本文首发于知乎,现迁移至个人博客。
目录
课程主题:LLM大规模训练的并行计算基础 核心目标:理解超大模型训练的系统复杂度,掌握各类并行化范式及组合使用方法,了解大规模训练的实际落地方案 课程结构:网络基础→LLM并行训练原语→并行化缩放训练大模型
一、LLM网络基础:GPU缩放的局限性与并行硬件/通信基础
1. GPU单卡缩放的两大核心限制
单卡算力和显存的增长速度远落后于LLM参数规模的扩张,成为超大模型训练的核心瓶颈。
- 计算限制:单卡算力提升依赖精度优化(FP32→BF16/Int8,~16x)、复杂指令(~12.5x)、制程(~2.5x)等,整体增益超1000x,但仍无法匹配千亿/万亿参数模型的计算需求;全球最快超算已达艾级算力(Exaflops),是大规模训练的核心算力支撑。
- 内存限制:2018-2022年LLM参数从千万级飙升至千亿级(GPT-3 175B、Megatron-Turing NLG 530B),单GPU显存无法容纳主流大模型,必须通过多卡/多机拆分内存需求。
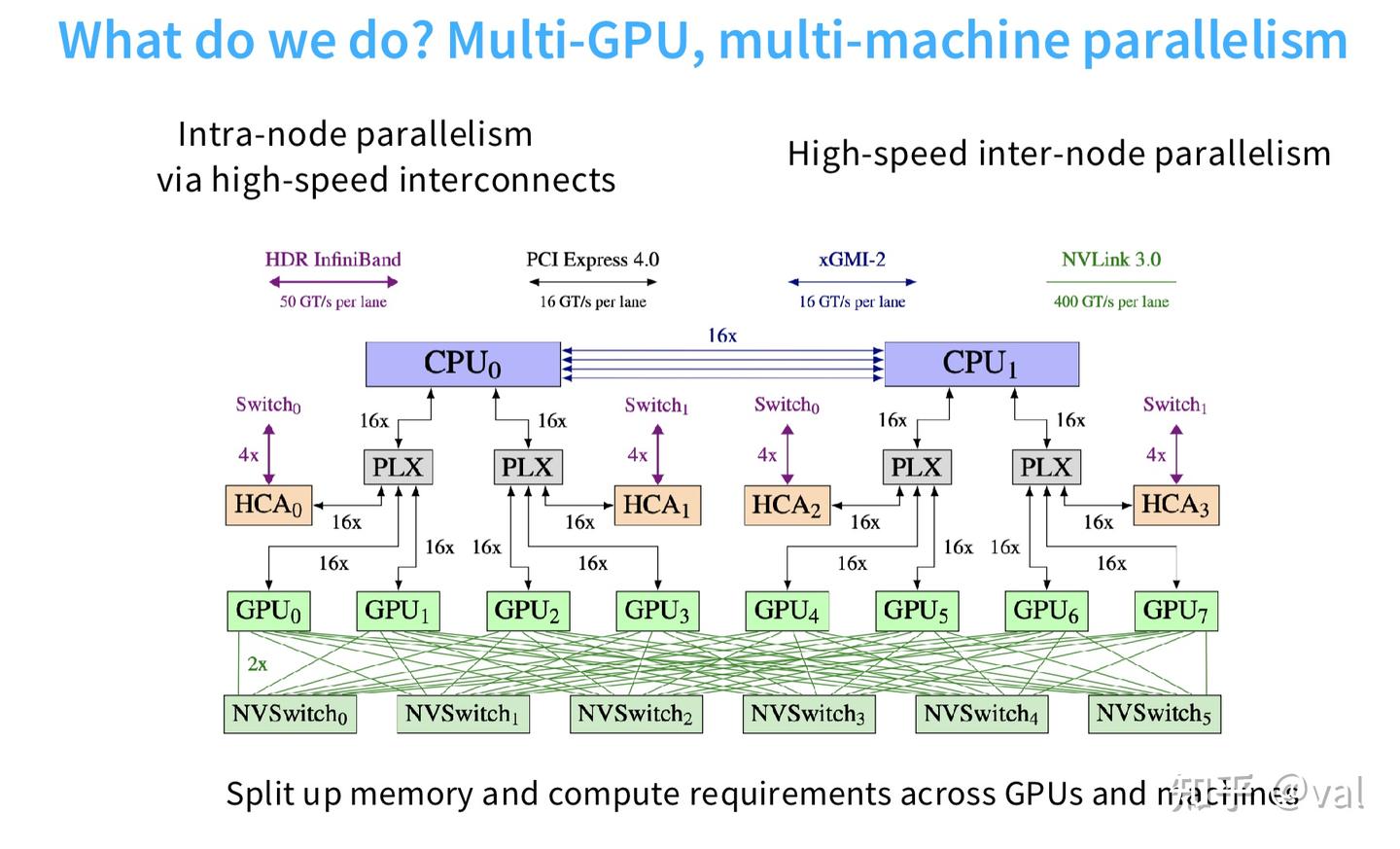
2. 多卡/多机并行的硬件互联
通过不同层级的高速互联实现节点内和节点间并行,不同互联技术的带宽差异显著(单通道):
- NVLink3.0:400 GT/s(节点内GPU高速互联,如单机8卡)
- HDR InfiniBand:50 GT/s(节点间互联)
- PCI Express 4.0/xGMI-2:16 GT/s
- 核心架构:单机8卡通过NVSwitch实现高速互联,多机通过InfiniBand交换机连接,256卡内可实现GPU全连接。
3. 集体通信原语(Collective Communication)
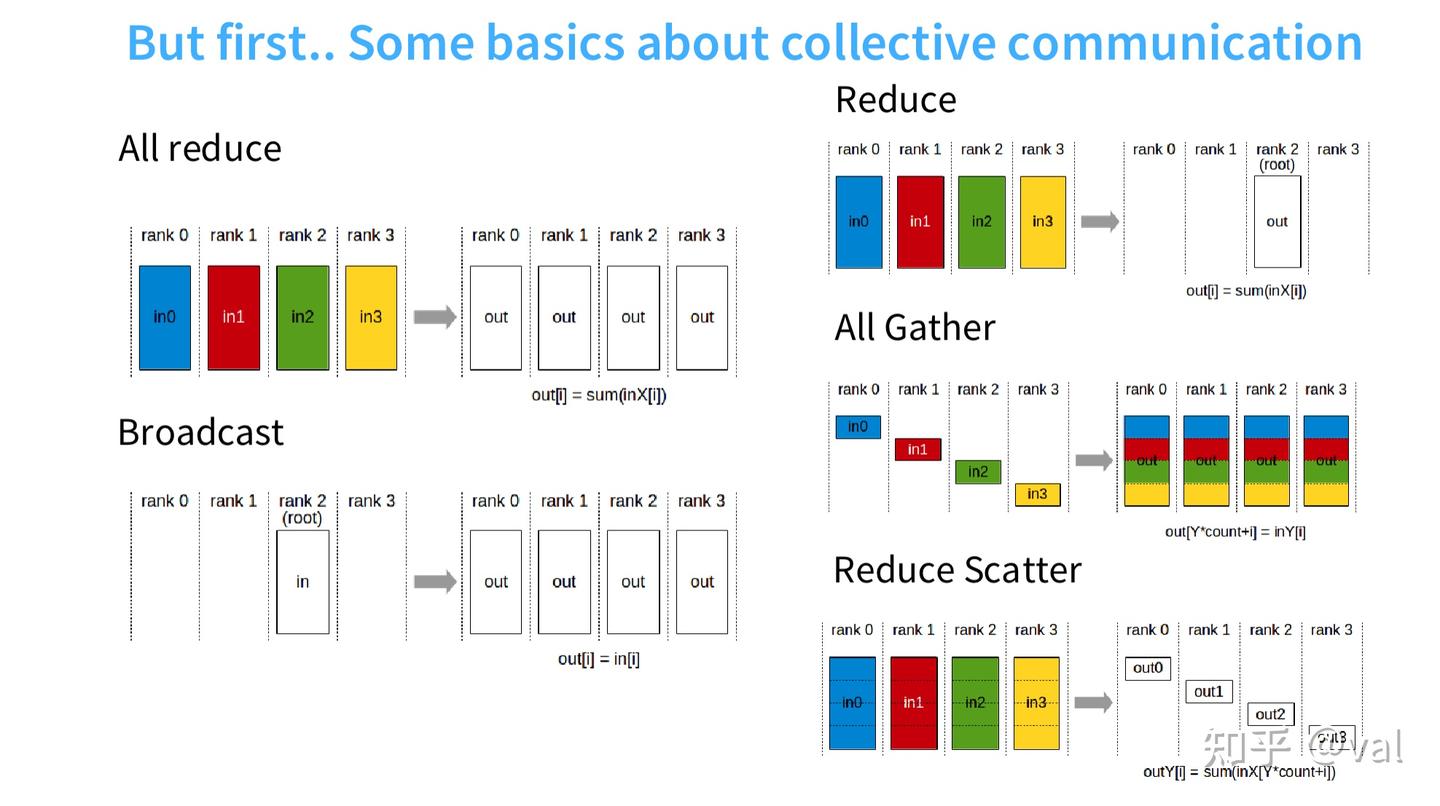
并行训练的基础操作,所有多卡/多机数据同步均基于此,核心操作及定义如下:
| 操作 | 核心逻辑 | 详细描述 |
|---|---|---|
| 全局归约(All Reduce) | 多节点数据归约(如求和),结果同步至所有节点 | 假设有 4 台机器、4 个进程(rank),各持一段数据。我们要做归约(比如求和),并把结果广播到每台机器。通信开销大约是待归约数据总量的 2 倍。 |
| 广播(Broadcast) | 单节点数据复制到所有节点 | 从进程 2 取一份数据,复制到所有其他进程。通信开销约为输出总量的 1 倍。 |
| 归约(Reduce) | 多节点数据归约,结果仅同步至根节点 | 多份输入求和,结果只发给一台机器。 |
| 全局收集(All Gather) | 各节点持有的数据分片,聚合为完整数据同步至所有节点 | 每个进程负责一部分参数(比如进程 0、1、2、3 各持一段),把各自的片段发给所有其他进程,最终每台机器都拿到完整分段集合。 |
| 归约散射(Reduce Scatter) | 多节点数据归约后,分片同步至对应节点(全局归约的“拆分版”) | 把每一行数据求和,结果只发给对应进程。这是全局归约的 “分段版本”。 |
全局收集与归约散射是基础原语,很多并行算法都构建在它们之上。这里有一个关键等价关系:全局归约 = 归约散射 + 全局收集,在带宽受限场景下,这是全局归约的最优实现方式,通信成本完全一致。 如果你要做全局归约:假设有 A、B、C、D 四张 GPU,各处理不同数据,产生不同梯度,需要把梯度求和再发回所有 GPU—— 这是经典的数据并行操作。 这件事可以拆成两步:先归约散射,再全局收集。归约散射把每一行求和,结果分别留在 GPU 0、1、2、3;再做全局收集,把结果复制回所有 GPU。最终每张卡都拿到参数某一部分的完整和,再同步给其他节点。 在带宽受限场景下,这是最优方案。全局归约的最优性能,基本等价于归约散射 + 全局收集的性能。
课堂Q&A Q:上一页是不是说,用归约散射+全局收集比直接用全局归约更好? A:二者完全等价。并行梯度下降中全局归约是自然操作,但可拆分为归约散射+全局收集,带宽层面无任何性能损失,该结论是后续ZeRO并行的核心基础。
4. TPU与GPU的通信设计差异
二者组网架构不同,适配的并行场景存在差异,核心区别:
- GPU:256卡内实现全连接组网,单机8卡通过NVLink高速互联,超过256卡后需通过叶/脊交换机实现慢速互联,存在带宽瓶颈;
- TPU:采用环形网格(Toroidal Mesh),仅相邻芯片高速通信,极易扩展,集体通信(All Reduce/Reduce Scatter)实现效率与GPU全连接持平;
- 性能:H100 SuperPod相比A100,256卡下二分带宽提升9x,归约带宽提升4.5x,节点内并行效率更高。
大规模训练的计算单元从单GPU升级为数据中心,多机缩放的核心目标是实现内存线性缩放(最大模型参数随GPU数线性增长)、计算线性缩放(算力随GPU数线性增长),且所有并行算法均基于简单的集体通信原语实现。
二、LLM并行训练的核心原语
目前业界主要有三种并行策略: 第一种:数据并行(Data Parallelism, DP)把模型参数完整复制到每张 GPU,不拆参数;只把批次(batch)拆分,不同机器处理不同批次切片。具体实现有很多细节。 第二种:模型并行(Model Parallelism, MP)不让每张卡都存完整模型。模型太大时,全量复制会出问题。需要精巧地把模型切开,每张卡只负责模型的一部分。 第三种:**激活并行(Activation Parallelism, AP)**平时我们不太关心激活值,因为 PyTorch 都封装好了。但模型变大、序列长度变长后,激活内存会成为巨大瓶颈。想训练超大批次的超大模型,必须管理激活内存,也需要拆分。 把三者结合,我们就能在海量机器下优雅地扩展计算与内存。
1. 数据并行(Data Parallelism)
1.1 朴素数据并行(Naïve DDP)
- 核心思路:将模型参数完整复制到所有GPU,仅拆分训练批次(Batch),各GPU计算分片批次的梯度,通过全局归约同步梯度后更新参数;
- 公式基础:基于SGD, ,将B拆分到M个GPU,各计算 后同步;
- 优缺点:计算缩放友好(各GPU获B/M样本),但无内存缩放(所有GPU存完整参数/优化器状态),通信开销为2×参数量/批次(全局归约),批次足够大时可掩盖通信开销;
- 内存问题:显存占用极严重,需存储5份权重,单参数达16字节(BF16参数2B+BF16梯度2B+FP32主权重4B+Adam一阶矩4B+二阶矩4B),优化器状态是显存占用大头。
1.2 ZeRO(零冗余优化器):解决数据并行的显存瓶颈
拆分数据并行中显存密集的部分(优化器状态/梯度/参数),利用归约散射+全局收集的等价关系,在不增加通信成本的前提下实现显存缩放,分3个阶段,均基于PyTorch FSDP框架实现。
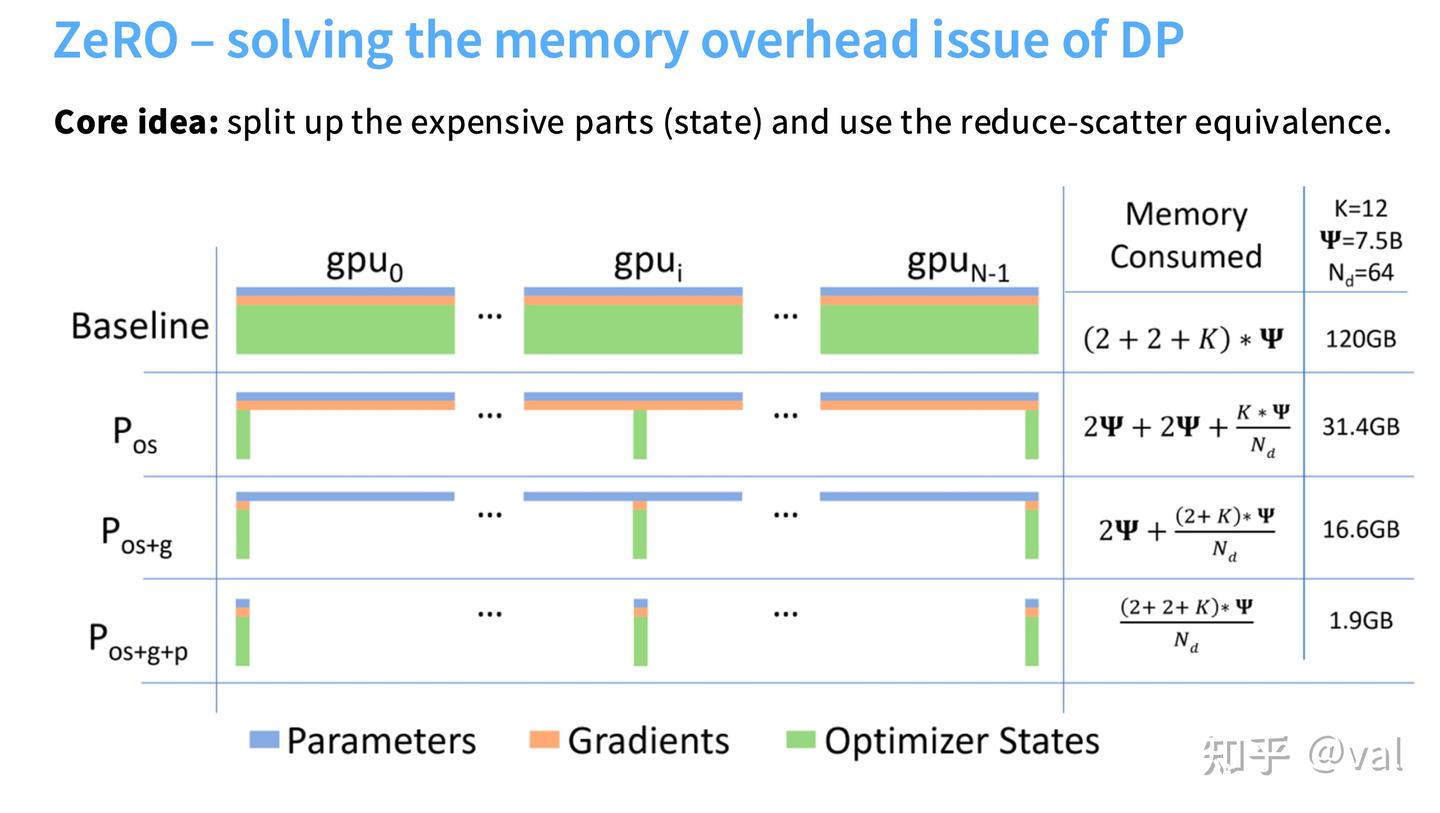
| ZeRO阶段 | 核心拆分内容 | 显存消耗(7.5B参数/64卡) | 通信成本 | 关键步骤 |
|---|---|---|---|---|
| Stage 1 | 优化器状态分片 | 31.4GB(基线120GB) | 2×参数量 | 1.各GPU计算完整梯度;2.归约散射梯度;3.各GPU更新分片参数;4.全局收集参数 |
| Stage 2 | 优化器状态+梯度分片 | 16.6GB | 2×参数量 | 1.反向传播时逐层计算梯度并归约;2.释放无用梯度;3.更新参数+全局收集 |
| Stage 3(FSDP) | 优化器状态+梯度+参数全分片 | 1.9GB | 3×参数量 | 1.前向/反向按需请求/发送参数;2.增量通信/计算;3.参数使用后立即释放 |
课堂Q&A Q1:数据并行下每张卡都要算完整梯度、做全局归约,怎么还能分片优化器状态? A1:这是ZeRO的核心巧思——每张卡仍持有完整参数+梯度,可计算完整梯度更新,但仅负责更新自己分片的优化器状态对应的参数,最后通过全局收集同步更新后的参数,无需全量复制优化器状态。
Q2:这里的参数量通信开销是单机还是总计? A2:总计。比如1/4参数要被发送3次,四组合计为总通信量;此前提到的全局归约2倍参数量的开销,同样是总计。
Q3:AdamW似乎假设参数相互独立,但模型是连通的,分片单独更新会不会有问题? A3:AdamW是对角更新,确实并非完全考虑参数间依赖,学界也提出了K-FAC等二阶优化方法,但至今未替代Adam。该假设不影响并行框架的有效性,是工程上的合理取舍。
Q4:能不能修改Adam,存更高阶矩,同时靠分片省内存? A4:理论上可行,可将复杂优化器状态按GPU数拆分,但后续其他组件也会随GPU数扩展,优化器状态仍会是显存瓶颈,无实际工程价值。
ZeRO核心优势:Stage1/2在带宽受限场景下近乎免费(通信成本与朴素DDP一致),Stage3仅增加50%通信成本,却实现显存大幅缩减;8×A100 80G节点上,Stage3可训练53.33B参数模型,而基线仅6.66B。
1.3 ZeRO Stage3(FSDP)细节
核心特点:全量分片参数/梯度/优化器状态,前向/反向按需预取参数,使用后立即释放,通过计算与通信重叠掩盖开销。
课堂Q&A Q1:FSDP预取的权重存在哪里?GPU显存不是已经满了吗? A1:需要在GPU中预留专门的缓冲区存储预取权重;此外,FSDP未解决激活内存问题,激活值会占据大量显存,这是后续需要解决的核心痛点。
Q2:FSDP分片参数后,和模型并行的本质区别是什么? A2:核心区别在通信对象——FSDP会频繁传递参数,而模型并行的参数固定在对应GPU,仅传递激活值;模型并行的通信焦点是激活,而非参数,这是二者的本质不同。
Q3:参数只存在一台机器,为什么还要做全局收集,用广播不行吗? A3:理论上广播可实现相同效果,此处用全局收集是工程实现细节(部分场景下层并非完全分布在单GPU),核心逻辑是将分片参数同步至所有GPU,保证计算连续性。
1.4 数据并行的固有问题
- 并行度受批次大小限制:GPU数不能超过批次大小,否则通信开销剧增;
- 批次增益递减:超过临界批次后,梯度噪声降低的收益消失,训练效率不再提升;
- ZeRO3的局限性:原理最优,但速度较慢,无法降低激活内存,这是数据并行的核心痛点。
2. 模型并行(Model Parallelism)
核心思路:将模型参数拆分到不同GPU(而非复制),仅传递激活值(而非参数,与ZeRO3的核心区别),实现不依赖批次大小的内存缩放,分为流水线并行和张量并行两类,对应模型的两种拆分方式。
2.1 流水线并行(Pipeline Parallelism):沿深度/层拆分模型
流水线并行是最直观的切法:神经网络是一层层的,按层切开,每张卡负责一部分层。
- 基础形式(层并行):将模型层拆分到不同GPU,前向时激活值在GPU间依次传递,反向时梯度反向传递;
- 问题很明显:GPU利用率极低,n卡仅1/n时间工作,存在巨大通信气泡;
- 优化方案:微批次流水线:将批次拆分为微批次,处理完一个微批次后立即传递激活值,同时开始下一个微批次计算,气泡时间占比=(阶段数-1)/微批次数,批次越大,气泡越小;

- 零气泡流水线:将反向传播拆分为激活反向传播(强串行依赖)和权重梯度计算(无依赖),将权重梯度计算填充到气泡中,实现GPU100%利用率,但工程实现极其复杂;
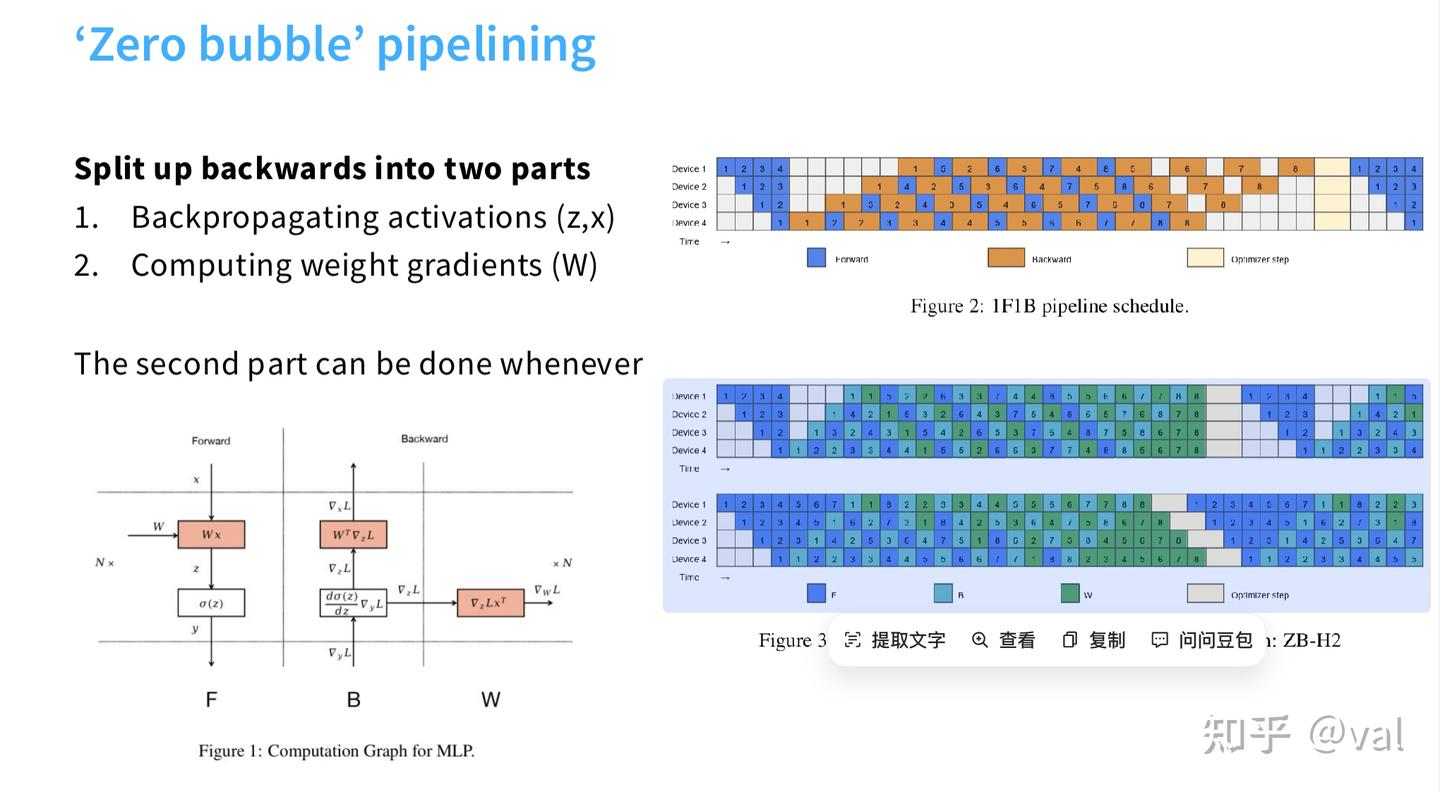
- 优缺点:显存缩放友好(拆分激活+参数),通信为点对点(仅传递激活值,规模为b×s×h),适合节点间慢速互联;但依赖大批次,工程配置复杂,是大规模训练的“最后选择”。
2.2 张量并行(Tensor Parallelism):沿宽度拆分模型
如果说流水线并行是沿着 深度(层)切,那么张量并行就是沿着矩阵乘的宽度切,把大矩阵分解为子矩阵,做部分和。 核心思路:利用矩阵乘法的可分解性,将大矩阵拆分为子矩阵,各GPU计算子矩阵乘法后聚合结果,是节点内并行的最优选择。
- 核心原理:以MLP为例,将参数矩阵A拆为A1/A2、B拆为B1/B2,各GPU计算XA1/XA2→Y1/Y2,再计算Y1B1/Y2B2,最后通过全局归约求和得到最终结果;前向/反向仅在关键节点做一次全局归约同步;
- 适用场景:单机8卡内(NVLink高速互联),这是张量并行的最优甜区;8卡以上吞吐暴跌(16卡-42.7%、32卡-65.6%);
- 优缺点:无通信气泡,不依赖大批次,实现复杂度低(仅需包装模型);但通信开销大(每层8×bsh的全局归约),要求低延迟/高带宽互联,仅适用于节点内。
课堂Q&A Q1:张量并行和流水线并行能同时使用吗? A1:可以,且是工业界超大模型训练的标配。通常先做单机内的张量并行,再在跨机间叠流水线并行;目前仅DeepSeek V3是特例,只用流水线并行,不用张量并行。
Q2:是不是单机内用张量并行,跨机用流水线+数据并行? A2:是。典型组合策略:单机内做张量并行,跨机结合流水线并行+数据并行;只有当模型无法通过张量并行+ZeRO3容纳时,才会启用流水线并行。
3. 激活并行(Activation Parallelism):解决激活内存瓶颈
3.1 激活内存的问题
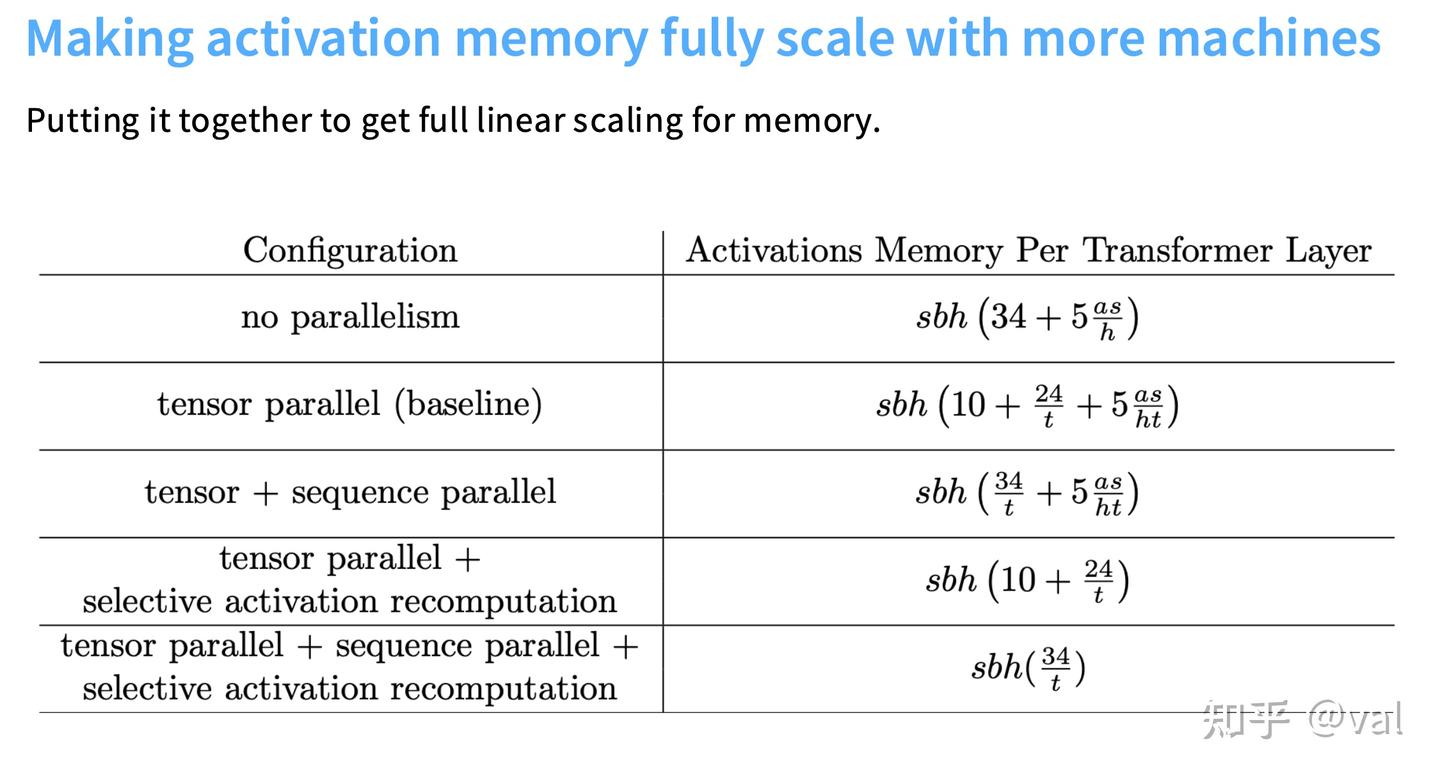
张量/流水线并行可线性缩减参数/优化器状态内存,但激活内存持续增长,成为超大模型训练的新瓶颈;单Transformer层激活内存公式:
Activations memory per layer $ =s b h\left(10 + \frac{24}{t}+5 \frac{a s}{h}\right)$

- 张量并行后仍有10sbh的不可缩减值,来自LayerNorm、Dropout等逐点操作,无法通过矩阵拆分并行化。
3.2 序列并行(Sequence Parallelism):实现激活内存线性缩放 核心思路:逐点操作(LayerNorm/Dropout)在序列维度彼此独立,将序列拆分到不同GPU,各GPU处理分片的逐点操作,通过全局收集/归约散射同步结果:
- 前向: =全局收集, =归约散射;
- 反向:操作完全反转;
- 效果:结合张量+序列并行后,激活内存实现完全线性缩放,最终单图层激活内存降至(t为张量并行卡数)。
课堂Q&A Q:Transformer一层层堆叠,计算图越来越复杂,会不会成为GPU间通信的瓶颈? A:大概率不会。张量并行是层内纯并行,不依赖计算图的整体结构;流水线并行若存在多分支计算图,反而可能增加并行机会,提升利用率。
4. 其他并行策略
适用于特定场景,是三大核心并行的补充:
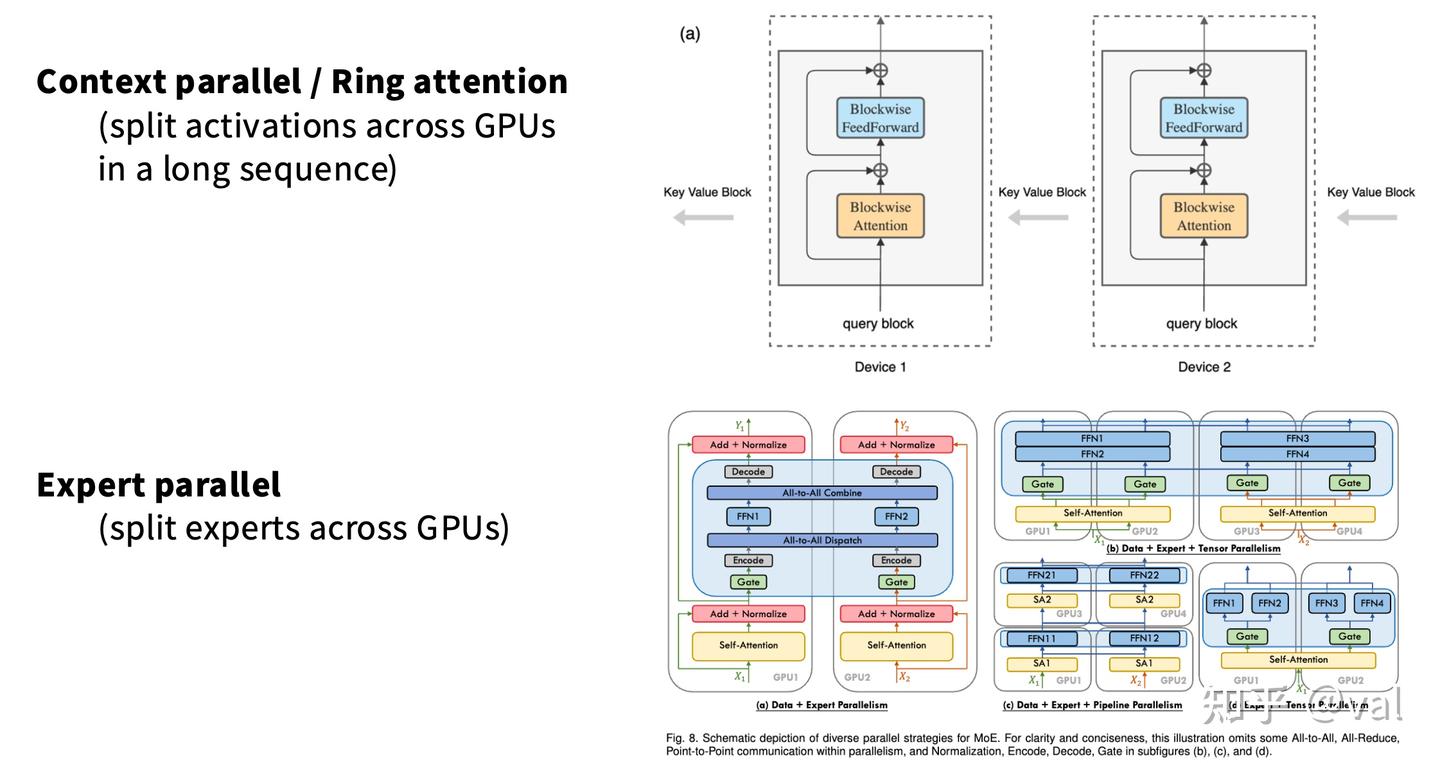
- 上下文并行/环形注意力(Ring Attention):拆分长序列Attention的计算/激活开销,将K/V在多机间环形传递,各机处理部分Query,是Flash Attention的分布式版本,适用于长上下文LLM训练;
- 专家并行(Expert Parallelism):将大MLP拆分为多个稀疏激活的小专家MLP,分片到不同GPU;核心区别是专家稀疏激活,需做路由,通信不可预测,但概念与张量并行一致,适用于MoE模型。
三、利用并行化缩放训练大模型:组合策略与实际落地
1. 各类并行策略的核心对比
不同并行策略在同步开销、显存、带宽、批次依赖、易用性上差异显著,需根据硬件/模型规模组合:
| 并行策略 | 同步开销 | 内存缩放 | 通信带宽 | 批次依赖 | 易用性 |
|---|---|---|---|---|---|
| DDP/ZeRO1 | 每批次 | 无 | 2×参数量 | 线性依赖 | 极高 |
| FSDP(ZeRO3) | 每个FSDP块3× | 线性 | 3×参数量 | 线性依赖 | 极高 |
| 流水线并行 | 每个流水线阶段 | 线性 | 激活值(bsh) | 线性依赖 | 极低 |
| 张量+序列并行 | 每个Transformer块2× | 线性 | 每层8×激活值全局归约 | 无依赖 | 中等 |
2. 批次大小的核心作用
谷歌有一本非常好的 TPU 并行文档,里面有一张神图:
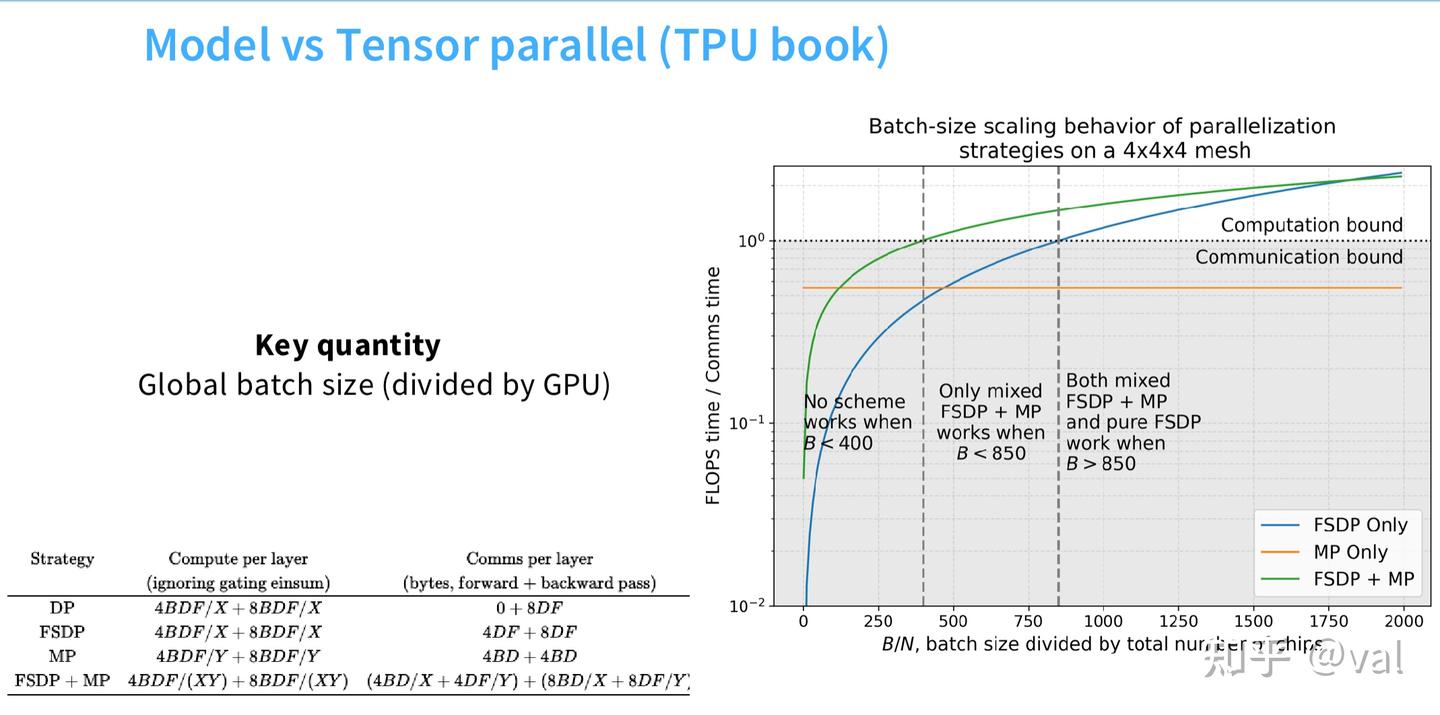
核心变量还是批次大小。批次是大规模训练的稀缺资源,批次与GPU数的比值决定最优并行策略:
- 批次过小:通信受限,所有策略效率极低;
- 批次适中:FSDP+张量并行最优,实现计算受限(算力无浪费);
- 批次足够大:纯数据并行 / FSDP即可,计算时间远大于通信时间;
- 批次不足的解决方案:梯度累积,用显存换等效大批次,减少跨机同步频率,提升通信效率。
3. 3D/4D并行:组合策略的实用经验法则
把这些组合起来,就是业界常说的3D 并行、4D 并行。这是工业界大规模训练的标准流程,核心原则是先放内存,再扩算力,步骤如下:
- (1)让模型+激活放进显存(硬性前提)
- (2)全力扩展总算力
- (3)批次优化:若批次过小,开启梯度累积,提升通信效率。
4. 大规模训练的经典案例与实践结论
4.1 Megatron-LM(1.7B-1T参数):3D并行的标杆
- 张量并行先扩至8卡后封顶,是最优配置;
- 模型规模超过单机显存后,逐步提升流水线并行;
- 数据并行随流水线并行提升而逐步降低(批次被流水线消耗);
- 效果:实现算力线性缩放,单GPU吞吐保持平稳,理论峰值算力利用率达40%-52%。
4.2 主流LLM的并行策略选型 工业界均采用组合并行,无单一策略,核心选型如下:
- OLMo/Dolma(7B):纯FSDP(ZeRO3),单机可容纳;
- DeepSeek V1:ZeRO1+张量+序列+流水线并行;V3:16路流水线+64路专家并行+ZeRO1;
- Yi:ZeRO1+张量+流水线并行;Yi-lightning:将张量并行替换为专家并行(MoE);
- Llama3 405B(8192/16384卡):8路张量+1/16路上下文+16路流水线+64/128路数据并行,按带宽需求排序并行维度(TP>CP>PP>DP),DP最容忍高延迟;
- Gemma 2(TPU):ZeRO3+张量+序列+数据并行,TPU的环形网格让模型并行扩展更远。
4.3 大规模训练的工程问题:硬件故障 千亿/万亿参数训练的核心挑战不仅是算法,还有容错架构:
- Llama3 405B训练中,54天内出现766次中断,78%为硬件问题;
- 主要故障:故障GPU(30.1%)、GPU HBM3内存(17.2%)、网络交换机(8.4%);
- 更严重问题:静默数据损坏(GPU无声出错,输出垃圾数据),直接废掉整个训练。
5. 关键实践结论
- 张量并行8卡是全局最优,无论批次大小,8卡内吞吐损失可接受;
- 激活重计算(Flash Attention)利大于弊:虽增加算力,但可大幅降低激活内存,支持更大批次,掩盖通信开销;
- 流水线并行是最后选择:仅当模型无法通过张量+ZeRO3容纳时使用,工程复杂度极高;
- 混合精度训练是标配:BF16计算+FP32梯度累积/主权重,平衡显存与训练稳定性。
四、课程核心总结
- 单卡已死:LLM规模超过一定阈值后,必须采用多卡/多机并行,无单一解决方案,需组合数据/模型/激活并行;
- 并行的核心是权衡:需平衡内存、带宽、批次大小三大稀缺资源,根据硬件互联特性选择并行策略;
- 工业界标准流程:3D/4D并行,先通过张量并行+ZeRO3/流水线让模型放进显存,再通过数据并行扩算力,批次不足时用梯度累积优化;
- 工程与算法同等重要:大规模训练不仅需要并行算法,还需容错架构解决硬件故障、静默数据损坏等工程问题;
- 硬件决定并行选型:GPU适合256卡内的全连接并行,TPU适合超大规模的环形网格并行,硬件互联带宽是并行策略的核心约束。