本文首发于知乎,现迁移至个人博客。
整理自 CS336 的 Lecture5(GPUs):聚焦 GPU 底层工作逻辑、性能核心瓶颈、机器学习负载的 GPU 优化方法,同时拆解 FlashAttention 的底层优化逻辑。基于课程内容梳理。
GPU 硬件架构解析
GPU vs CPU 核心区别
- CPU:少量快核架构,核心设计目标是优化延迟(让单个/少量线程的执行速度更快),硬件搭配复杂的控制逻辑与缓存体系,分支预测能力强,适配通用计算、复杂逻辑型任务。
- GPU:海量慢核架构,核心设计目标是优化吞吐(同时处理海量并行线程、完成大规模数据计算),硬件以海量微小计算单元(ALU)为主,控制/缓存体系极简,分支处理开销大,专为矩阵乘法、深度学习训练/推理等密集型并行计算设计。 > 核心差异根源:设计目标不同,决定了二者硬件架构、性能特性与适配场景的本质区别。

GPU 结构
- SM(Streaming Multiprocessors,流式多处理器):GPU的核心计算单元,是并行计算的基本载体,高性能GPU(A100/H100)集成大量SM(如A100含128个SM),SM数量直接决定GPU的并行计算能力;每个SM独立执行线程块,且配备专属的共享内存与L1缓存。
- 执行单元:每个SM包含多类型计算单元,基础的INT32(整数)、FP32(单精度浮点)计算单元,以及针对低精度计算的FP16/BF16/FP8单元、专为矩阵乘法设计的张量核心(Tensor Core);同时每个SM配备4个Warp调度器,负责线程束的调度执行。
- 存储单元:SM内部集成共享内存(Shared Memory)与L1缓存,是GPU高速存储的核心,也是后续性能优化的关键载体。
GPU 的逻辑执行模型
GPU的并行执行基于线程-线程块-线程束(Warp) 三级层级结构,遵循SIMT(单指令多线程) 执行模型,是GPU并行计算的核心逻辑:
- 线程(Thread):GPU并行计算的最小单元,所有线程执行相同的指令,仅处理不同的输入数据,是实际完成计算的载体。
- 线程块(Block):由多个线程组成(如256线程/块),每个线程块独占一个SM的计算资源与共享内存,且仅能在单个SM上执行,线程块内的线程可通过共享内存实现高速数据交互。
- 线程束(Warp):GPU的最小执行粒度,固定由32个连续编号的线程组成,SM的调度器以线程束为单位分配计算资源,一个线程束内的所有线程同时执行指令。
SIMT 模型的特点:同一线程束的线程指令同步,硬件无需为每个线程单独解码指令,大幅降低编程与硬件调度成本。
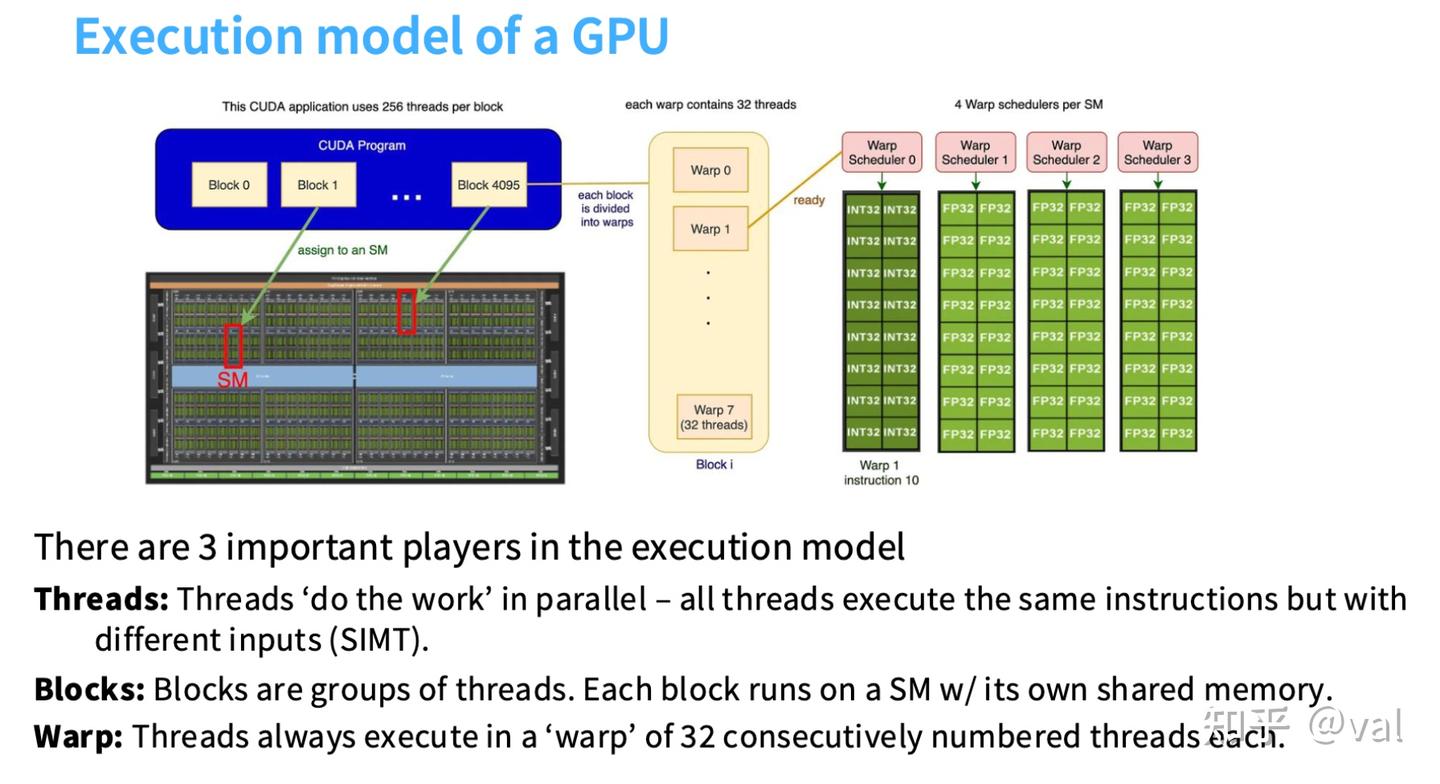
GPU 的逻辑内存模型
GPU采用分层存储架构,存储器与SM的物理距离越近,访问速度越快、延迟越低,编程的核心原则是善用内存层级结构,减少对慢速全局内存的访问,各层级内存的核心特性与访问规则如下:
- 线程私有内存:寄存器(Registers)、本地内存(Local Memory),仅当前线程可读写,CPU(主机端)无访问权限;寄存器是速度最快的GPU内存,用于存储线程的临时计算数据。
- 线程块私有内存:共享内存(Shared Memory),仅所属线程块内的所有线程可读写,CPU无访问权限;共享内存集成在SM内,访存延迟极低(GA100架构读23时钟周期/写19时钟周期),是GPU性能优化的核心载体。
- 全局共享内存:全局内存(Global Memory)、常量内存(Constant Memory),整个GPU网格内的所有线程可访问(常量内存为只读),CPU可通过数据传输实现读写;全局内存是GPU的外接DRAM,访存延迟极高(GA100架构290时钟周期),是GPU访存瓶颈的核心。
核心访问规则:所有线程可自由访问自身的寄存器和所属块的共享内存;块与块之间的数据交互,仅能通过写入全局内存实现。理想的编程思路是:让线程块在同一小块数据上完成计算,先将数据加载到共享内存,全程优先在共享内存中做数据交互与计算。
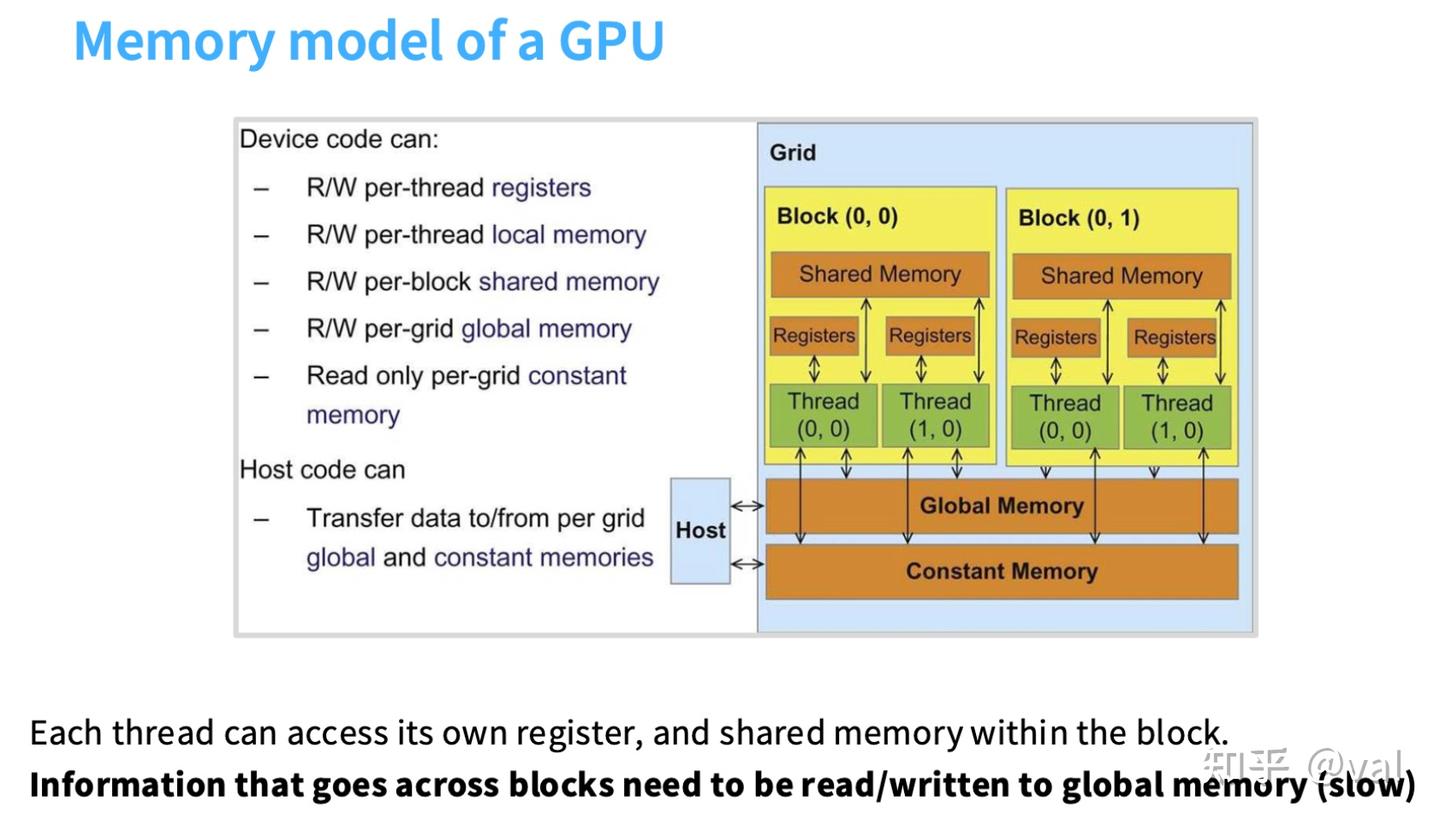
TPU
TPU与GPU同属AI加速器,核心架构高度相似,均遵循「外部慢速内存+内部高速内存+专用计算硬件」的设计逻辑,核心硬件均包含标量单元(负责指令分发,类似简易CPU)、向量单元(处理逐元素操作)、矩阵乘法专用单元(TPU的MXU/GPU的Tensor Core,是算力核心),且均使用高带宽内存(HBM)存储权重、激活值等数据。
GPU与TPU的核心差异:
- 计算单元数量:GPU的SM数量更多,TPU的张量核心(TC)数量更少,但二者的矩阵乘法性能相近;
- 执行模型:GPU有线程束(Warp)的最小执行粒度,TPU无此概念,仅以块为单位执行;
- 网络互连:二者的加速器间组网方式存在差异,影响大规模并行计算的性能;
- 适配性:GPU通用性更强,可适配各类并行计算任务;TPU为谷歌定制化硬件,对Transformer类大模型的矩阵乘法任务适配性更优。
Strengths of the GPU model
- 可扩展性强:通过增加SM数量,可线性提升GPU的并行计算能力,轻松应对高负载的并行计算任务,是GPU算力持续缩放的核心基础;
- 编程难度低:SIMT模型让开发者无需手动管理海量线程的同步与调度,仅需编写单线程逻辑,硬件自动实现并行化,大幅降低并行编程门槛;
- 线程轻量高效:线程本身的状态信息极少,启动、暂停、切换的开销几乎可以忽略,GPU可通过调度海量线程掩盖访存延迟(让计算单元在等待数据时始终有任务可执行);
- 硬件加速针对性强:专为矩阵乘法设计的张量核心,让GPU的矩阵乘法性能远超其他浮点操作,完美适配深度学习的核心计算需求。
矩阵乘法与GPU内存瓶颈
- 矩阵乘法是GPU的核心优势:张量核心(Volta架构起引入)让GPU的矩阵乘法速度比其他浮点操作快10倍以上,深度学习模型(尤其是LLM)的核心计算为矩阵乘法,若设计非矩阵乘法主导的神经网络,将无法利用GPU的硬件加速优势,性能会大幅下降;
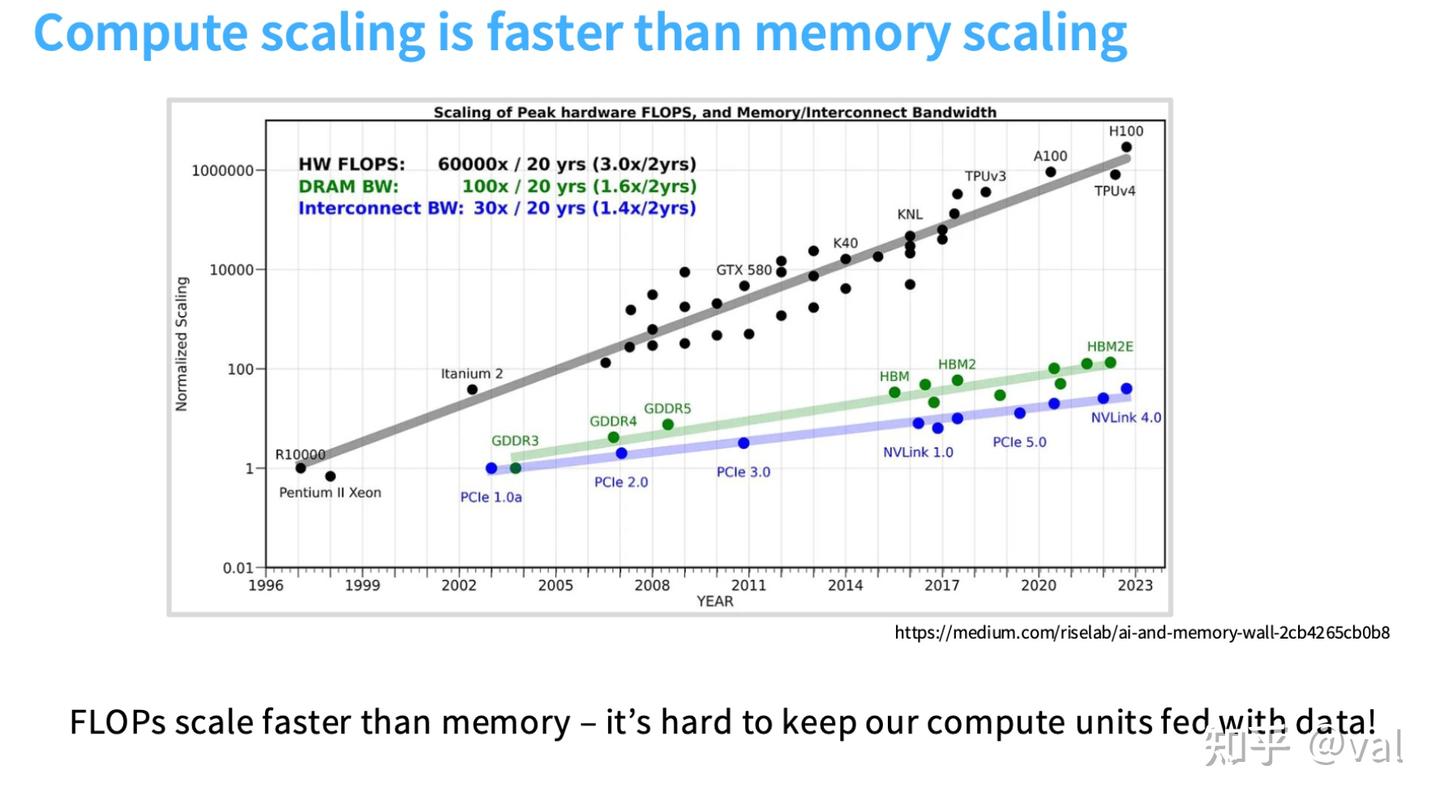
- 内存成为GPU的核心性能瓶颈:GPU的计算能力(尤其是矩阵乘法)发展极快,但内存带宽/容量的增长速度远跟不上算力增长——过去20年,GPU硬件峰值算力(FLOPS)提升60000倍,全局内存带宽仅提升100倍,互连带宽仅提升30倍;DRAM的物理特性决定其难以继续快速扩展,算力与访存的差距还会持续扩大。 > 核心结论:设计硬件高效的深度学习算法,必须高度重视内存层面的考量,核心关键是善用GPU的内存层级结构,减少对慢速全局内存的访问。
Making ML workloads fast on GPU
Roofline model(屋顶线模型)
屋顶线模型是分析计算任务在GPU/CPU上性能瓶颈的核心工具,可直观判断任务的瓶颈类型(访存受限/计算受限),并回答“为什么有的程序运行快,有的运行慢”,为性能优化指明方向。
- 横轴:操作强度(Operational Intensity),单位flops/byte,表示从内存中读取1字节数据,能在硬件中完成的浮点运算次数,本质是计算量/访存量;操作强度越靠右,说明算法的计算量越大,对数据移动的依赖越小。
- 纵轴:吞吐量(Throughput),单位gflops,表示硬件每秒能完成的浮点运算次数,反映硬件的计算能力。
- 模型中的关键线条:
- 斜线部分(内存带宽限制):从左下到右上的斜线代表不同层级存储器的访存带宽极限,斜线越低,代表访存带宽越慢(如GPU主存斜线远低于GPU共享内存);当程序的性能落在斜线上时,说明任务是访存受限(Memory Bound),性能瓶颈为数据从内存搬运到计算单元的速度。
- 水平线部分(计算算力限制):代表硬件的最大计算吞吐量极限(如GPU ALU/张量核心的峰值算力);当程序的性能落在水平线上时,说明任务是计算受限(Compute Bound),性能瓶颈为硬件的计算能力,即便数据供给足够快,也无法突破硬件的算力极限。
典型计算任务的瓶颈分析:
- 稠密矩阵乘法:操作强度极高,位于图的最右侧,处于计算算力限制的水平线下方,是计算受限任务,这也是GPU对稠密矩阵乘法有巨大加速作用的核心原因;
- 稀疏矩阵乘法:操作强度较低,位于图的左侧,处于内存带宽限制的斜线上,是访存受限任务;因稀疏矩阵需频繁读取不连续的内存数据,无法充分利用硬件算力,性能受限于内存带宽。 > 深度学习核心结论:绝大多数机器学习/大模型负载为访存受限任务,因此GPU性能优化的核心方向是提升操作强度、减少内存访问。
GPU 性能优化的 6 大核心技巧
GPU优化的核心原则:确保所有内存访问都是必要的,最大限度减少对缓慢全局内存的访问,以下技巧按“是否与内存相关”分类,Trick0为非内存相关优化,其余均围绕内存访问优化展开。
Trick 0: Control divergence(控制分支发散)
唯一非内存相关的优化技巧,根源于GPU的SIMT执行模型:
- 核心规则:一个线程束(32线程)内的所有线程会同步执行相同的指令,仅处理不同数据;若代码中使用条件分支(if/else),GPU会暂停所有不按主流程执行的线程,仅让符合条件的线程执行,分支结束后再唤醒暂停线程,这一过程会带来显著的性能开销。
- 优化思路:尽量避免在高度并行的线程束内使用复杂的条件语句,让同一线程束的所有线程执行相同的计算逻辑,减少分支发散。
Trick 1:低精度计算(Low Precision)
核心原理:通过降低数据的存储位数,减少数据搬运量,提升算法的算术强度,同时利用GPU张量核心的低精度硬件加速。
- 位数越少→数据字节数越少→内存访问量越少→算术强度(arithmetic intensity)越高;例:FP32做ReLU操作,内存强度为8 bytes/FLOP;FP16仅需4 bytes/FLOP,算术强度直接翻倍。
- 硬件加速:GPU张量核心(Volta架构起)专为低精度矩阵乘法设计,FP16/BF16/FP8的矩阵乘法速度比普通FP32运算快10倍以上。
- 精度选择原则:
Trick 2:算子融合(Operator Fusion)
核心原理:将多个连续的逐元素操作融合为单个CUDA核函数,让数据仅从全局内存读取一次、计算完成后仅写入一次,避免数据在“内存-计算单元”之间反复往返,减少无用的内存访问。
- 反例:计算,朴素实现需启动5个独立的CUDA核函数,数据需反复读写全局内存,访存开销极大;
- 优化效果:融合为单个核函数后,数据仅一次读写,访存开销大幅降低;
- 便捷实现:现代深度学习编译器可自动完成简单的算子融合(如PyTorch的
torch.compile),推荐全面使用,优化效果显著且无需手动修改代码。
Trick 3:重计算(Recomputation / Activation Checkpointing)
核心思想:以算力换内存/访存,是深度学习反向传播的核心优化技巧,解决激活值存储的访存开销问题。
- 问题根源:反向传播需要使用前向传播的所有激活值,若将激活值全部存储在全局内存,会带来巨大的存储与读取开销,导致算法的操作强度极低;
- 优化策略:前向传播时不存储激活值,反向传播时重新计算所需的激活值,用少量的额外算力消耗,换取海量的内存读写开销减少;
- 课程案例:3层Sigmoid堆叠的反向传播,存储激活值需8次内存读写,重计算后仅需4次,访存开销减少5/8。
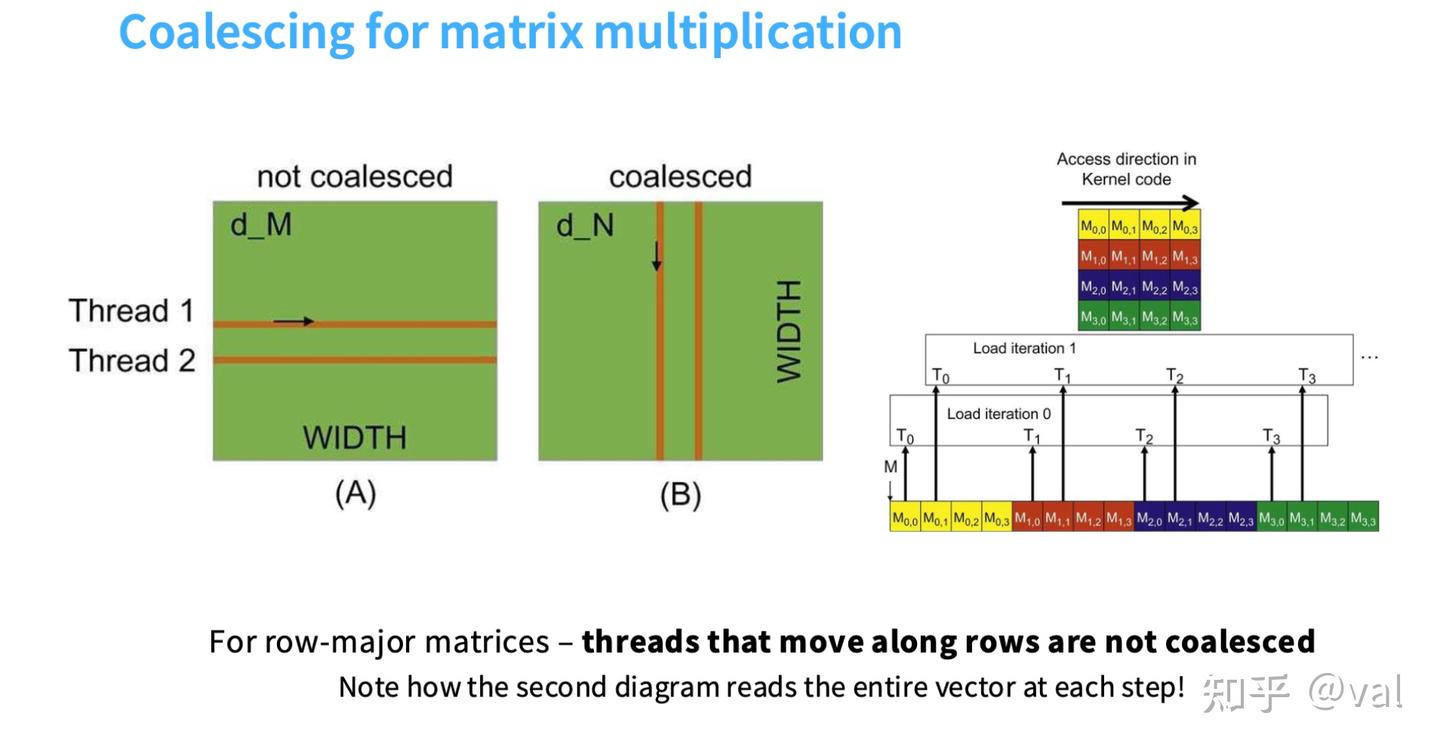
Trick 4:内存合并访问(Memory Coalescing)
核心原理:利用DRAM的突发模式(Burst Mode),让同一线程束的线程访问连续的内存地址,实现一次DRAM请求完成所有访存,充分利用内存带宽。
- DRAM突发模式:DRAM的读取并非按单个字节进行,而是以突发段(Burst Section) 为单位(实际场景中为128字节及以上);访问某一地址时,该地址所在突发段的所有数据会被一并读取到处理器,未利用的部分会被丢弃,造成带宽浪费。
- 内存合并:若同一线程束的32个线程访问的内存地址均落在同一个突发段内,GPU仅需发起一次DRAM请求,即为“合并访问”,带宽利用率100%。
- 反例:行优先存储的矩阵中,线程沿矩阵行访问时,地址不连续,无法实现内存合并,每个线程都需单独发起DRAM请求,带宽利用率极低,访存效率大幅下降。
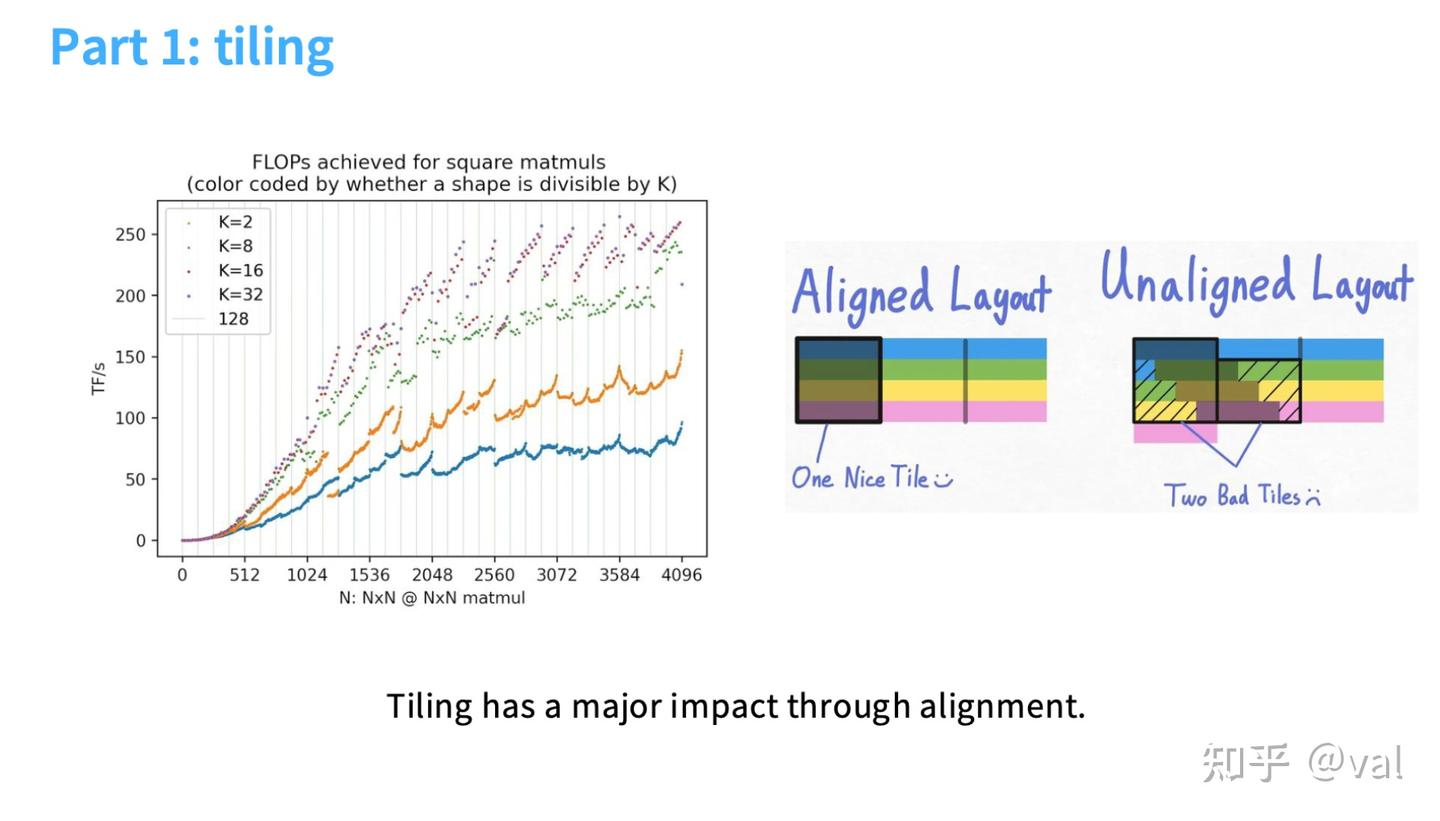
Trick 5:分块(Tiling)
GPU内存优化的核心技巧,核心思想:将大矩阵/大张量切分为小的“分块(Tile)”,先将分块加载到SM的共享内存中,再在共享内存中完成计算,实现数据的复用,最大限度减少对全局内存的访问。
- 核心优势:重复用到的数据从高速的共享内存读取,而非反复读取慢速的全局内存,大幅降低全局访存开销;
- 理论加速效果:无分块的矩阵乘法中,每个输入数据会从全局内存被读取N次(N为矩阵尺寸);分块后仅读取次(T为分块尺寸),全局访存开销直接降低T倍;
- 需要注意的复杂性:
- Wave Quantization(波量化):分块尺寸需能整除矩阵维度,否则会导致部分SM负载不足、硬件利用率大幅下降;
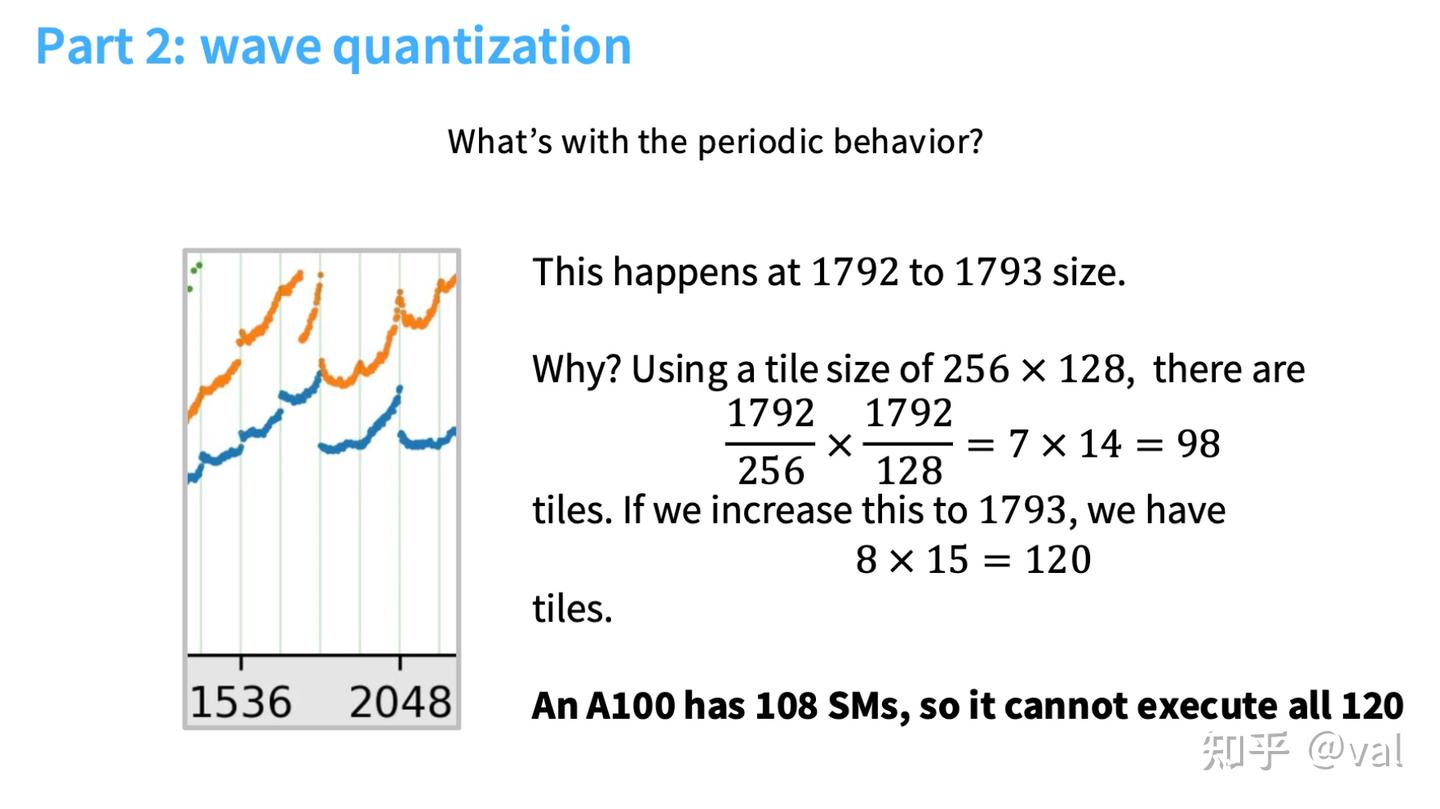
- 实战案例:nanoGPT将词汇量从50257调整为50304(64的最近倍数),虽增加了少量无用的计算维度,但因分块对齐,GPU的SM利用率大幅提升,最终实现25%的性能提升。
LLM的超大规模训练与推理,核心在于对这些底层细节的把控,正是这些优化技巧的组合使用,才让大模型在超大规模下仍能保持良好的性能,因此理解GPU底层优化逻辑对深度学习工程化至关重要。
Flash Attention (这里指的应该是 Flash Attention 1)为什么快
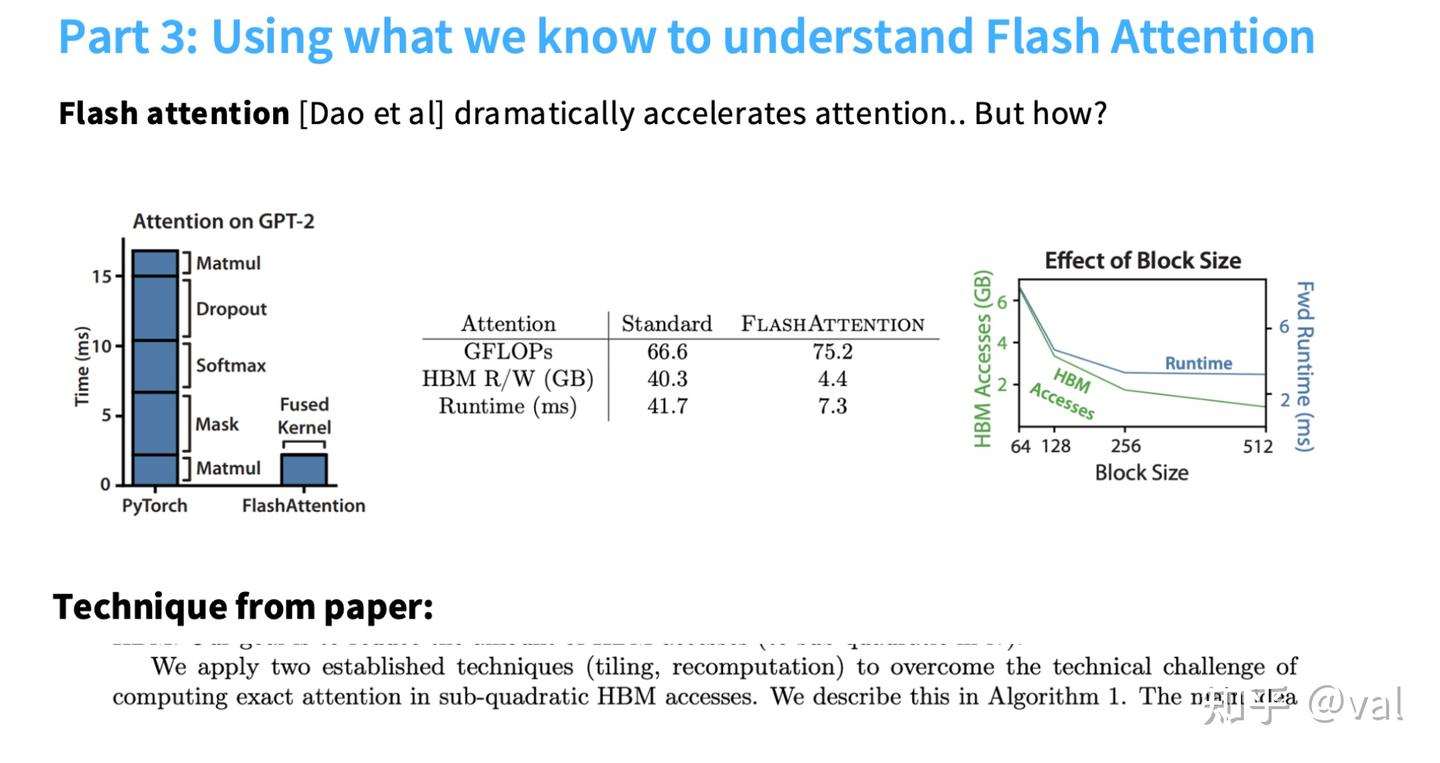
注意力机制是LLM的核心计算模块,标准注意力的计算逻辑为:3次矩阵乘法(Q、K、V)+ 中间的Softmax归一化,其核心性能瓶颈为全局内存(HBM)访存开销过大,而Flash Attention的核心优势是通过融合GPU的各类优化技巧,在保证计算结果精确的前提下,大幅降低HBM访存开销,实现性能的飞跃。
标准注意力与Flash Attention的核心性能对比(课程实测数据)
| 性能指标 | 标准注意力 | Flash Attention |
|---|---|---|
| 算力消耗(GFLOPs) | 66.6 | 75.2 |
| HBM读写量(GB) | 40.3 | 4.4 |
| 运行时间(ms) | 41.7 | 7.3 |
Flash Attention仅小幅增加算力消耗(约13%),但将HBM访存量降低90%以上,运行时间缩短约6倍,性能提升的核心并非创新算法,而是对GPU底层优化技巧的极致融合与运用。
Flash Attention的四大关键优化技巧
Flash Attention的核心设计思路是IO感知,充分利用GPU的内存层级结构,将所有优化技巧与注意力的计算逻辑深度结合,核心技巧如下:
- Tiling KQV 矩阵乘(分块计算):将Q、K、V矩阵切分为小分块,按分块将数据从HBM加载到SM的高速共享内存(SRAM),在共享内存中完成注意力分数的内积计算,避免直接在HBM中执行大矩阵运算,从根源上减少全局内存访问;(利用Trick5:分块)
- Online Softmax(增量Softmax计算):解决分块计算中Softmax的全局依赖问题(标准Softmax需要所有数据的最大值和累加和,无法分块计算);通过逐分块维护当前最大值和累加和,利用望远镜求和的方式实现Softmax的增量精确计算,让Softmax可以在分块上独立执行,完美适配分块计算逻辑;
- 算子融合:将指数运算、Softmax的归一化运算与注意力分数的计算融合为单个CUDA核函数,数据仅从共享内存读取一次,避免中间结果的内存读写;(利用Trick2:算子融合)
- 反向传播重计算:前向传播时不存储注意力计算的中间激活值,反向传播时按分块重新计算所需数据,大幅减少反向传播的HBM访存开销;(利用Trick3:重计算)
Flash Attention 是GPU底层优化技巧在注意力机制中的经典落地案例,其所有优化均围绕 减少HBM访存展开,充分利用GPU的共享内存实现数据复用,让注意力机制从“访存受限”向“计算受限”转变,最终实现性能的大幅提升。