causes the CPU to trap to the OS.
- This trap is called a Page fault. The MMU selects a little used page frame, writes its contents back to disk, fetches the page just referenced, and restarts the trapped instruction.
5.(B) Which of the following statements is true?
A. The use of a TLB for a paging memory system eliminates the need for keeping apage table in memory.
B. External fragmentation can be prevented by frequent use of compaction, but thecost would be too high for most systems.
C. The first fit allocation algorithm often creates small holes that can’t be used
D. More page frames always have fewer page faultsPage Fault 处理
- 硬件陷入内核,PC 保存到栈中
- 保存通用寄存器
- 操作系统决定用到的虚页
- 操作系统检查虚页地址的有效性,寻找 page frame
- 如果找到的 frame 是 dirty,写硬盘,暂时中断进程
- 操作系统从硬盘中加载一个 page,进程仍然中断
- 硬盘发出中断,页表更新
- 指令从 Page fault 的地方开始恢复
- Page fault 的进程开始调度
- 恢复寄存器
- 程序继续运行
Page Replacement Algorithm
- Fetch Strategies
- Replacement Algorihm
- Clean policy
- Paging in OS
Fetch Strategies
Demand Fetching: 该算法只有在需要的时候才会把 page 换入主存中
- steps
- 出现 page fault
- 检查虚存地址是否有效,如果是无效地址则 kill the job
- 如果有效,就检查内存中有没有这个页,如果有就跳到第七步
- 找到一个可用的页帧
- 把地址映射到磁盘的块上,然后把磁盘的块换入到页帧中,中止用户进程
- 当硬盘读完后,添加虚存到这个页帧的映射表项
- 需要的话,重启进程
Prepaging: 该算法提前把 page 换入主存中
- 当出现 page fault 并把页换入主存时,把它邻近的页一起换入主存中
- 优点是可以提高 I/O 效率
- 缺点是这个算法是需要预测的,如果 fetch 的 page 几乎没有被使用,反而效率降低了
- 常用在程序刚开始时,一次载入大量 page
Replacement Algorithm
steps
FIFO (First In, First Out):先进先出算法,最简单的页面置换算法,按照页面进入内存的顺序进行置换,最早进入内存的页面将最先被置换出去。
Second Chance:改进的FIFO算法,给每个页面一个机会(标志位)来避免被置换。如果页面被访问(标志位为1),在它到达队列头部时会得到“第二次机会”,标志位清零并放到队列末尾。
Clock:也称为时钟算法,是Second Chance算法的一种实现,通过一个循环队列(时钟)来模拟,使用一个指针指向最老的页面,根据页面的访问位决定是否置换。
- 就是把 Second Chance 算法中的链表改成了环形链表
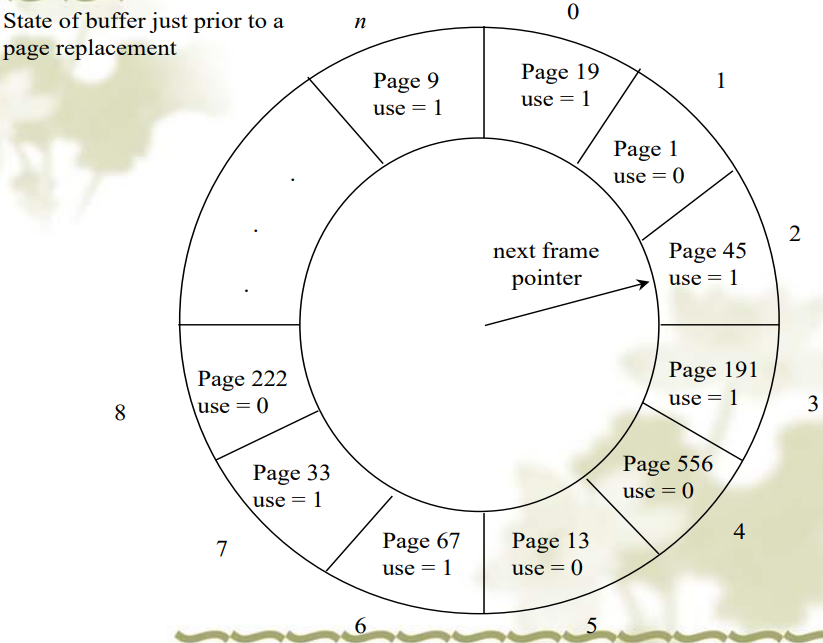
- 就是把 Second Chance 算法中的链表改成了环形链表
NRU (Not Recently Used):最近没使用算法,根据页面的访问位R和修改位M将页面分为四类,优先置换类别最低的页面。
LRU (Least Recently Used):最近最少使用算法,置换最长时间未被访问的页面。实现复杂,但性能较好。
- 软件实现
- 最常用的在队首,最少用的在队尾
- 每次内存访问都会更新这个 list,太昂贵了。
- 硬件实现 I
- 用一个 64 位计数器
- 每条指令递增这个计数器,然后再每个内存访问,这个计数器中的值被放在页表项中。然后选取这个值最小的页表项。
- 周期性地(就是所说的最近)对这个计数器置零
- 硬件实现 II
- 对一个有 n 个 page frame 的机器维护一个 n×n 的矩阵
- 当第 K 个 page frame 被引用时,把第 K 行全部置为 1,第 K 列全部置 0
- 要替换时,对应行二进制值最小的就是 LRU Page
- 软件实现
NFU (Not Frequently Used):不经常使用算法,通过为每个页面维护一个计数器来记录页面被访问的频率,置换计数器值最小的页面。NRU 可能不会那么精确,因为它只简单地跟踪页面是否被访问过,而不考虑访问的时间间隔(LRU)。
- 就是对 LRU 的软件模拟,因为 LRU 软件实现太 expensive,硬件实现对硬件有要求难以实现
- 每个 page 都有一个计数器,在每个时钟周期,R 位加到计数器上,当 page fault 发生时,计数器最小值被替换,但是 NFU 没有遗忘机制,可能这个 page 是过去经常使用的,但是现在已经不怎么使用
Aging:老化算法,是NFU的改进版,通过为每个页面维护一个移位寄存器来模拟LRU的效果,定期将寄存器右移,同时将访问位加到最左边,以此来近似页面的访问频率和时间。(与LRU相比)缺点是计数器的位数有限,例如8位,那么9个时钟周期之前和1000个时钟周期之前的访问都没有被记录,没差别了。
Working Set:工作集算法,根据过去一段时间内被访问的页面集合(工作集)来进行置换,旨在保留当前正在使用的页面集合。
- 工作集(Working set) w(k,t)表示在 t 时间内最经常访问的 k 个页面,或者 ws(t)表示在过去的 t 时间内访问的所有页面
- 每个时钟周期,清空所有 R 位
- 当需要置换时,遍历主存中所存储的所有 page
- 如果 R=1 就把当前时间 t 存储进当前 PTE 的 LTU(last time used)字段
- 如果 R=0:
- 如果 $t-LTU > \tau$, 就把这个页换出,因为表示这个页不在ws(t)中
- 如果 $t-LTU <= \tau$,就记录下 age(当前时间-LTU)最大的页
WSClock:工作集时钟算法,结合了工作集和时钟算法的特点,使用时钟算法的结构来维护工作集,以此来优化页面置换。
- 维护一个环形链表, 当 page fault 发生时:
- 使用一个守护进程(Paging daemon)来检测内存状态
- 如果太少 page frame 可用了就用 replacement 算法换出一些 page
- 可以用前后指针的方式在之前的环形链表上运行
Design Issues for Paging Systems
Replacement Scope
- Local Replacement
- Global Replacement

- 局部置换就是在进程所有的 page 内进行置换
- 全局置换就是可以把其他进程的 page 用于置换
workset只能定义在某个进程中,因此也就只能用局部置换load control
- 尽管我们有很好的算法,但是因为进程总是想要更多的内存,也会造成系统的颠簸(频繁 page fault)
- 所以我们要控制进程在内存中的数量,就可以减少对内存的竞争,可以通过把更多的内容存在硬盘中和控制程序的并行度来做到
Page Size
- 较小能带来更少的内部碎片和内存浪费,但是会导致页表更大
- 较大则反之
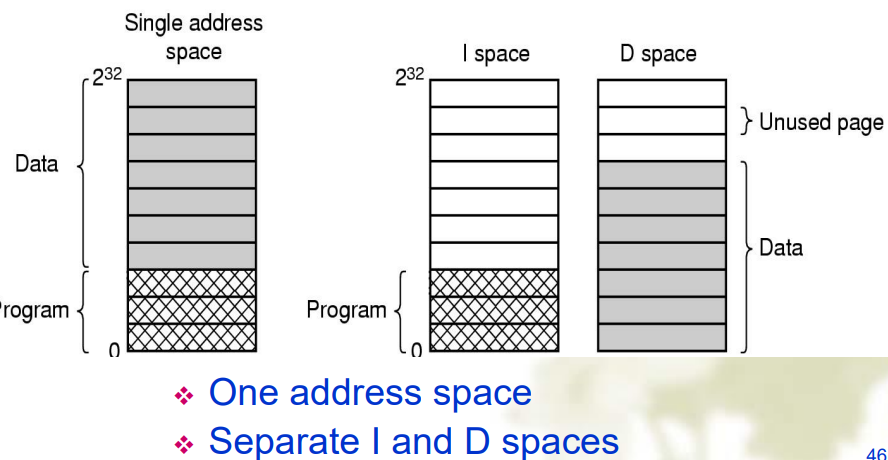
Separate Instruction and Data Spaces
Shared Pages
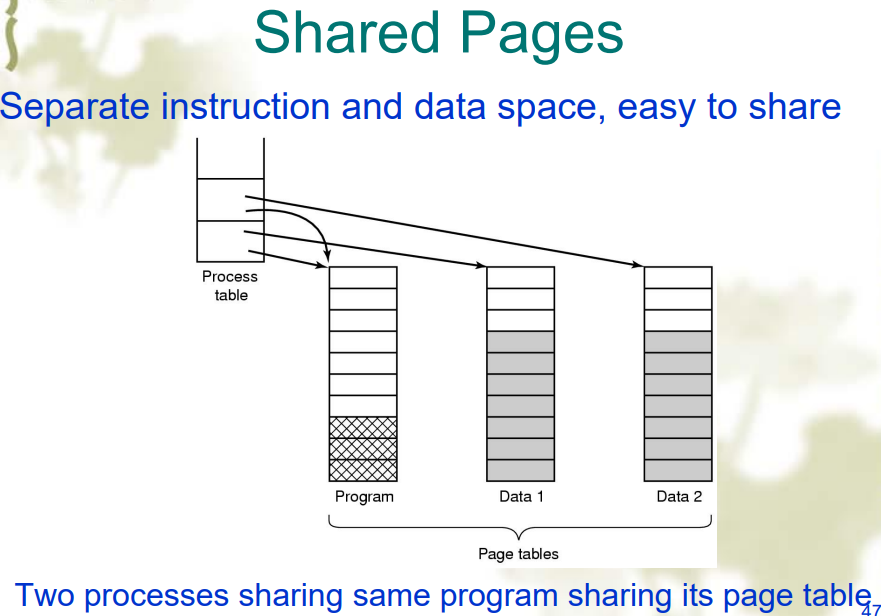
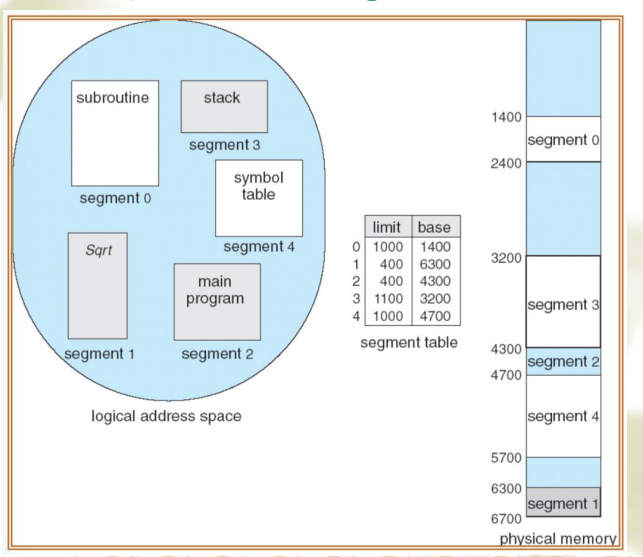
通过在 PCB 中用指针指向同一个页表来实现共享数据Segmentation: Address Translation
为了让程序和数据能被划分为逻辑上相互独立的地址空间,从而支持共享和保护
分段是一种内存管理技术,它允许地址空间被划分为多个逻辑段,每个段都有其独立的地址空间。这种方式更加符合程序的逻辑结构,如代码段、数据段和堆栈段等。分段的主要目的是为了更好地支持程序的模块化和共享,同时也简化了处理程序的动态增长问题。
地址转换:在分段系统中,虚拟地址由两部分组成:段号和段内偏移。操作系统维护一个段表,每个表项包含段的基址和长度。地址转换时,系统使用段号查找段表以获取段的基址,然后将段内偏移加到基址上,得到物理地址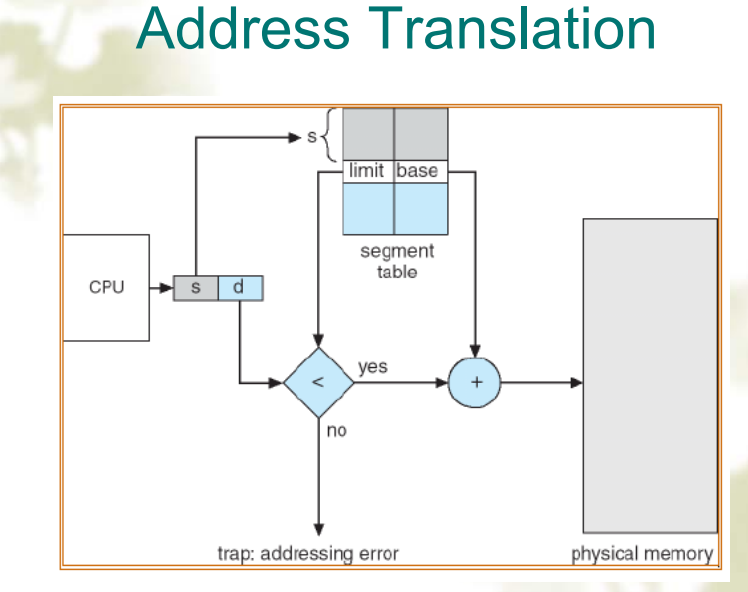
- 优点
- 可以扩展、收缩段
- 每个段都可以被单独保护
- 可以在并行任务中链接程序
- 在进程间共享代码变得容易
- 缺点
段被分为页,一个段的内容在内存中不再是连续的,也不是全都在内存中,因此每个段都要有一个页表,因此在段页式中,段的 base 值不再是段在内存中的起始地址,而是这个段的页表的起始地址
段页式内存管理结合了分段和分页两种技术的优点。首先,它将地址空间分为多个段,每个段都可以根据需要动态增长和缩小;然后,每个段内部使用分页技术,将段进一步细分为固定大小的页。这种方法既保持了分段的模块化和保护特性,又利用了分页技术的简化地址管理和内存利用率高的优点。
地址转换:在段页式系统中,虚拟地址包括三部分:段号、页号和页内偏移。首先,使用段号在段表中查找到对应段的信息;然后,将段内的页号用于访问该段的页表,找到页的物理地址;最后,将页内偏移加到页的物理地址上,得到最终的物理地址。这种方式有效地结合了分段和分页的地址转换机制。

TLB:
以下哪个不是段页式的优点?
A. User can have a clear logical view of memory
B. Different access protections can be associated with different segment of memory
C. No external fragmentation
D. More efficient in time than pure fragmentation and pure paging段页式存储管理是一种结合了段式和页式存储管理特点的系统。它允许用户以逻辑段的方式组织程序和数据,同时通过页式管理来进一步细分这些段,以提高内存的使用效率。
选项A “User can have a clear logical view of memory”(用户可以清晰地逻辑地查看内存)实际上是段式存储管理的优点,因为段式管理允许用户以逻辑段的方式组织内存,而不是段页式的优点。
选项B “Different access protections can be associated with different segment of memory”(不同的访问保护可以与不同的内存段关联)是段式存储管理的优点,因为段可以设置不同的访问权限。
选项C “No external fragmentation”(没有外部碎片)和选项D “More efficient in time than pure fragmentation and pure paging”(比纯碎片和纯分页更高效)通常被认为是段页式存储管理的优点,因为段页式管理结合了段式和页式的优点,减少了外部碎片,并提高了时间效率。
因此,根据这些描述,选项A不是段页式的优点。chapter 4 File System
File and File System
File
- file name
- 由有效名(Valid name)和扩展名(Extension)组成
- 至多 255 个字符
- 支持数字、字母、特殊字符,例如不支持冒号,因为冒号在 windows 系统中是路径分隔符
- Windows 不区分大小写,linux 区分
- file type
- 普通文件:
- ASCII 文件(字符文件)
- 二进制文件:可执行文件、存档文件
- 目录文件:作为文件系统的一部分
- 字符特殊文件:用来建模串口 I/O 设备,例如终端,打印机,网络
- 块特殊文件:用来建模硬盘设备
- file structure
- 字、字节序列
- 简单的记录结构:线性,定长
- 复杂的结构:
- 记录树
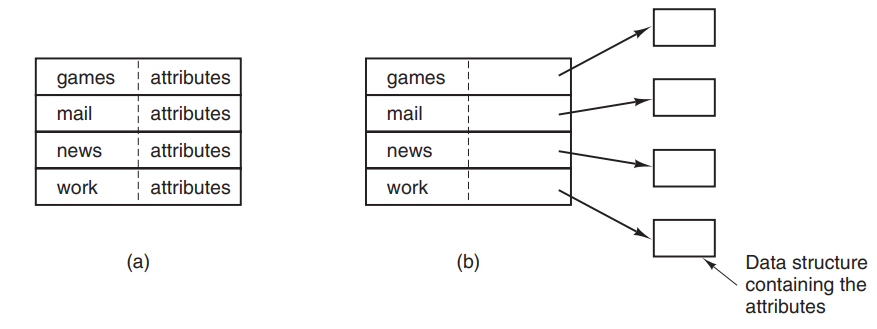
- file attributes
- 操作系统会把关于文件的一些信息和文件联系在一起,称为文件属性(file attributes)或者元数据(metadata)
- file operations
- 于顺序读取的文件有以下方法:
- Create
- Delete
- Open
- Close
- Read
- Write
- Append
- Seek
- Get attributes
- Set Attributes
- Rename
- file access
- Present logical(abstract) view of files and directories: Hide complexity of hardware devices 逻辑视图,隐藏硬件设备的复杂性
- Facilitate efficient use of storage: Optimize access, e.g., to disk 优化存储访问,例如磁盘
- Support sharing: Provide protection 支持共享,提供保护
Directory Structure
one-level directory
- 一个根目录下包含所有文件
- 效率低、有命名冲突、没有分组
two-level directory
- 根目录下划分用户目录,每个用户目录包含所有文件
- 没有分组
Hierarchical Directory
- 允许任意深度、宽度的目录
- 每个用户有一个当前(工作)目录
- 叶子节点是文件,中间节点是目录
- 实现了名字冲突(不同用户可以有相同的文件名),高效的查找,文件的共享和保护以及分组的能力。
Path Name: Absolute, Relative
Two different methods are used to specify file
names in a directory tree:- Absolute path name consists of the path from the root directory to the file.
- Relative path name consists of the path from the current directory (working directory).
- The path name would be written:
- Winodws \usr\ast\mailbox
- UNIX /usr/ast/mailbox
- MULTICS >usr>ast>mailbox
- Dot and dotdot are two special entries in the file system.
- Create a new directory
- Delete an empty directory
- Open a directory for reading
- Close a directory to release space
- Readdir
- return next entry in the directory
- Rename a directory
- Link
- Create a link from the existing file to a path name. (ie. Make a “hard link”.)
- Unlink
- MBR(Master Boot Record):主引导记录,位于扇区 0
- 分为多个 partion
- Boot block:可能是一些程序,用来引导系统启动
- Super block: 包含文件系统的元数据,例如文件系统的大小,空闲块的数量,文件系统的类型
- I-nodes: 索引节点,包含文件的元数据,例如文件的大小,文件的权限,文件的创建时间
- Free space management: 空闲空间管理
- Root directory: 根目录
- Files and directories: 文件和目录
文件实现(File Implementation)
文件的本质就是一个 bytes 序列,因为硬盘的单位是扇区(512bytes),因此块大小是扇区大小的2的幂次方,例如 512,1024,2048,4096; 给每个文件分配的大小是以块为单位。

有三种实现方法:连续分配(Contiguous Allocation),链表分配(Linked List Allocation),索引分配(Indxed Allocation)
Contiguous Allocation
Store each file as contiguous block of data.

- Advantages
- 易于实现(仅需要起始扇区和文件长度)
- 读取性能出色(适合顺序访问和直接访问)
- Disadvantages
- Storing a file as a linked list of disk blocks, blocks may be scattered anywhere on the disk.
- The first word of each block is used as a pointer to the next one.


- 优点:
- 无外部碎片
- 目录条目简单(仅需要起始地址)
- 只要有空闲块,文件就可以继续增长
- 适合顺序访问
- 缺点:
- 把硬盘块中的 next 指针移到一个
FAT(File Allocation Table)表中,FAT在系统运行时会被部分或全部加载到内存中,以尽量减少磁盘寻道,提高文件访问效率(但它的持久存储位置是在磁盘上),但是空间开销可能很大 - 磁盘上每个块一个条目,按块号排序
- 每个条目包含“下一个”块的地址
- 用-1 来标记文件的结束,-2 标记空闲的块
- Used by OS/2 and MS-DOS
- 优点:可以把整个块用来存储数据了,随机访问快一点了,因为 FAT 在内存中
- 缺点:FAT 占用大量内存空间,例如 200GB 的硬盘,如果一个块是 1KB,FAT 的一个表项占用 4bytes,FAT 表将占用 800MB


Indexed Allocation(i-Node)
- 将所有指针集中到一个位置(索引块或索引节点)
- 每个文件都有自己的索引节点 (i-node),其中列出了文件的属性和磁盘块地址。
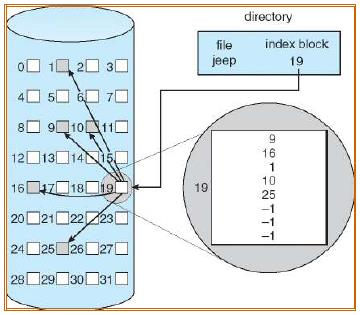
❖ 问题:如果每个 i-node 都有固定数量的磁盘地址空间,那么当文件大小超出此限制时会发生什么?
❖ 某些索引条目指向索引块,而不是数据块(例如 Linux ext2)。
❖ 块索引有多个级别。- i-node(index-node)存储了这个文件所有的逻辑块与物理块的对应关系
- 目录保存了文件对应的 i-node 的位置即可
- 还可以通过在 i-node 节点中保存其他 i-node 节点位置来实现多级索引
- Multi-level Indexed Allocation
- A single indirect block contains pointers to data blocks.
- A double indirect block contains pointers to single indirect blocks.
- A triple indirect block contains pointers to double indirect blocks.

- 优点
- 快速查找和随机访问
- 不受外部碎片的影响
- i-node 仅在相应文件打开时才需要位于内存中
- 缺点
- 目录是跟普通文件一样存储的,目录项存储在 data 块中,一个目录文件包含一个目录项列表
- 当打开文件的时候,OS 通过路径名来定位目录项。
- 目录项为找到硬盘上的块提供了信息:
- 实现 1
- 把文件名和文件属性包含在目录项中
- Windows 和 DOS 系统使用这种方法
- 实现 2
- Solution1: Fixed-length names
- 通常为 255 个字符
- 最简单
- 浪费空间
- Solution2: Directory entry comprises fixed and variable portion (in line)
- 例如图中的定长部分是目录项长度和文件属性信息,可变部分就用来存储文件名,在文件名的最后会补齐一个字
- 好处是节约空间,缺点是当一个文件被删除,这个目录项也就被删除,新插入到这里的目录项只能小于等于删除的目录项的长度,就是产生了碎片,而且目录项可能跨页,就会引起 page fault

- Solution3: Directory entries are fixed in length, pointer to file name in heap
- Linear search
- 顺序查找
- 适用于小目录
- Hash Table
- 适用于大目录
- 但是可能会有冲突
- Cache the results of searches
- 共享文件用于允许文件出现在多个目录中。
- 目录和共享文件之间的连接称为链接。文件系统是有向无环图 (DAG),而不是树。
- 问题
- 如果目录包含磁盘地址,则必须在目录 B 中复制磁盘地址。
- 如果 B 或 C 附加文件,则新块将仅出现在一个目录中。
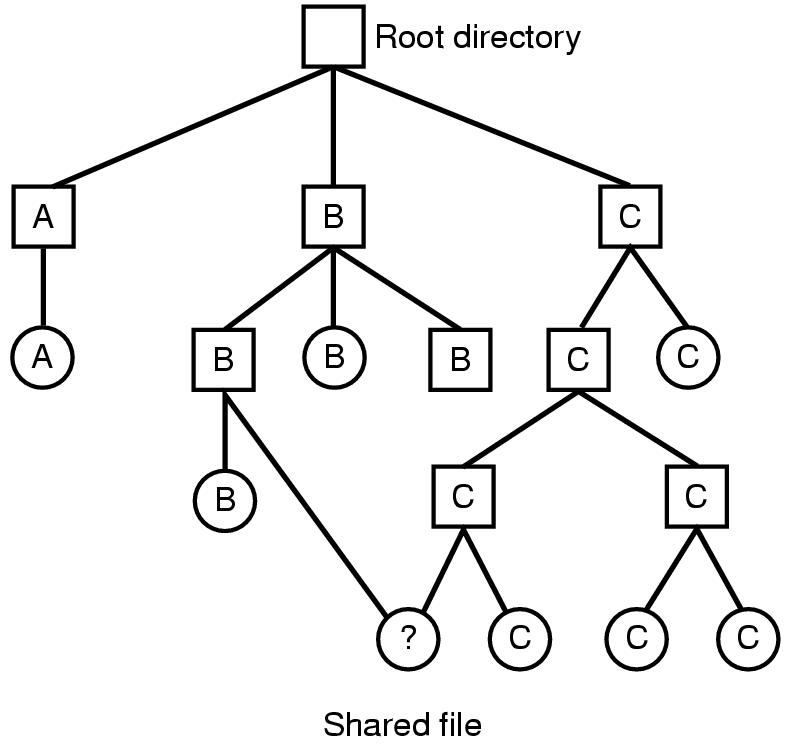
❖ 解决方案:
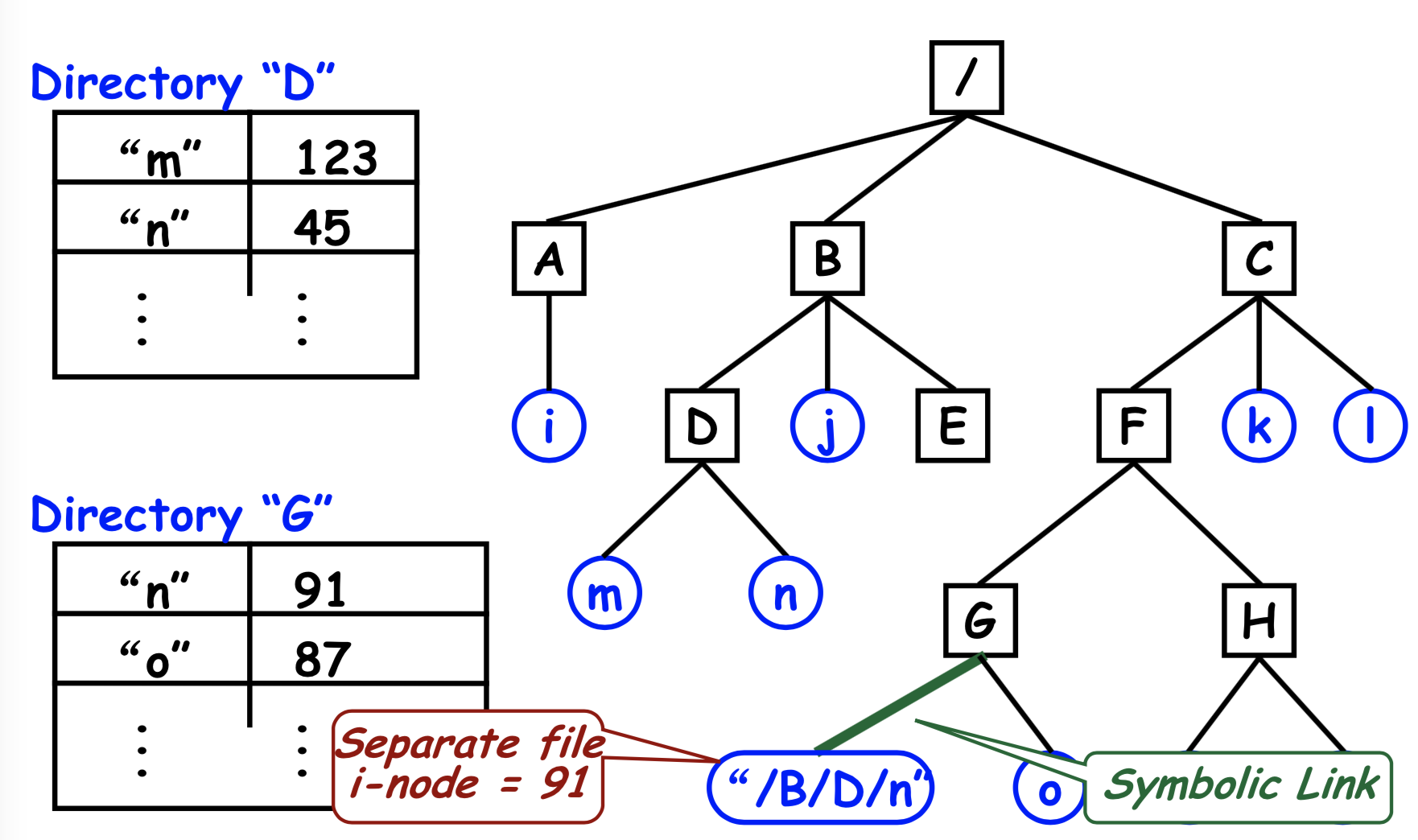
- 不要在目录中列出磁盘块地址,而是在一个小的数据结构中列出,i-node ➔ 硬链接
- 两个目录都指向同一个 i-node
$ ln /users/steve/wb . (hard link)$ -rwxr-xr-x 2 steve DP3725 89 Jun 25 13:30 wb
- 创建一个 LINK 类型的新文件,其中包含它链接到的文件的路径名➔ 符号链接(软链接)
- Hard Links
- Put a “reference count” field in each i-node
- Counts number of directories that point to the file
- When removing file from directory, decrement count
- When count goes to zero, reclaim all blocks in the file

- Symbolic Link (only the owner directory has a pointer to i-node)只有所有者目录具有指向 i 节点的指针
- When remove the real file… (normal file deletion), symbolic link becomes “broken” 当删除真实文件时…(正常文件删除),符号链接变为“损坏”
- Removing a symbolic link does not affect the file at all. 删除符号链接根本不会影响文件。

优缺点
- 硬链接的限制
- 无法跨文件系统建立链接
- 如果将其中一个文件移动到不同的文件系统,则会将其复制,并相应地调整两个文件的链接数
- 只有超级用户可以创建指向目录的硬链接
- 符号链接的问题
- 磁盘上需要额外的空间和额外的 i 节点来存储链接文件(它自己需要一个i-node来存储其元数据,包括链接指向的路径、创建时间、权限等信息,而硬链接不需要)
- 遍历路径中的额外开销
- 如果将原始文件移动到其他位置,则无法再通过符号链接(悬空链接)访问它
- 将文件转储到磁带上时,可能会设置文件的多个副本。
- 硬链接给用户的感觉就像是同一个文件的不同名称,而符号链接更像是一个指向另一个文件或目录的快捷方式。
Disk Space Management
❖ 存储 n 字节文件的策略:
分配 n 个连续字节的磁盘空间 - 段
分配多个 [n/k] 个大小为 k 字节的块 -
分页
❖ 连续分配的问题
如果文件增大,则必须在磁盘上移动,这是一项昂贵的操作,并会导致外部碎片。 =>
❖ 几乎所有文件系统都将文件分割成固定大小的块,这些块不必相邻。Block Size
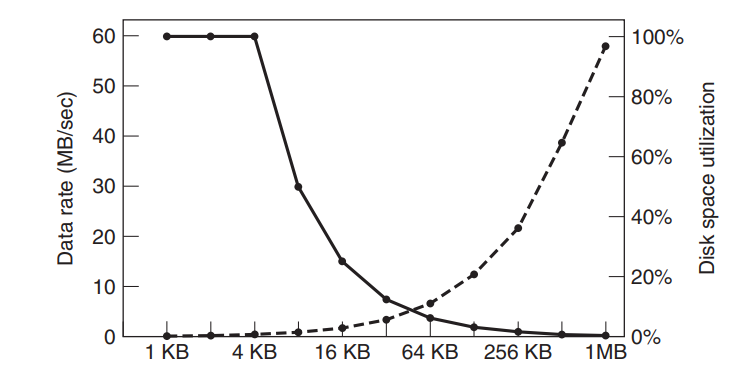
- 块大:数据传输率大,空间利用率小
- 块小:数据传输率小,空间利用率大
Keeping Track of Free Blocks
- 使用磁盘块链接列表:每个块保存尽可能多的可用磁盘块号。
- 示例:对于 1 KB 块和 32 位磁盘块号 ➔1024 * 8/32 = 256 个磁盘块号 ➔ 255 个可用块(和)1 个下一个块指针。

- 示例:对于 1 KB 块和 32 位磁盘块号 ➔1024 * 8/32 = 256 个磁盘块号 ➔ 255 个可用块(和)1 个下一个块指针。
- 使用位图:具有 n 个块的磁盘需要具有 n 位的位图
- 空闲块用 1 表示
- 已分配块用 0 表示
- 如果位图能够完全保存在内存中,则通常效果更好。

- 位图与链表比较
- 使用位图:16GB 磁盘有 $2^{24}$ 个 1KB,需要 $2^{24}$ 位 ➔ $2^{24}$个bit相当于$2^{11}$ 个$2^{10}$字节($2^{3}$个bit) ➔ 2048个块
- 使用链表:$2^{24}$/255 = 65793 个块
- 位图需要的空间较少
- 只有当磁盘几乎已满(即空闲块很少)时,链表方案才会比位图需要更少的块
- ❖ 计数
- 我们不必保存 n 个空闲磁盘地址的列表,而是保存第一个空闲块的地址和第一个块之后的空闲连续块的数量 n。
- 这样,空闲空间列表中的每个条目都由一个磁盘地址和一个计数组成。
- 尽管每个条目比简单的磁盘地址需要更多的空间,但只要计数通常大于 1,整个列表就会更短。
File System Reliability 文件系统的可靠性
备份
不备份特殊文件(I/O 文件等)文件系统的一致性
- Windows:scandisk UNIX:fsck
块级一致性检查:fsck(in UNIX, windows 是 scandisk)
- 基本原则:硬盘上的每个块不是在文件或者目录中就是在 free list 中
- 维护两个表,每个表都有一个 n 位计数器(位图),来记录每个块的使用情况
- 读取所有 i-nodes,标记使用的 block
- 读取 free list,标记所有的空闲块
在文件系统中,
free list是一种数据结构,用于跟踪磁盘上的空闲块。每个块都是存储数据的基本单位。当文件被删除或文件系统被重新组织时,这些块变为空闲并可供新文件使用。free list记录了这些可用块的位置和数量,使得文件系统能够有效地找到空间来存储新的或修改后的文件。- 空闲块的地址:指向磁盘上第一个空闲块的位置。
- 空闲连续块的数量:表示从第一个空闲块开始,有多少个连续的块是空闲的。
这种方法通过记录连续空闲块的起始地址和数量,而不是列出每个空闲块的地址,减少了所需的存储空间,提高了空间利用率和管理效率。
不一致的状态
- 块既不在文件或者目录里,也不在 free list 中:把这个块加入 free list
- 块在 free lisst 中出现了多次:不会在位图实现的 free list 中出现,只会出现在链表中,只需要删除多余的块来修复 free list
- 块同时出现在在多个文件中:
- Allocate 另一个块
- 把块中的内容复制到新块中
- 把新块放进文件中
- 块同时出现在 free list 和已使用块中:从 free list 中删除这个块

fsck:目录级一致性检查
- 每个文件有一个 counter 而不是每个块
- 递归地从根目录下降,把每个文件中的 counter+1(父目录会被目录下的子目录和文件都引用,从而实现了树状结构),包括硬链接,把最后得到的结果和 i-nodes 节点中存储的 reference counter 比较,如果 reference counter 偏大或者偏小,都去修改 i-nodes,使得其 reference number 和递归得到的值相同
文件系统表现优化
- 缓存:避免大量硬盘 I/O 的耗时
- 预读块(Block Read Ahead):提高 cache 命中率
- 减少磁头移动:减少寻道时间
Example File Systems(UNIX)


chapter 5 I/O Systems
I/O 设备和驱动程序
- Principles of I/O software
- I/O software layers
- Disks
Principles of I/O software
- Goals of I/O Software
- I/O Operations
- Programmed I/O
- Interrupt-driven I/O
- I/O using DMA
programed I/O
- CPU在I/O完成之前始终忙于I/O操作
- 适用于单进程系统
- MS-DOS
- 嵌入式系统
- 但对于多程序和时间共享系统不是好方法
- 适用于单进程系统
- 假设程序想要打印字符串到打印机,字符串为”ABCDEFGH”,8个字符长,假设打印机有1字节的数据缓冲区
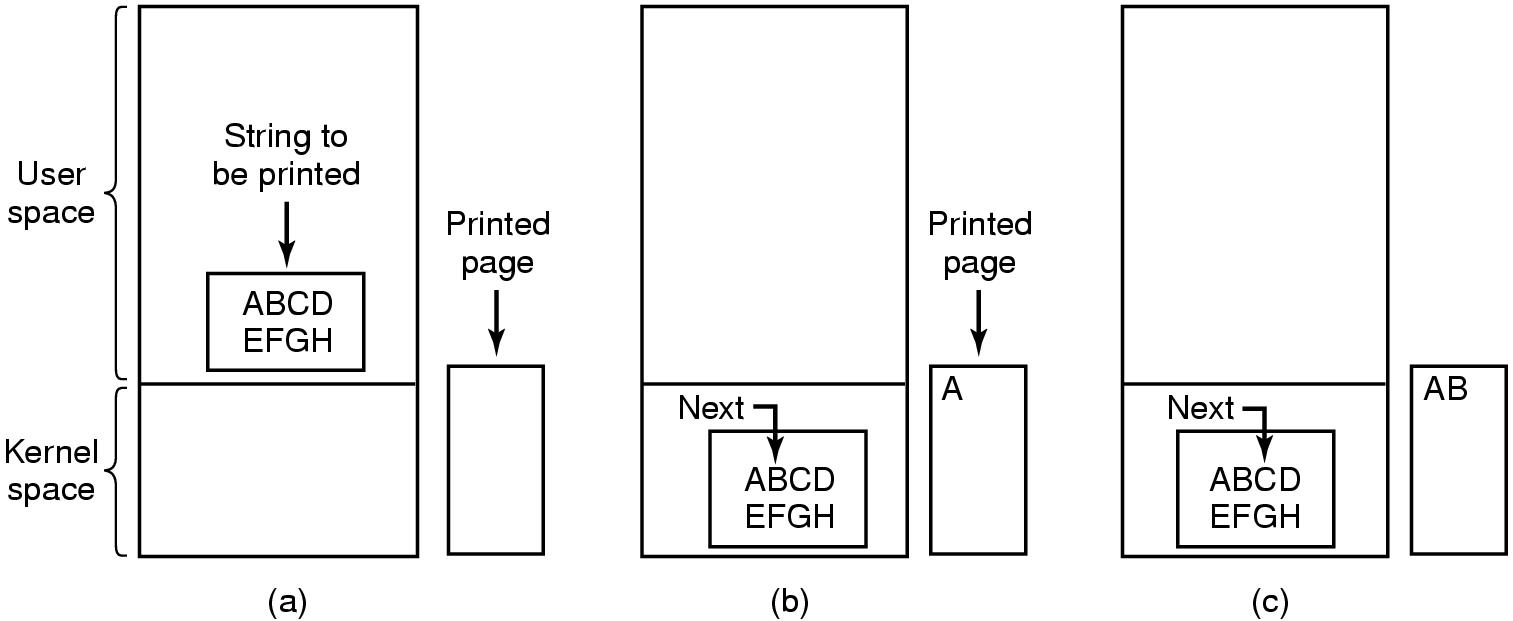

- 轮询:CPU忙于检查打印机的状态寄存器以确定其状态
- 准备就绪
- 忙碌
- 错误
- 等待I/O的忙等待周期,浪费CPU资源
Interrupt-Driven I/O
- 将应用程序缓冲区内容复制到内核缓冲区后,发送1个字符到打印机
- CPU不需要等待打印机再次就绪
- 调用scheduler()运行其他进程
- 当前进程进入阻塞状态
- 使用中断驱动I/O将字符串写入打印机

- (a) Code executed when print system call is made
- (b) Interrupt service procedure
- 中断驱动I/O的缺点是每个字符都会发生中断
I/O using DMA
- DMA控制器将从内核缓冲区向打印机控制器提供字符
- 整个缓冲区(字符串)传输完成后,CPU被中断
- Printing a string using DMA

- User-level I/O software
- Device-independent OS software
- Device drivers
- Interrupt handlers
- Hardware(Disks)
判断一个操作是由哪个I/O软件层次完成的,可以根据操作的性质和责任范围来决定。一般而言,I/O软件可以分为四个层次:
- 用户级I/O软件:这一层主要处理与用户直接相关的高级I/O操作,如提供用户接口、数据转换(例如,将二进制整数转换为ASCII码以便打印)和错误检测等。
- 设备独立性软件:这一层提供一致的接口给上层软件,隐藏了不同I/O设备之间的差异。它负责如设备分配、释放、以及一些通用的I/O函数等。检查用户是否允许使用设备这类操作通常在这一层完成,因为它涉及到操作系统的安全和权限管理,而这些是独立于具体设备的。
- 设备驱动程序:这一层直接与硬件交互,负责发送具体的命令到设备,如读写操作。它将上层的抽象请求转换为具体的硬件操作。例如,为一个磁盘读操作计算磁道、扇区、磁头,以及为设备寄存器写命令这些操作都是在设备驱动程序层完成的。
- 中断处理程序:这一层处理硬件中断,当硬件设备完成操作或需要注意时会产生中断,中断处理程序负责响应这些中断,并通知设备驱动程序或操作系统的其他部分。
通过分析操作的具体职责和它与硬件的交互程度,可以判断该操作属于哪个I/O软件层次。
Interrupt Handlers
中断处理程序应尽可能隐藏,以减少操作系统对它的了解。
隐藏的最佳方式是让驱动程序启动 I/O 操作阻塞,直到中断通知完成
- A down on a semaphore
- A wait on a condition variable
- A receive on a message
Interrupt handler does its task and then unblocks driver that started it
- 中断处理过程
- 中断向量就是中断服务程序的首地址
- 软件处理过程
- 保存没有被中断硬件存储的寄存器的值
- 设置中断服务程序的上下文
- 设置中断服务程序的栈
- 响应中断控制器,重新开启中断
- 将寄存器从保存位置复制到进程表
- 运行服务程序
- 选择下一个要进行的进程
- 设置 MMU 上下文为下一个要运行的进程
- 加载新进程的寄存器
- 开始运行新进程
Device Drivers
- 设备驱动程序是一个管理设备控制器和操作系统之间交互的特定模块。
- 设备独立请求 -> 设备驱动程序 -> 设备相关请求
- 通常由设备制造商编写,不一定由操作系统编写者编写
- 驱动程序可以为多个操作系统编写
- 每个驱动程序可以处理一种类型的设备
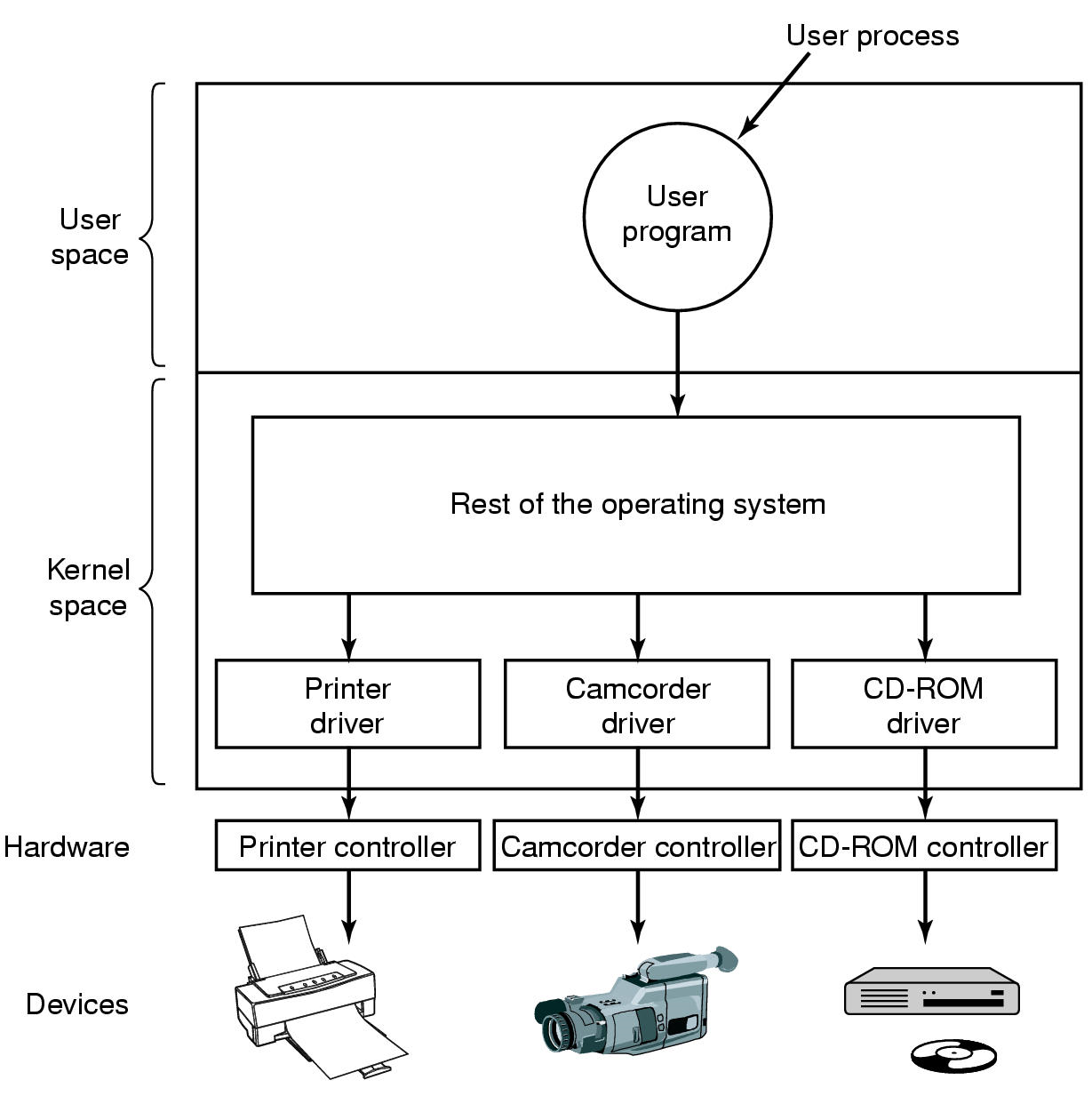
- Logical position of device drivers is shown here
- Communications between drivers and device controllers goes over the bus
- 设备驱动程序功能
- 接受来自操作系统其余部分(与设备无关的部分)的抽象读写请求。
- 将抽象术语转换为具体术语。
- 示例:磁盘驱动程序将线性块地址转换为物理磁头、磁道、扇区和磁柱号。
- 必要时初始化设备
- 检查设备当前是否正在用于其他请求。
- 如果是,则将请求排队。
- 发出命令序列来控制设备
- 检查错误
- 接受来自操作系统其余部分(与设备无关的部分)的抽象读写请求。
- 我们需要有一个定义明确的模型,说明驱动程序的作用以及它如何与操作系统的其余部分集成。
- 设备驱动程序的统一接口
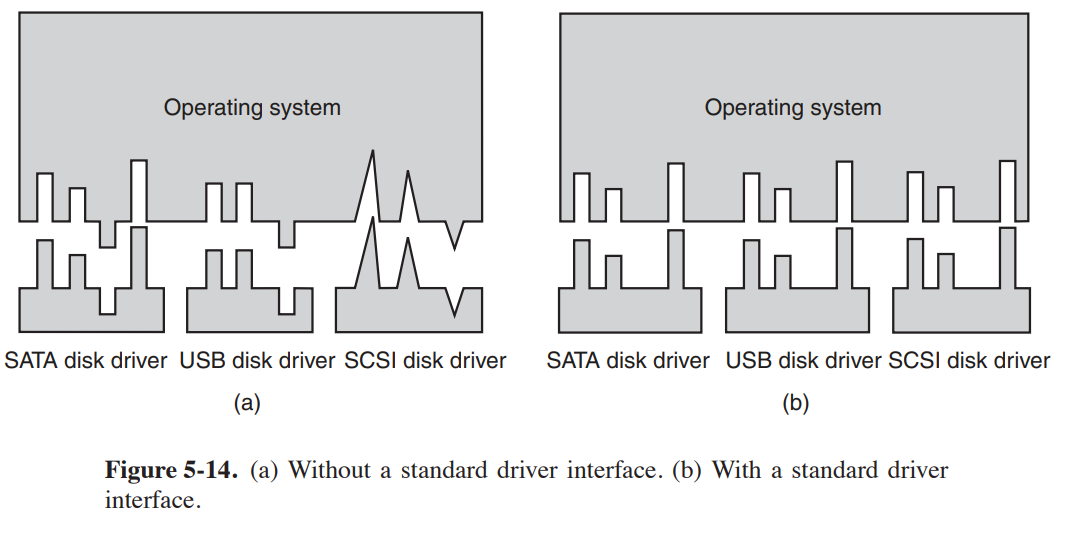
- 在 Unix 中,设备被建模为特殊文件。
- 通过使用系统调用(如 open()、read()、write()、close()、ioctl() 等)可以访问它们。
- 每个设备都与一个文件名相关联。
- 主设备号定位相应的驱动程序。
- 次设备号(存储在 i 节点中)作为参数传递给驱动程序,以指定要读取或写入的具体设备单元。
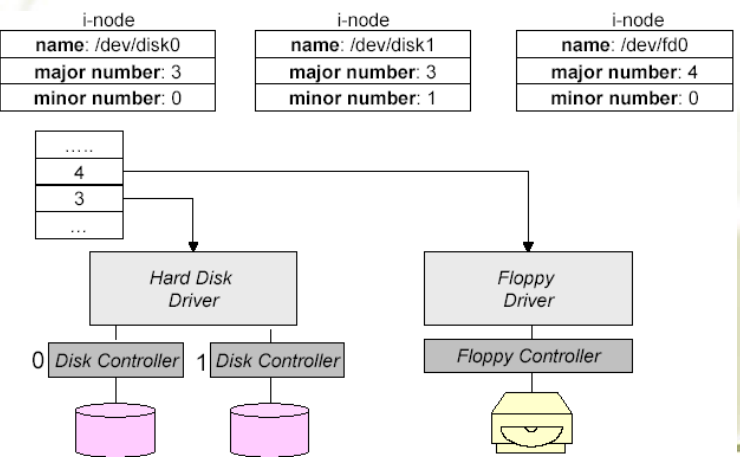
- 次设备号(存储在 i 节点中)作为参数传递给驱动程序,以指定要读取或写入的具体设备单元。
- 文件的常用保护规则也适用于 I/O 设备
- 缓冲buffer

- (a) 无缓冲输入
- (b) 在用户空间缓冲
- (c) 在内核缓冲,然后复制到用户空间
- (d) 在内核双缓冲

- Networking may involve many copies
- 错误处理
- 有一些错误可以在底层设备处理,例如一些校验和错误,通过随机 bit 尝试修复 block
- 底层设备处理不了的话就传到上层设备驱动程序处理,例如无法读取 block 的时候重新读取
- 再无法处理的错误就传到 OS 的设备无关软件层处理,例如尝试向只读设备中写入数据
- 设备无关的块大小
- I/O 库提供 I/O 函数来给用户提供对应的 I/O 系统调用的实现,还提供例如格式化的 I/O 的操作(printf())
- 有些应用程序不直接写入 IO 设备,而是写入假脱机文件(spooler)
summary of I/O software

Disks
磁盘被分成柱面(cylinders),每个柱面包含磁道(tracks),每个磁道被分成了一些扇区(sectors),扇区大小通常为 512bytes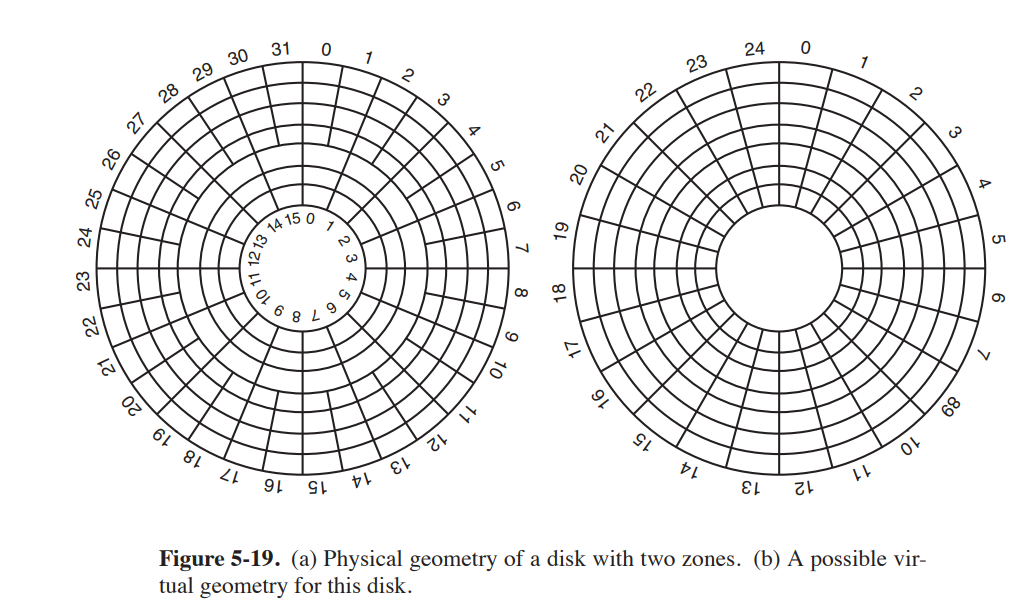
磁盘格式化
制造完成后,磁盘上没有任何信息,只有空位。在被使用之前,磁盘需要被格式化,格式化的过程会在磁盘上创建文件系统,以便操作系统可以使用磁盘来存储文件。
低级格式化
- 将磁盘划分为磁盘控制器可以读写的扇区
- 低级格式化通常由供应商完成
- 每个磁道应按以下方式格式化:
- 扇区及其之间的扇区间隙
- 扇区的格式如下:
- 前导码 – 数据(512 字节) – 校验和

柱面斜进
在设置低级格式的时候,第0扇区的位置与前一个磁道存在偏移,这一偏移称为柱面斜进(cylinder skew)。这是因为磁头在磁盘上移动时,磁盘旋转的速度是固定的,而磁头移动的速度是可变的,由于盘片持续旋转,因此在磁头移动到下一个磁道的过程中,磁盘旋转了一定的角度,这就导致了磁头在下一个磁道上的位置与前一个磁道上的位置存在偏移。为了解决这个问题,需要在设置低级格式时,将第0扇区的位置与前一个磁道的位置进行调整,这样就可以保证磁头在移动到下一个磁道时,能够准确读取数据。
- 就是为了补偿寻道过程中盘片的旋转时间
- 例如:10000rpm(6ms/圈),一个磁道有 300 个扇区(20μs/sector),寻道时间为 800μs,那么就要斜进 40 个扇区。
交错(interleaving)
从硬盘控制器的缓冲区把数据复制到内存中需要时间,这就会导致在连续读取的时候有可能磁头就“过站”了,再访问下一个连续的扇区反而要多转一圈,因此通过交错的方法,使得访问的下一个逻辑扇区不是下一个物理扇区,也就是提高两个扇区之间的时间间隔。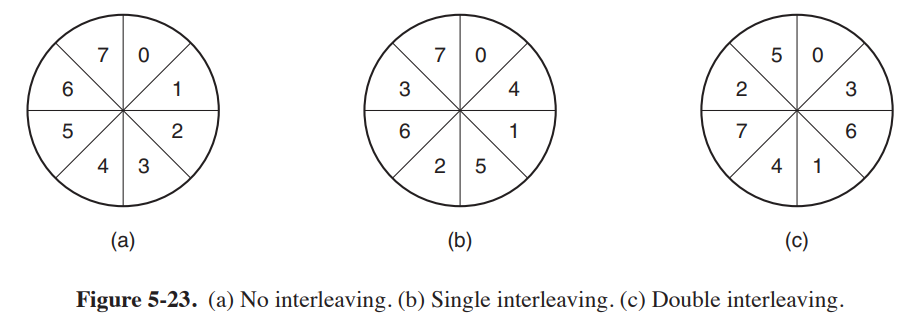
磁盘臂调度算法
表现的指标
seek time 寻道时间:磁头移动到指定磁道的时间rotational time 旋转时间:磁盘旋转到指定扇区的时间Actual data transfer time 传输时间:数据从磁盘传输到内存的时间
FCFS(First-Come, First-Served)
- 按照请求的顺序进行处理
SSF(Shortest Seek First)
- 优先移动到最近的磁道,可能会导致某些磁道被永远忽略,饿死

Elevator(电梯算法)
- 让磁盘臂沿一个方向运行,直到那个方向没有别的请求了,再回头,还可以变式成在完成最高编号的柱面后,移动到编号最小的柱面再向上移动(也就是把最小编号看成最大编号的相邻柱面),这样有更好的响应时间。
- 好处是给定一组请求,磁盘臂移动的次数的上界永远是柱面数的两倍

错误处理
预留扇区来给坏扇区使用,当检测到有扇区损坏的时候,就把预留扇区映射到原来的坏扇区中。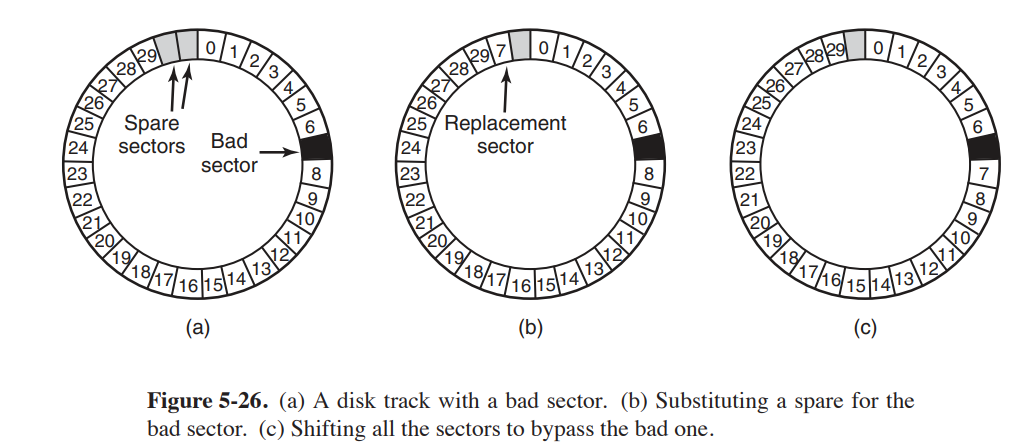
作业题回顾
chapter 1
- 请简述操作系统的功能
- 操作系统是一种系统软件,它是计算机系统中的核心软件,是计算机系统的管理者和协调者,负责管理和控制计算机系统的硬件、软件和资源,提供用户与计算机之间的接口,是计算机系统的核心和基石。
- 简版:为用户提供扩展,管理系统资源
- 分时系统和多道程序系统的区别是什么?
- 分时系统是一种多用户操作系统,它允许多个用户通过终端同时访问计算机系统,每个用户都有自己的终端,可以独立地输入和输出,系统通过时间片轮转的方式来分配 CPU 时间,以实现多个用户同时访问计算机系统。多道程序设计系统允许用户同时允许多个程序。所有的分时系统都是多道程序设计系统,但不是所有的多道程序设计系统都是分时系统,因为多道程序系统也可以在个人计算机上运行。
chapter 2
- 理论上三种进程状态有六种转换,除了四种基本转换外,另外两种可能存在吗?
- 原本存在的四种转换是:ready -> running, running -> blocked, running -> ready, blocked -> ready;
- 假设一个进程因为等待输入阻塞,当有效输入到来时,CPU刚好空闲,则可以直接从blocked -> running,这就是一种可能的转换
- 而从ready -> blocked,这种转换是不可能的,因为进程只有在running状态下才能被阻塞,而ready状态下的进程只能被调度到running状态
- 如果读取文件只能用阻塞的read系统调用,那么一个多线程的web服务器应该使用用户及线程还是内核级线程?为什么?
- 如果使用ULT,应用程序每个进程只有一个线程,一个线程阻塞将导致整个进程阻塞。如果使用KLT,内核级线程被阻塞,内核可以调度同一进程内的另一个线程。
- 线程可以被时钟中断抢占吗?可以或者不可以在什么情况下?
- 用户级线程在完成整个进程的时间片之前无法被时钟抢占;内核级线程如果运行时间过长,可以单独被时钟中断抢占。
- 在用户态实现线程的最大优点和缺点分别是什么?
- 用户级线程最大的优点是效率高,不需要陷入内核进行进程切换。缺点是一个线程阻塞,整个进程阻塞
- 在使用线程的系统中,若使用用户级线程,是每个线程一个栈还是每个进程一个栈?如果使用内核级线程呢?
- 每个线程都有自己的栈来存储局部变量、返回地址等。这对于UTL和KTL都一样
- KTL 可以用内核信号量对同一个进程中的两个线程进行同步吗?UTL呢?假设其他进程中没有线程需要访问该信号量
- 还是那个特性,KTL支持阻塞,所以可以用信号量同步;但是UTL一旦阻塞,整个进程都会阻塞,所以不行
- 考虑这段代码程序执行的时候创建了多少子进程?
1
2
3
4
5void main(){
fork();
fork();
exit();
}
- 创建了3个,fork分叉了两次,最后都退出了。
- 设计
woman_wants_to_enter,man_wants_to_enter,woman_leaves,man_leaves。(类似两队士兵过独木桥的感觉)- 定义计数器:
woman_in_use,man_in_use分别记录浴室里男女数量; - 定义semaphore:
mutex控制浴室访问权,woman_enter_allowed,man_enter_allowed; - 看代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51int woman_in_use = 0;
int man_in_use = 0;
Semaphore mutex;
Semaphore woman_enter_allowed;
Semaphore man_enter_allowed;
void woman_wants_to_enter(){
P(woman_enter_allowed);
P(mutex);
if (woman_in_use == 0){
P(man_enter_allowed);
}
// 女生沐浴
woman_in_use++;
V(mutex);
V(woman_enter_allowed);
}
void woman_leaves(){
// P(woman_allowed);不需要
P(mutex);
// 女生离开
woman_in_use--;
if (woman_in_use == 0){
V(man_enter_allowed);
}
V(mutex);
}
void man_wants_to_enter(){
P(man_enter_allowed);
P(mutex);
if (man_in_use == 0){
P(woman_enter_allowed);
}
// 男生沐浴
man_in_use++;
V(mutex);
V(man_enter_allowed);
}
void man_leaves(){
// P(man_allowed);不需要
P(mutex);
// 男生离开
woman_in_use--;
if (man_in_use == 0){
V(woman_enter_allowed);
}
V(mutex);
}chapter 3
- 定义计数器:
- 有5个批处理作业A~E,分别用RR、priority、FCFS、SFJ调度。并计算平均进程周转时间。(注意优先级是越大越高还是越小越高)
| 进程名称 | 作业时间 | 优先级 |
|---|---|---|
| A | 10 | 3 |
| B | 6 | 5 |
| C | 2 | 2 |
| D | 4 | 1 |
| E | 8 | 4 |
- $t_1= [(2÷(1/5))×5+((4-2)÷(1/4))×4+((6-4)÷(1/3))×3+((8-6)÷(1/2))×2+((10-8)÷(1))]/5=(50+32+18+8+2)/5=22$
- 其他三种略
一个软实时系统有4个周期时间,周期分别为50ms,100ms,200ms,250ms。假设这四个事件分别需要35ms、20ms、10ms、xms的CPU时间。保持系统可调度的最大值x是?
- 保持系统可调度的条件是所有周期时间所需的CPU时间与其周期时间的比的和不大于1
在一个交换系统中,按内存地址排列的空闲区大小是: 10MB, 4MB, 20MB, 18MB, 7MB, 9MB, 12MB, 15MB; 分别应用first fit、best、worst、next fit 处理连续的段请求:(12、10、9)MB.
- first fit: 12MB -> 20MB, 10MB -> 10MB, 9MB -> 10MB
- best fit: 12MB -> 12MB, 10MB -> 10MB, 9MB -> 9MB
- worst fit: 12MB -> 20MB, 10MB -> 18MB, 9MB -> 15MB
- next fit: 12MB -> 20MB, 10MB -> 18MB, 9MB -> 9MB
十进制虚拟地址,分别用4KB 页面和8KB 页面计算虚拟页号和偏移量:20000,32768,60000
- 4KB和8KB,即是 $2^{12}$, $2^{13}$。分别去除题目给的三个十进制虚拟地址,商和余数就分别是虚拟块号和偏移量
对照页表给出虚拟地址对应的物理地址
- 注意这里的K一般都指的是1024,而不是网络中的1000
- 按照距离起始位置的偏移来加到映射的起始位置上即可
38位虚拟地址和32位物理地址
- 与一级页表相比,多级页表的优点是什么?
- 多级页表由于其层次结构而减少了需要存储在内存中的页表的实际页面数。事实上,在具有大量指令和数据局部性的程序中,我们只需要顶层页表(一个页面)、一个指令页面和一个数据页面。
- 采用二级页表,页面大小为16KB,每个页表项为4字节,应该对第一级页表域分配多少位?对二级页表域分配多少位?解释原因。
- 为三个页面字段分别分配 12 位。偏移字段需要 14 位来寻址 16 KB。剩下 24 位用于页面字段。由于每个条目为 4 个字节,因此一个页面可以容纳 2^{12} 个页表条目,因此需要 12 位来索引一个页面。因此,为每个页面字段分配 12 位将寻址所有 2^{38} 个字节。
- 与一级页表相比,多级页表的优点是什么?
一个32位地址的计算机使用两级页表,虚拟地址被分为9位的第一级页表域,11位的第二级页表域和一个偏移量,页面大小是多少?地址空间中一共有几个页面?
- 32-9-11=12,所以页面大小是$2^{12}$,也就是4KB,一共有$2^{32-12}=2^{20}$个页面
一个计算机页面大小8KB,主存大小为256KB,64GB的虚拟地址空间使用倒排页表实现虚拟内存。为了保证平均散列链的长度小于1,散列表应该多大? 假设散列表的大小为2的幂次方。
- 已知,因为倒排页表的表项数量和物理页面数量一样多,所以,如果散列表中的槽数和物理页面数量一样多,那么散列表中的冲突链的平均长度就是1个表项的长度。
- 物理页面的数量:$2^{28}/2^{1}=2^{15}$
- 题目要求小于1,所以散列表的大小应该是$2^{15+1}$
- 如果将FIFO页面置换算法用到4个页框和8个页面上,若初始时页框为空,访问序列串为0172327103,请问会发生多少次缺页中断?如果使用LRU呢?
- 6,7
- 老化算法:看到这里的时候去回顾一下老化算法和相关的几个算法吧
- 工作集时钟页面置换算法

- 一些置换算法
- NRU,如果R位都为0,看脏位(M或者dirty)
- 二维数组置换经典局部性原则
chater 4
- UNIX中,
open系统调用绝对需要吗?如果没有会怎么样?- 系统调用open的作用是查找给定路径下的文件名,获取对应的inode,再进行后续的文件描述符的创建等操作。如果没有open系统调用,程序无法定位文件系统中的inode,无法进行文件读写的操作。
- 硬链接和符号链接的差别
- 硬链接相对符号链接的优点是 不需要额外的磁盘空间,只需要再inode中增加一个链接计数来跟踪链接的数量;而符号链接需要额外的空间来存储所指向的文件名称;
- 符号链接相对于硬链接的优点:可以指向其他文件系统,其他机器或者是互联网上的文件,而硬链接只能指向自己分区内的文件。
- 考虑一个块大小为4KB,使用自由列表(free list method)的4TB的磁盘,多少个块地址可以被放进一个块中?
- 这道题要把块地址存进大小为4KB的块中,那么就要先得到每个块地址有多少位。
- $2^{44}/2^{14}=2^{30}$,也就是30bits -> 32 bits(4bytes)就可以表示块地址,所以一个块中可以存放1024个块地址
- 一个空闲块位图开始时和磁盘分区首次初始化类似,除首块被根目录使用,其余全0,系统总是从最小编号的盘号开始寻找空闲块,所以在有6块的文件A中写入之后,该位图为1111 1110 0000 0000。
- 写入有5块的B文件,位图为1111 1111 1111 0000
- 删除A:1000 0001 1111 0000
- 写入8块的C:1111 1111 1111 1100
- 删除B:1111 1110 0000 1100
- 考虑一个10个数据块的磁盘,这些数据块从块14到23。有两个文件f1, f2,第一个数据块分别是22和16.给定FAT表项如下:哪些数据块被分配给f1和f2?(14,18);(15,17);(16,23);(17,21);(18,20);(19,15);(20,-1);(21,-1);(22,19);(23,14);(x,y)表示存储在表项x中的值指向y
- f1: 22->19->15->17->21->-1
- f2: 16->23->14->18->20->-1
- 一个UNIX系统使用4KB磁盘块和4字节磁盘地址。如果每个i节点中10个直接表项,一个间接表项,一个双重间接表项,一个三重间接表项,一个文件最大大小是多少?
- $(10+1024+1024^2+1024^3)*4KB=4TB$

- 打开inode,打开文件;
chapter 6
- 某一系统有两个进程和三个相同的资源,每个进程最多需要2两个资源,这种情况下有没有可能发生死锁?
- r>=p(m-1)+1,这里r=3,p=2,m=2,所以不会发生死锁
- 最坏情况是每个进程都有m-1个资源,并且需要另一个资源。如果此时还剩下一个资源那么足以让某个进程完成并释放其所有资源
- 若保持该状态是安全状态,x的最小值是多少?
- 先算出需求矩阵,然后从x=0开始推演
- 一种预防死锁的方法是去除占有和等待条件。在本书中,假设在请求一个新的资源之前,进程必须释放所有它已经占有的资源(假设可能)。然而这样做会引入危险:竞争的进程得到了新的资源却失去了原有的资源;改进?
- 在请求资源的时候,如果不能得到所有资源,就释放已经占有的资源,然后重新请求所有资源;如果新资源可获得,那么保留原有资源并获取新资源
- 解释死锁、活锁和饥饿的差别
- 以下各项工作是在四个I/O软件层的哪一层完成的?
a. 为一个磁盘读操作计算磁道,扇区,磁头。- device driver
b. 为设备寄存器写命令 - device driver
c. 检查用户是否允许使用设备 - device-indepence os software
d. 将二进制整数转换为ASCII码方便打印 - user-level I/O software
- device driver
考虑一个包含16个 tracks 和400个 cylinders 的 disk。该 disk 分成4个100个 cylinders 的 zone。不同的zone分别有160、200、240和280个 sectors。每个 sector 512 bytes。如果 disk 旋转速度是 7200 rpm,相邻cylinder 之间的 average seek time 是 1 ms. 计算Disk capacity, optimal track skew, and maximum data transfer rate。
- capacity of zone1:$16100160*512=13107200 bytes$
- capacity of zone2:$16100200*512=16384000 bytes$
- capacity of zone3:$16100240*512=19660800 bytes$
- capacity of zone4:$16100280*512=22937600 bytes$
- sum = 72089600 bytes
A rotation rate of 7200 rpm means there are 120 rotations/sec. In the 1 msec track-to-track seek time, 0.120 of the sectors are covered. In zone 1, the disk head will pass over 0.120 × 160 sectors in 1 msec, so, optimal track skew for zone 1 is 19.2 sectors. In zone 2, the disk head will pass over 0.120 × 200 sectors in 1 msec, so, optimal track skew for zone 2 is 24 sectors. In zone 3, the disk head will pass over 0.120 × 240 sectors in 1 msec, so, optimal track skew for zone 3 is 28.8 sectors. In zone 4, the disk head will pass over 0.120 × 280 sectors in 1 msec, so, optimal track skew for zone 3 is 33.6 sectors.
MDTR计算步骤如下:
计算每个磁道的数据量:这是通过将每个扇区的数据量乘以每个磁道的扇区数量来得到的。对于每个扇区512字节和每个磁道100个扇区,每个磁道的数据量是512 * 100 = 51200字节(或50KB)。
计算最大数据传输率:这是通过将每个磁道的数据量乘以磁盘的旋转速度来得到的。
磁盘请求以cylinder 10,22,20,2,40,6和38的顺序进入磁盘驱动器。柱面seek time 为6ms,以下各个算法的seek time?(20开始)
- FCFS、SJF、Elevator
- (a) 10 + 12 + 2 + 18 + 38 + 34 + 32 = 146 cylinders = 876 msec.
(b) 0 + 2 + 12 + 4 + 4 + 36 +2 = 60 cylinders = 360 msec.
(c) 0 + 2 + 16 + 2 + 30 + 4 + 4 = 58 cylinders = 348 msec
