本文首发于知乎,现迁移至个人博客。
本讲主题是:关于语言模型架构和训练,你不想了解的一切。从2017-2025年主流LLM的演进实践中,提炼现代语言模型的架构共识、可落地的超参数规则,以及工程化的训练/推理优化技术,覆盖多数课程不会深入的工程细节。
一、Transformer 架构演进与现代共识
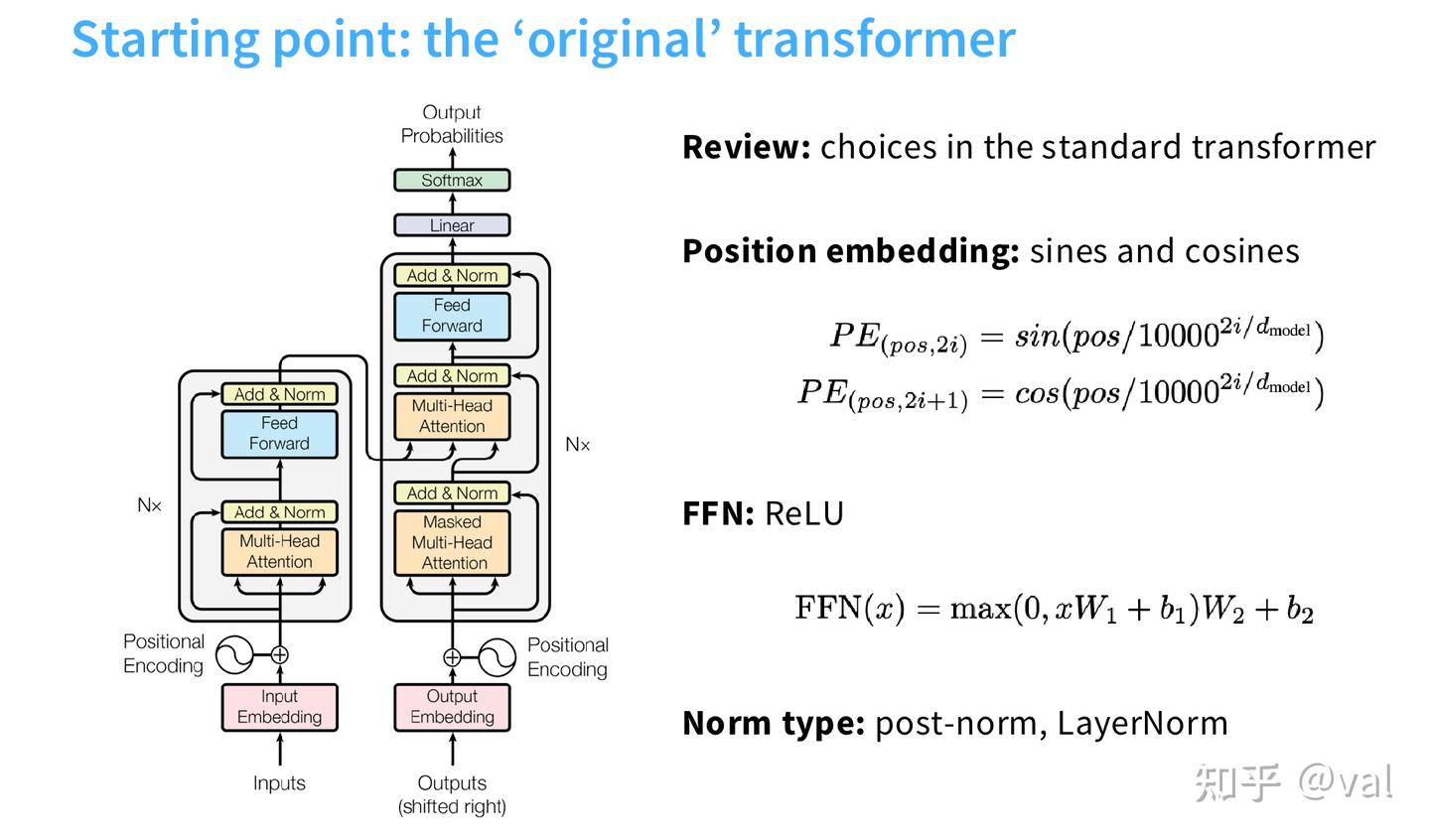
下面是讲师Tatsu H 整理的表格,涵盖了从 2017 年原始 Transformer 到 2025 年最新模型的关键设计(课程最后有全景图)。宏观来看其实很多设计选择尚未形成完全共识,虽然近几年出现了 “类 LLaMA 架构” 的趋同趋势,但不同模型仍有差异 ,包括激活函数、前馈网络、注意力变体、位置编码等。

1.1 原始Transformer vs 课程实现的现代变体
cs336 要实现的是经工程优化的 Transformer 现代变体,相比原始版本,在归一化位置、位置编码、激活函数、偏置项上做了全维度调整,且明确了输入输出张量的标准形状。
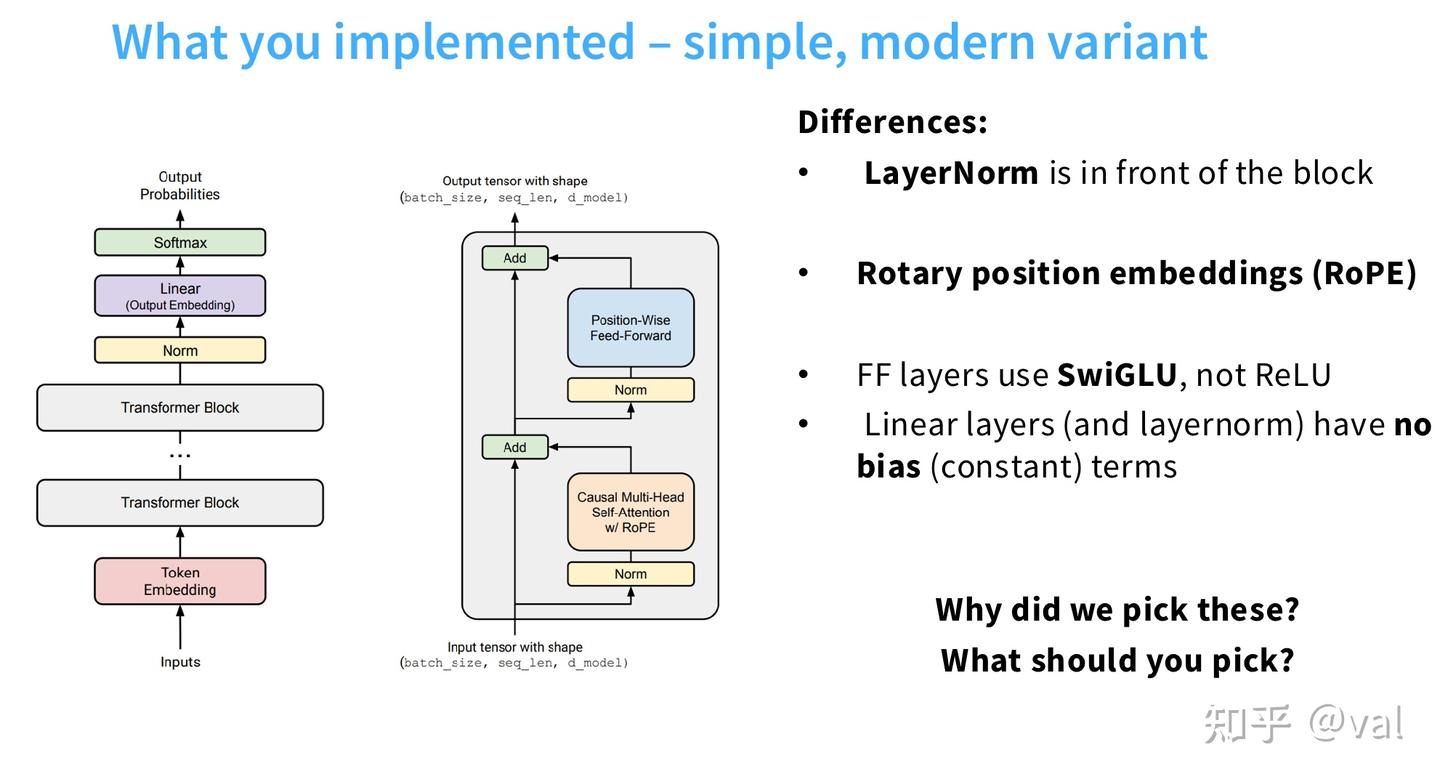
- 归一化:从块后移至块前(Pre-Norm),新增Token Norm对输入嵌入归一化;
- 位置编码:替换为RoPE旋转位置编码,集成在因果多头自注意力中;
- 激活函数:ReLU替换为SwiGLU门控激活;
- 偏置项:所有线性层、归一化层均移除偏置项;
- 输出层:新增Output Embedding的残差Add操作,提升训练稳定性。
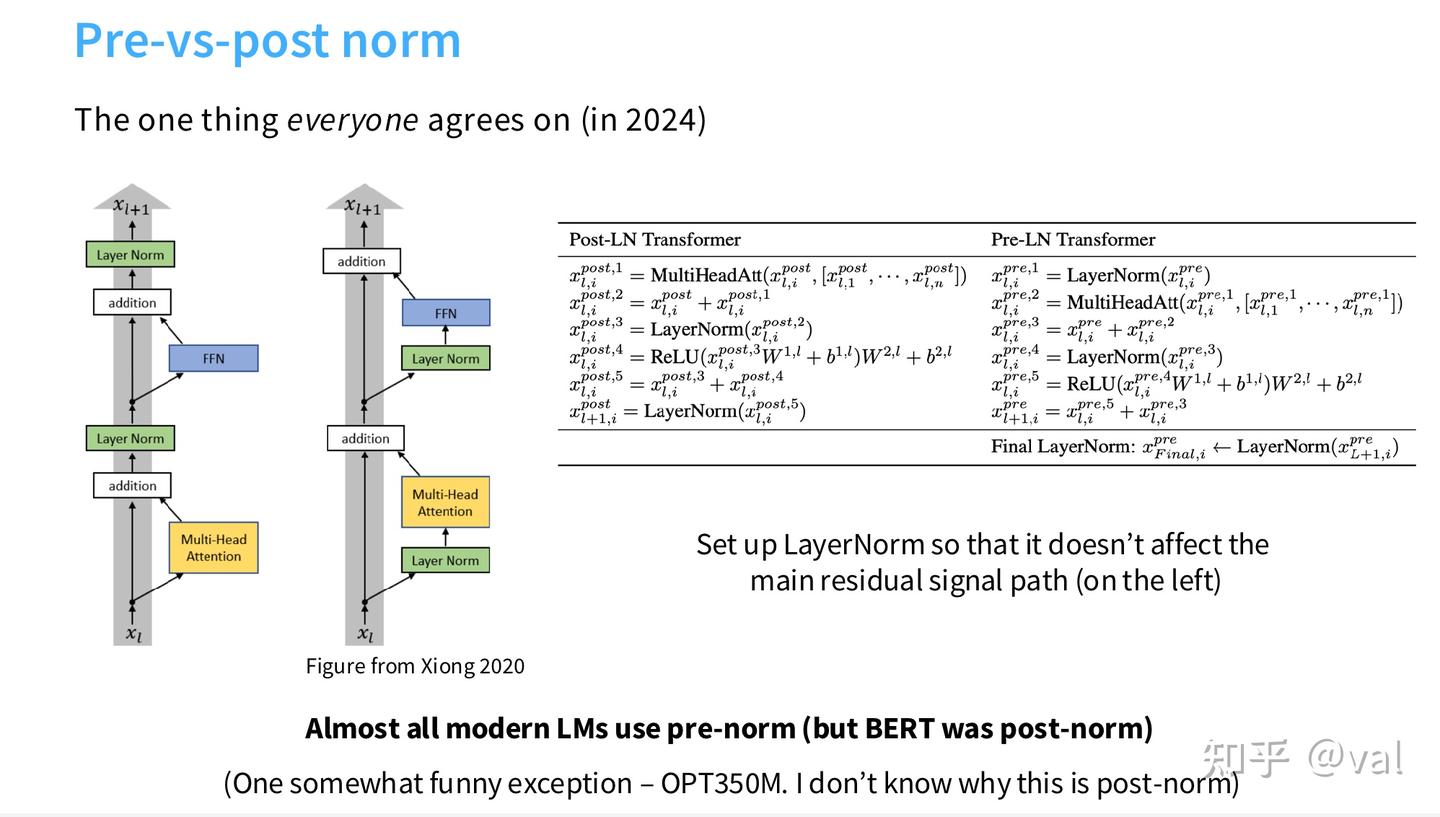
1.2 归一化设计:训练稳定性的核心
归一化是大模型训练稳定的基础,2024-2025年所有主流模型均采用 Pre-Norm + RMSNorm组合,替代了原始的Post-Norm + LayerNorm。 (1)Pre-Norm 完全替代 Post-Norm Pre-Norm让梯度传播更顺畅,无需复杂的学习率预热即可稳定训练,Post-Norm 易出现梯度爆炸。
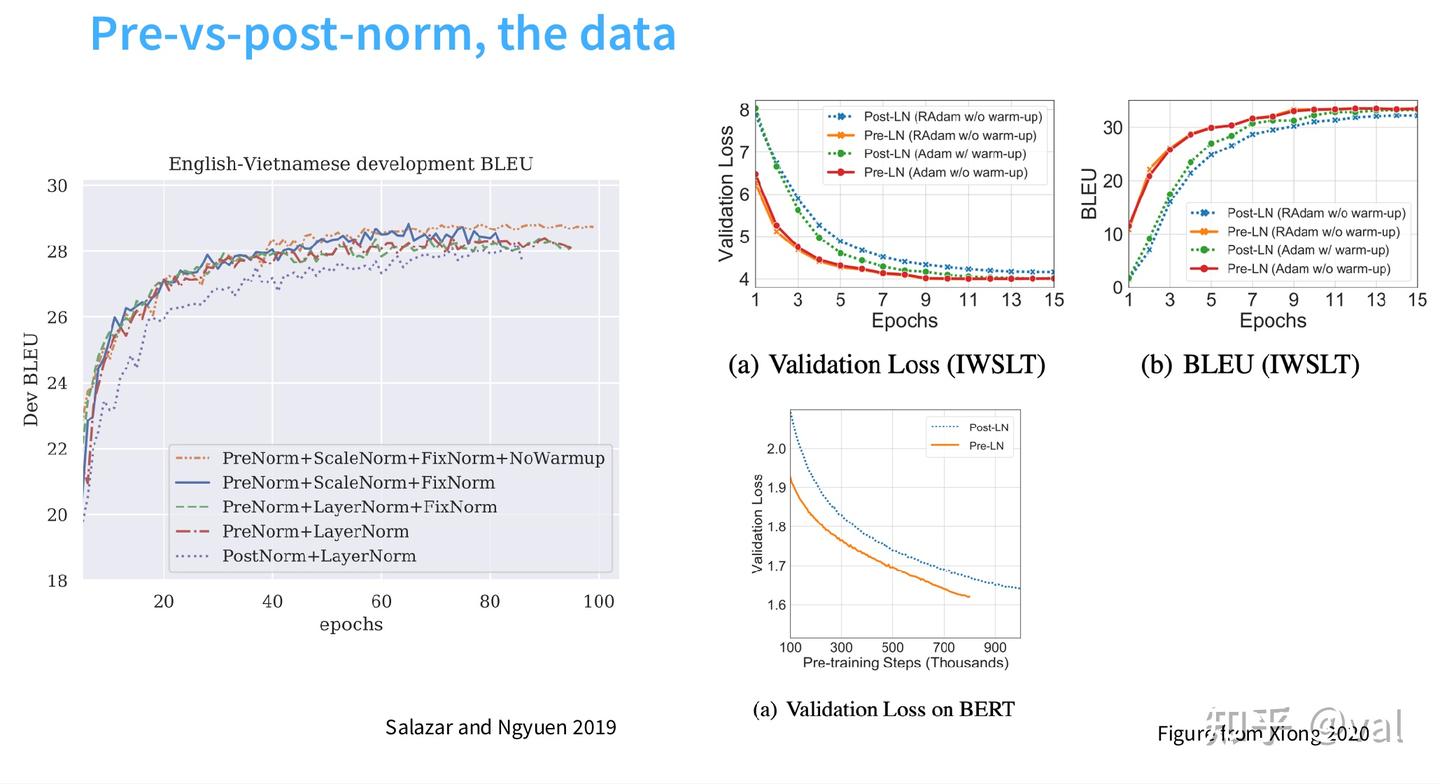
有实验佐证 Pre-Norm在翻译、预训练任务中,损失下降速度和最终性能均显著优于Post-Norm,无预热也能保持训练稳定。
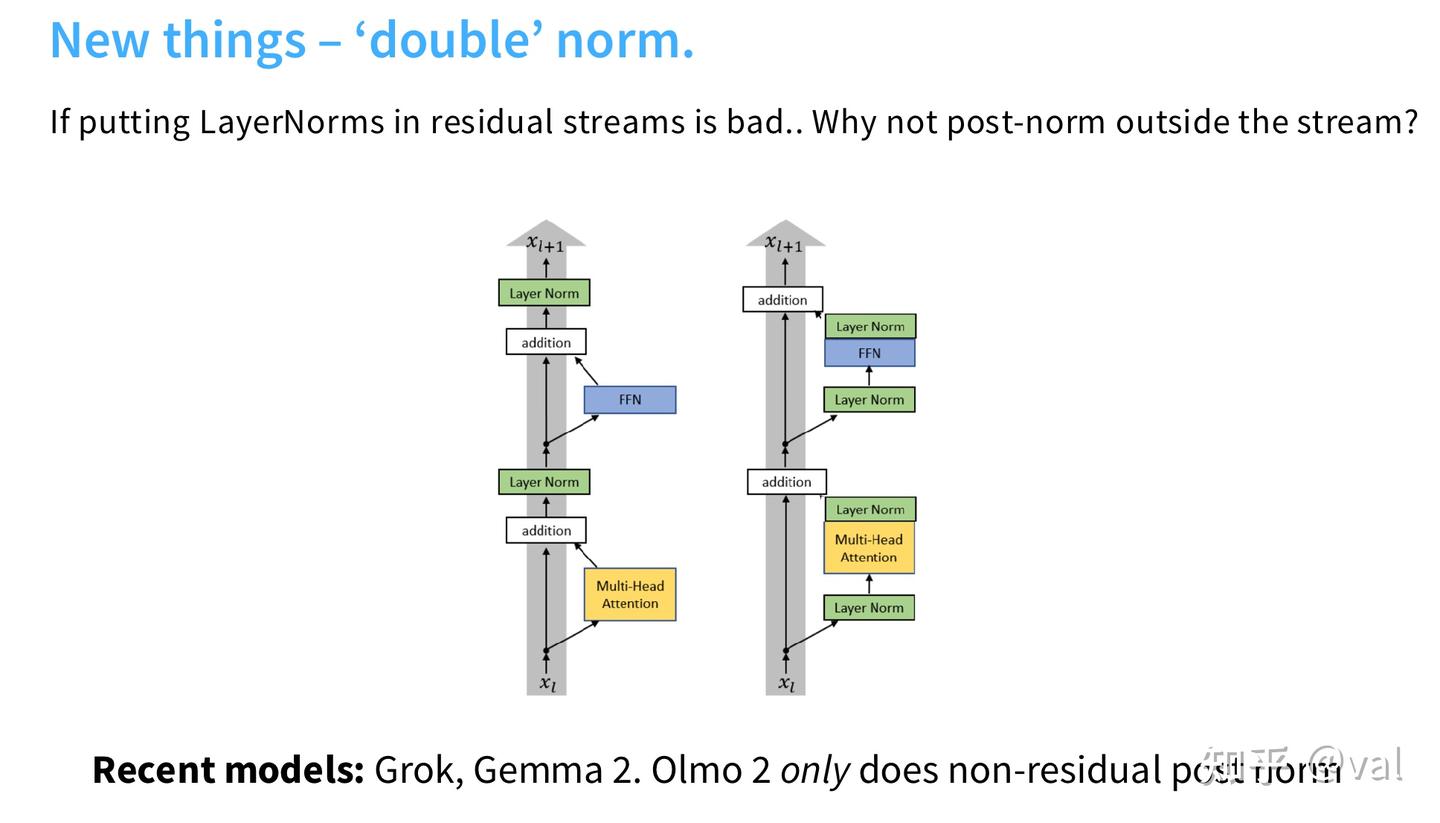
还有一种变体是 Double Norm(Grok、Gemma2采用),在Pre-Norm基础上,于子层计算后新增一层Norm,进一步提升大模型训练稳定性;Olmo2仅在非残差部分做后置Norm。
(2)RMSNorm 替代 LayerNorm 为什么要用 RMSNorm 替代 LayerNorm 呢?
- LayerNorm: $$$$
- RMSNorm: $$$$
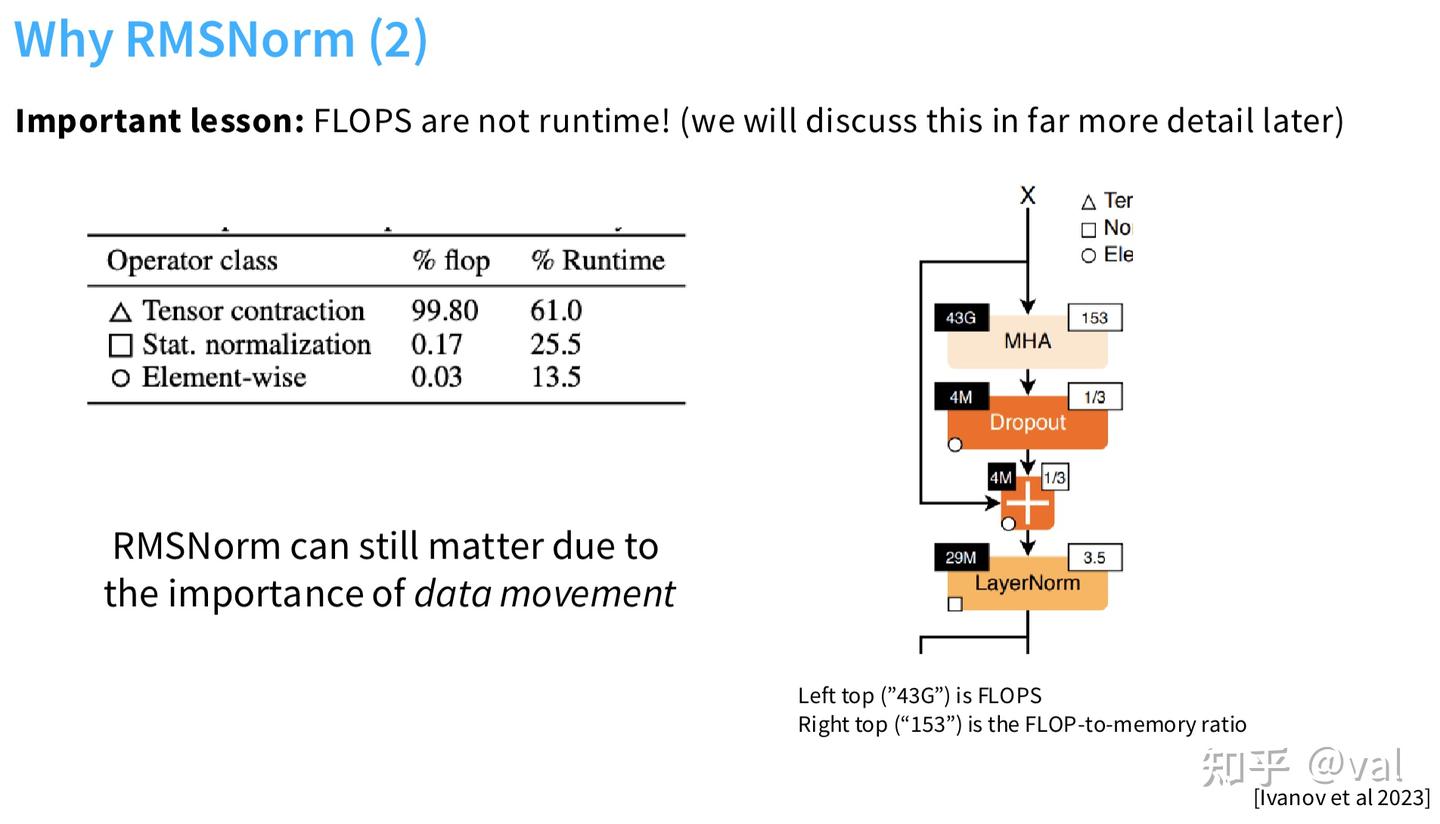
看起来 RMSNorm 减少的均值调整和偏置项只能节省 0.17% 的 FLOPs,但还要考虑内存数据搬运——参照图中数据,张量收缩(Tensor Contraction)即矩阵乘法之类的运算虽然占据了全部浮点运算量的 99.8%,而像 Softmax 或 LayerNorm 这一类 Transformer 架构中常见的归一化操作在浮点运算量上仅占 0.17%,实际上却消耗了 25% 的总运行时间。因为他们会产生大量的内存数据搬运开销。
因此着力优化这些底层细节确实具有实质性的意义,我们要考量的不仅仅是浮点运算量,更包括内存数据搬运的效率。RMSNorm 去掉均值调整和偏置项,不仅减少了计算量,更关键是降低了内存搬运开销(无需加载 β 参数、无需计算均值),因此成为主流。
(3)丢掉偏置项 更一般地,移除所有线性层偏置项,既减少内存访问开销,又能避免偏置项与归一化层的数值冲突,成为2023年后所有模型的默认设计。

1.3 激活函数与门控MLP:效果提升的核心
2023年后的模型几乎全面放弃ReLU/GeLU,转向门控线性单元(GLU变体),SwiGLU为绝对主流,GeGLU次之。门控激活通过「激活层×门控层」的逐元素相乘,提升了模型的表达能力,实证在预训练损失、下游任务效果上均有稳定增益。

- 非门控模型:MLP中间维度; $$$$
- 门控模型(SwiGLU/GeGLU): $$$$ (8/3倍),保证参数量与非门控模型一致。
传统 FFN 只有 1 路线性变换( $$$$ ), $$$$ 是为了足够的高维映射空间; 门控 FFN 有 2 路线性变换( $ x×W$ 和 $ x×V$ ),相当于参数量翻倍了。如果仍用 4,参数量会过多导致训练困难,所以按 2/3 缩放,保证总参数量和传统 FFN 相当,兼顾效果和效率。
门控变体(ReGLU/SwiGLU)在CoLA/SST-2等任务中综合得分显著高于非门控,SwiGLU实现了最低的预训练损失。
1.4 串行层 vs 并行层
原始 Transformer 的注意力和前馈网络是顺序执行的。但这种串行结构可能存在并行性限制:如果要在大量 GPU 上并行训练,串行连接会增加难度,可能导致 GPU 利用率降低。 因此,有少数模型采用了 “并行层” 设计:不再顺序执行注意力和前馈网络,而是对前一层的输出同时计算注意力和前馈网络,将两个结果相加后再融入残差流 —— 这一设计由 GPT-J 首创,谷歌的 PaLM 团队则大胆地在超大规模模型上验证了这一方案,之后有不少模型跟进。如果实现得当,并行层可以共享 LayerNorm,矩阵乘法也能融合执行,从而获得系统层面的效率提升。不过近一年来,并行层并没有成为主流,大多数新模型仍采用串行层,只有 Cohere Command A、Command R + 和 Falcon 2 11B 等少数模型例外。

关键差异:
- 串行层:先计算Attention,再计算MLP,顺序执行;
- 并行层:Attention和MLP同时计算,结果合并后加回残差流。
并行层可以通过算子融合实现15%的训练速度提升,62B及以上参数量模型无性能损失,2024-2025仅Cohere Command A/R+、Falcon2-11B等少数模型采用。
1.5 RoPE 一统位置编码方案
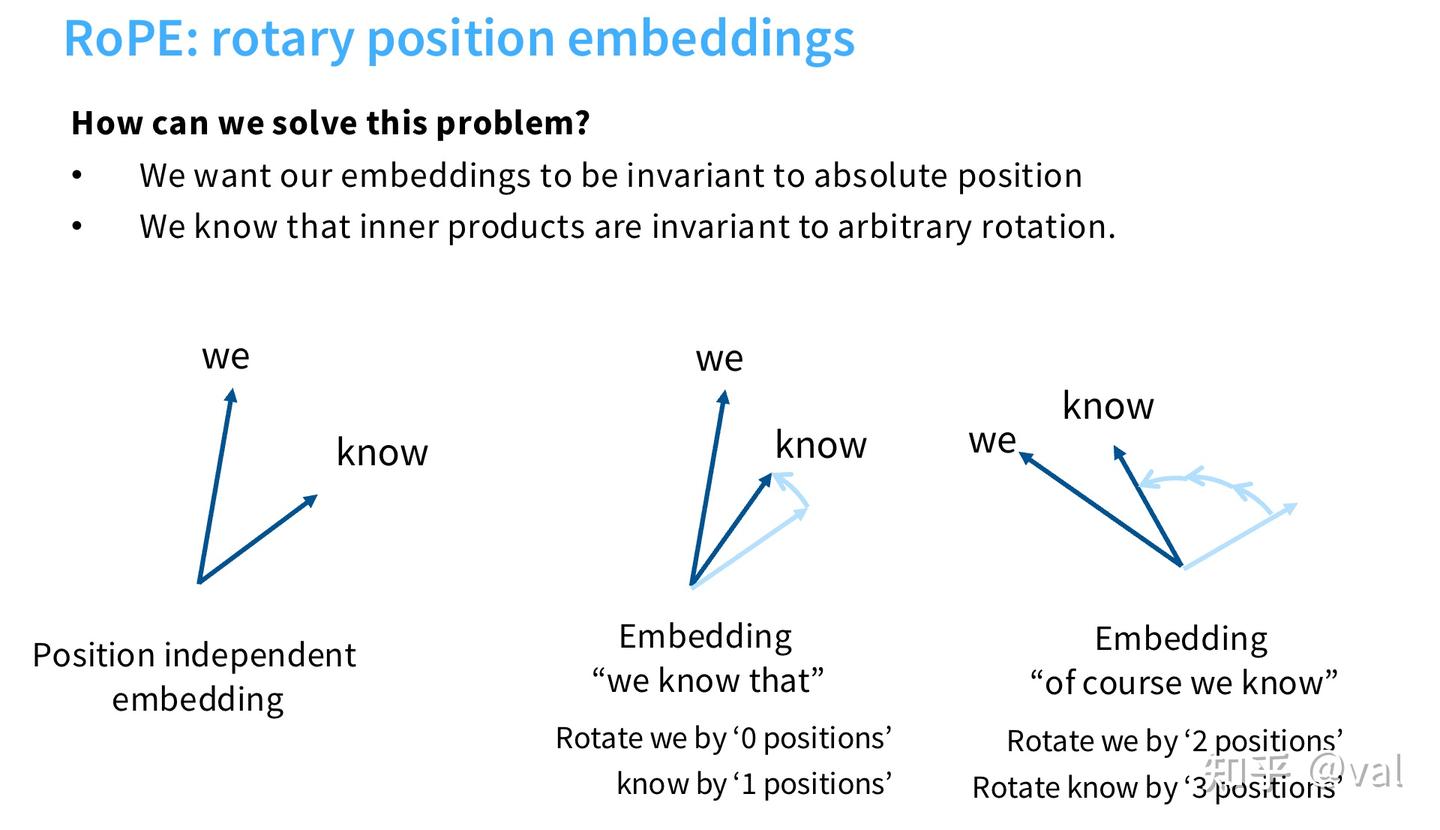
2023年后,RoPE(旋转位置编码)彻底替代正弦余弦、绝对、相对、ALiBi等位置编码,成为所有主流模型的选择,核心优势是完美支持相对位置编码,且具备极强的长上下文外推能力。RoPE 的核心设计思路是:注意力应该只依赖 token 的相对位置,而非绝对位置。 RoPE通过对查询Q/键K的高维向量做分块2D旋转,让注意力内积仅与token相对位置相关,无绝对位置信息泄露,且在注意力层实时旋转,非加性编码更稳定。
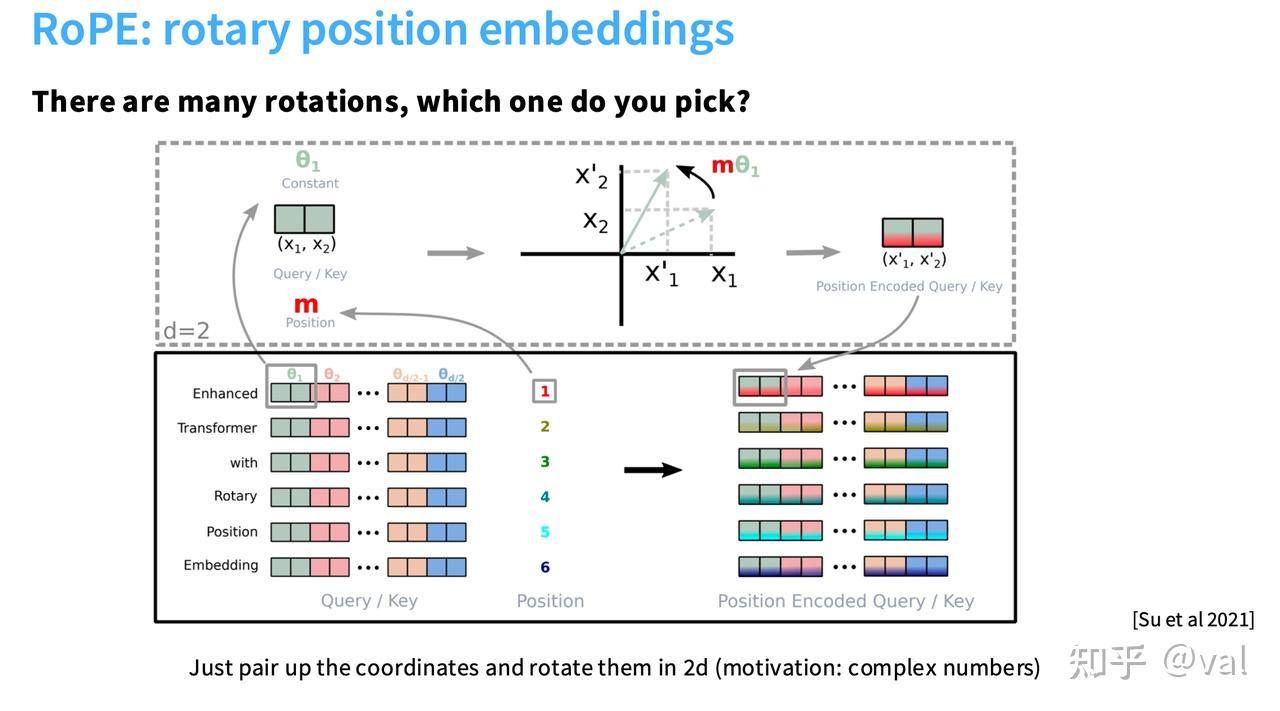
那高维空间中如何实现这种旋转?RoPE 的解决方案很简洁有效:将高维向量(维度 d)拆分为两两一组的 2D 子向量,每组根据 token 位置和预设的旋转频率 θ 进行旋转 —— 不同的 θ 对应不同的旋转速度,高频捕捉近距离位置关系,低频捕捉远距离位置关系,这和正弦余弦编码的频率设计思路类似。
还有一些模型如Command A采用RoPE+NoPE混合编码的方式来作为长上下文模型的专属优化方案,后续4.2混合注意力变体部分有介绍。
二、超参数选择的行业共识与规则
接下来我们深入到更细节的超参数选择。其实调参不需要抽卡,业界已经形成了一些经验法则和指导原则,包括MLP维度、注意力头、宽深比、词表大小、正则化等方面,只有少数模型在做很激进的尝试。
-
$\frac{d_{ff}}{d_{model}}$$$ 前馈网络维度(d_ff)与模型维度(d_model)的比例
-
$\frac{d_{model}}{n_{layer}}$$$ 模型的宽深比(aspect ratio)
- Weight Decay(权重衰减)
2.1 MLP中间维度 $$$$
$d_{ff}$$$ 的取值,业界的惯例一般是非门控 $$$4×d_{model}$$$ ,门控≈ $$$2.66×d_{model}$$$ ,为兼顾性能与参数量的最优选择。 **少数激进案例**:T5-11B曾用 $$$64×d_{model}$$$ (适配TPU大矩阵效率),Gemma2用 $$$8×d_{model}$$$ ,但后续模型均回归默认规则,说明激进选择并非最优。 **实验佐证** $$$\frac{d_{ff}}{d_{model}}$$$ 在1-10倍区间均为性能最优区间,4倍是工程上的通用默认值。 ### 2.2 注意力头的维度设置 **行业共识是让** $d_{model} = 单头维度 × 注意力头数$ 。大多数模型都遵循 1:1 的比例,单头维度通常为64/128,头数随模型维度同步增加。虽然理论上单头维度过小可能出现低秩瓶颈,但实证中无显著影响,该规则为所有模型的默认选择。 ### 2.3 模型宽深比(Aspect Ratio) 宽深比 $$$\frac{d_{model}}{n_{layer}}$$$ ≈100-128 是兼顾性能与并行效率的最优区间,GPT3/OPT/Mistral等均采用128,LLaMA系列采用102。 - 深模型(小宽深比):适合流水线并行,跨GPU通信延迟高; - 宽模型(大宽深比):适合张量并行,需高带宽GPU集群,为2024-2025主流方案。 ### 2.4 词表大小 从单语言的30k-50k,逐步升级为多语言/生产级模型的100k-250k,大词表能提升低资源语言的token压缩率,降低推理成本。英语单语言模型可使用小词表,多语言/生产级模型必须使用100k+大词表。 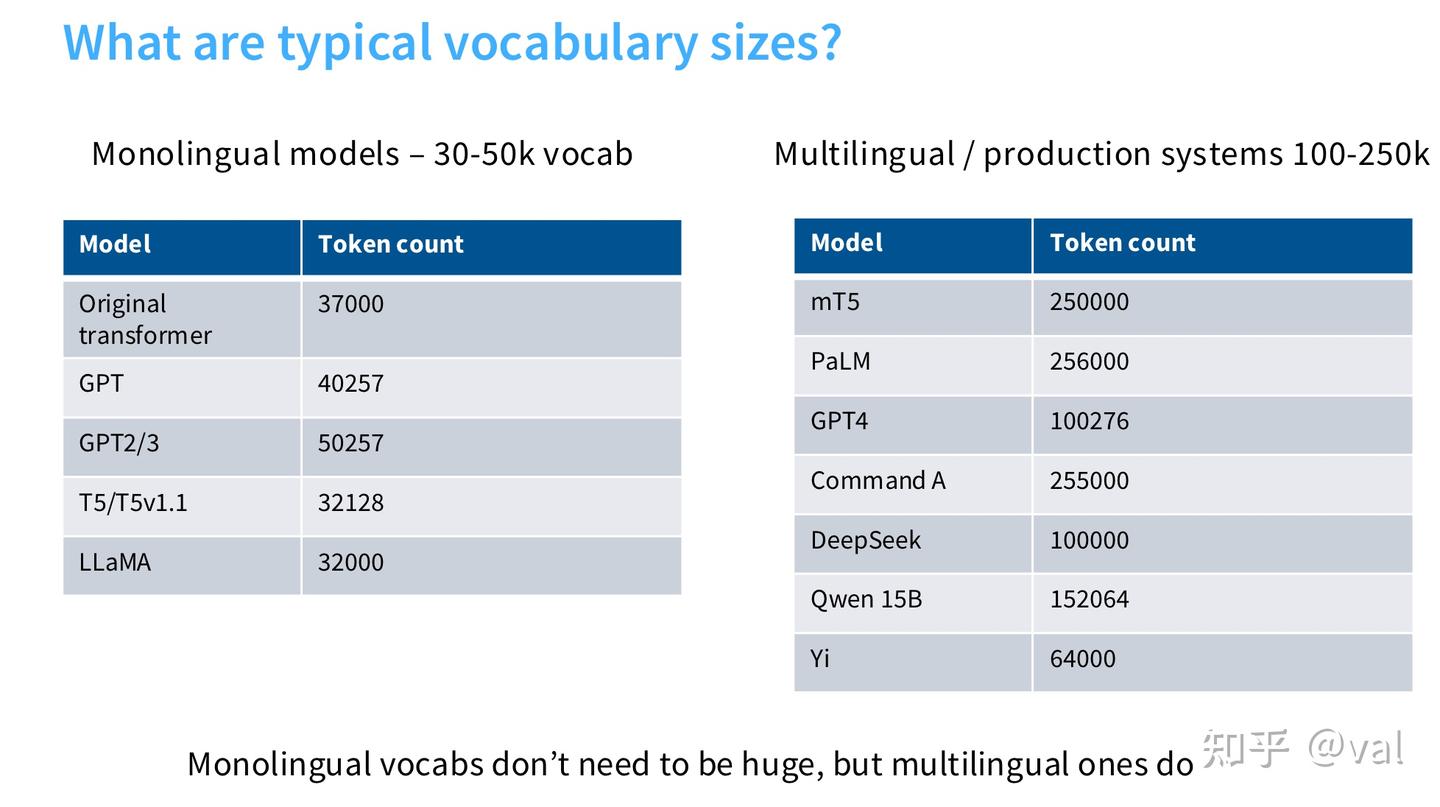 ### 2.5 正则化策略:Dropout 遭弃用,Weight Decay(0.1)成为默认选择 Dropout 在老模型里很常见 —— 比如原始 Transformer、GPT-2、T5,原理很简单:训练时随机把部分神经元的输出置为 0。它的初衷是防止过拟合,强制模型学习鲁棒的特征,而不是依赖特定的神经元。但其实预训练只做单次遍历,根本不会过拟合。而且 Dropout 还会破坏训练稳定性,导致损失值骤升,干扰梯度传播(唯一的例外可能是一些小模型)。现在 Dropout 几乎完全被弃用,Weight Decay 成为了所有模型的默认选择,但是其作用并非传统的正则化,而是优化训练动态。 权重衰减(Weight Decay)与余弦退火学习率调度协同,在训练后期学习率下降时,加速损失下降,得到更低的训练/验证损失,并非为了解决过拟合(预训练仅1个epoch,没有过拟合的风险)。 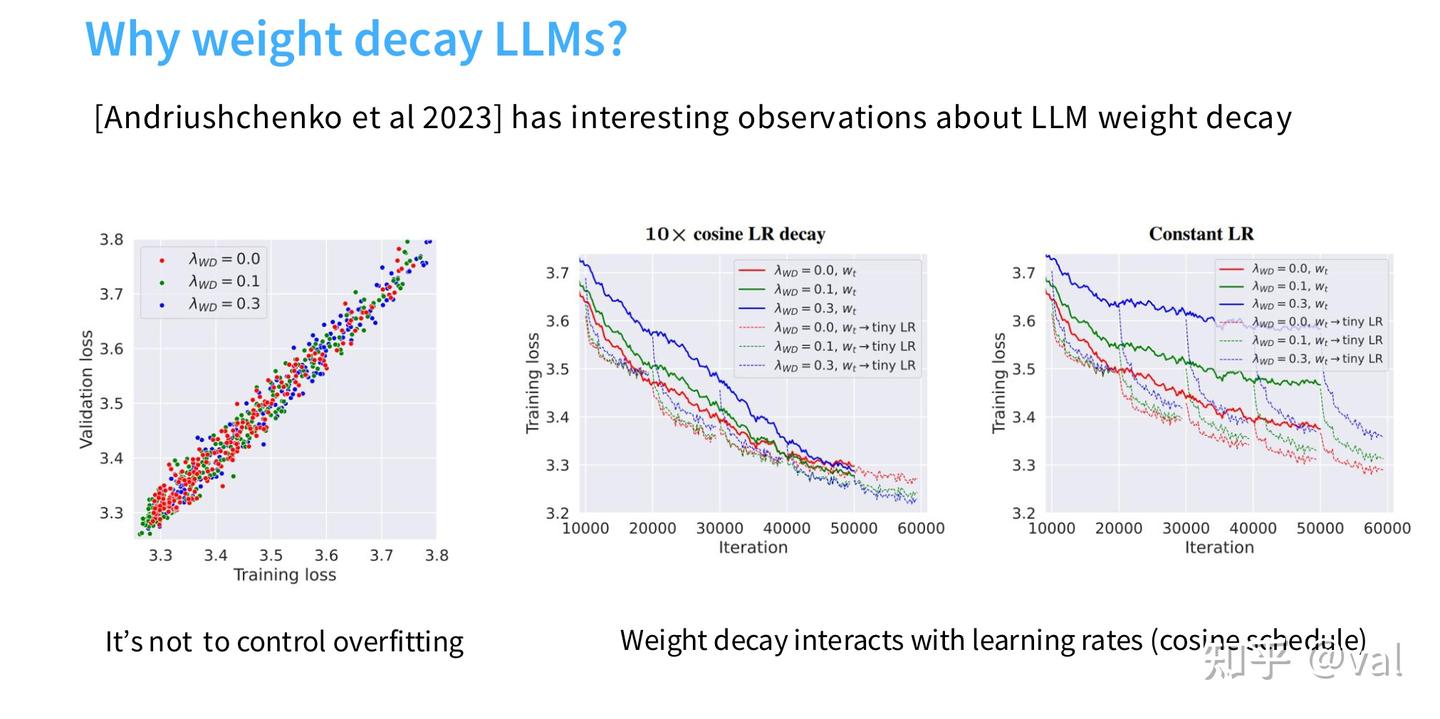 ## 三、Stability tricks 大模型训练稳定性技巧 近一年Transformer核心架构无颠覆性变化,最大迭代集中在**训练稳定性优化**——模型规模越大、训练时间越长,越易因Softmax数值不稳定性出现梯度爆炸、损失尖峰,甚至训练崩溃。 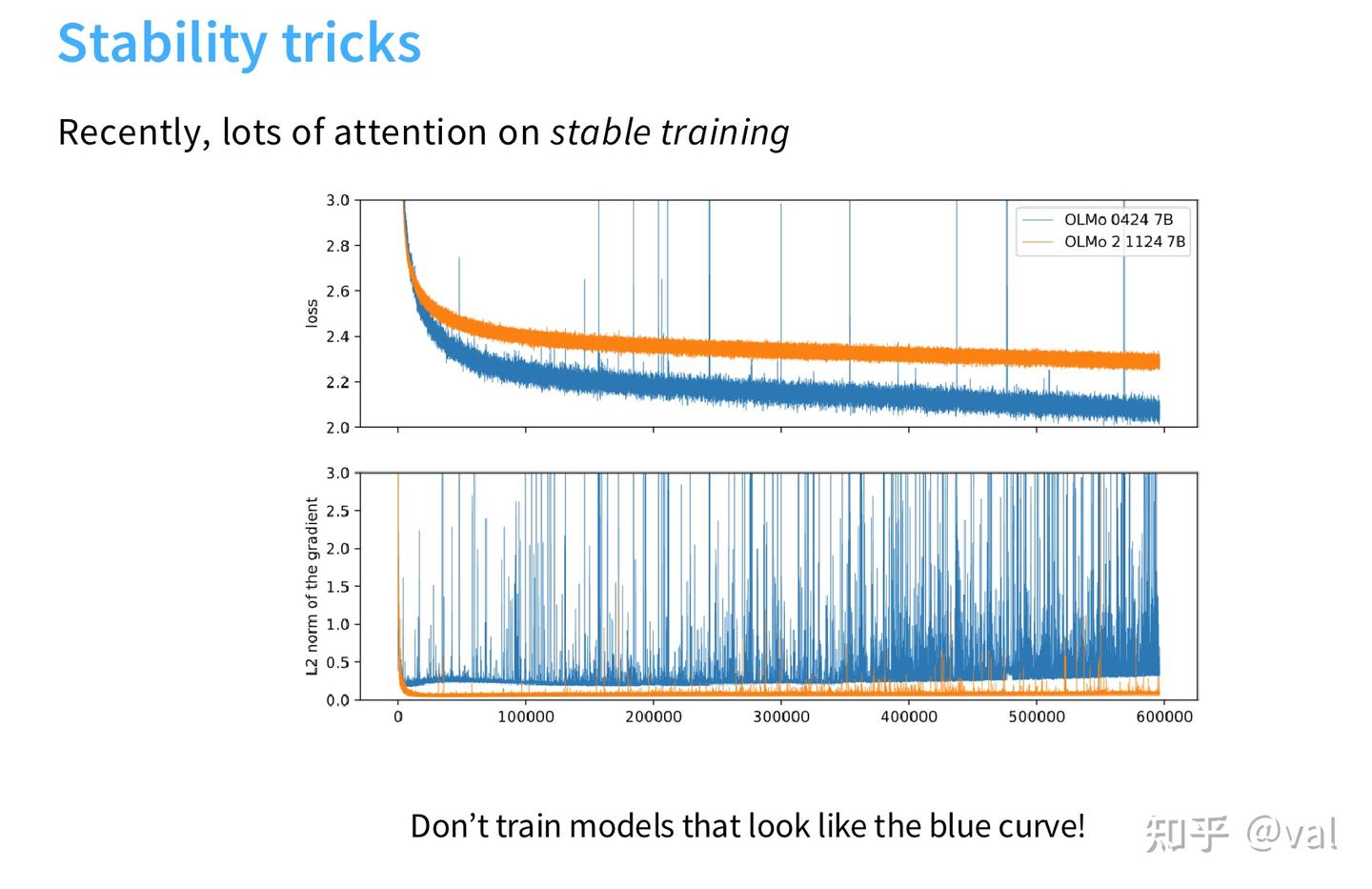 上图中蓝色曲线是训练时的梯度 L2 范数,虽然损失曲线看似正常,但梯度范数频繁出现剧烈尖峰,这种情况下,模型随时可能因梯度爆炸而训练中断;而橙色曲线(采用稳定性技巧后)的梯度范数始终保持在较低水平,这才是理想的训练状态(两条曲线的损失差异是因为切换了数据集,忽略即可)。 Transformer中的**两个Softmax**是数值不稳定性的核心:输出层Softmax(指数溢出/除零)、注意力层Softmax(QK内积过大导致Softmax饱和)。以下为3个已验证的主流方案: ## 3.1 Z-Loss:针对输出层Softmax z-loss 的核心思想是在交叉熵损失函数中加入一个辅助损失项,强制Softmax的归一化项 Z(x) 趋近于1。当 Z (x) 趋近于 1 时,log 和 exp 相互抵消,数值计算会变得非常稳定,避免了溢出风险,提升数值稳定性。  **代表模型**:PaLM、Baichuan2、OLMo2、DCLM,2024年后主流模型均采用。 ### 3.2 QK Norm:针对注意力层Softmax(效果最优) QK norm 最初是视觉和多模态模型领域的创新,在Q/K计算内积前,分别对Q/K做 LayerNorm,限制输入数值范围,避免内积过大导致 Softmax 饱和。不仅可以提升稳定性,还能支持更激进的学习率,实现模型性能提升,是2024-2025的标准优化方案。 这里可以插个小玩笑:LayerNorm 在稳定性干预中简直 “无所不能”—— 从预归一化到双重归一化,再到现在的 QK norm,只要哪里出现稳定性问题,加一层 LayerNorm 往往能解决(至少在稳定性方面,LayerNorm 的效果惊人,且对性能影响极小)。 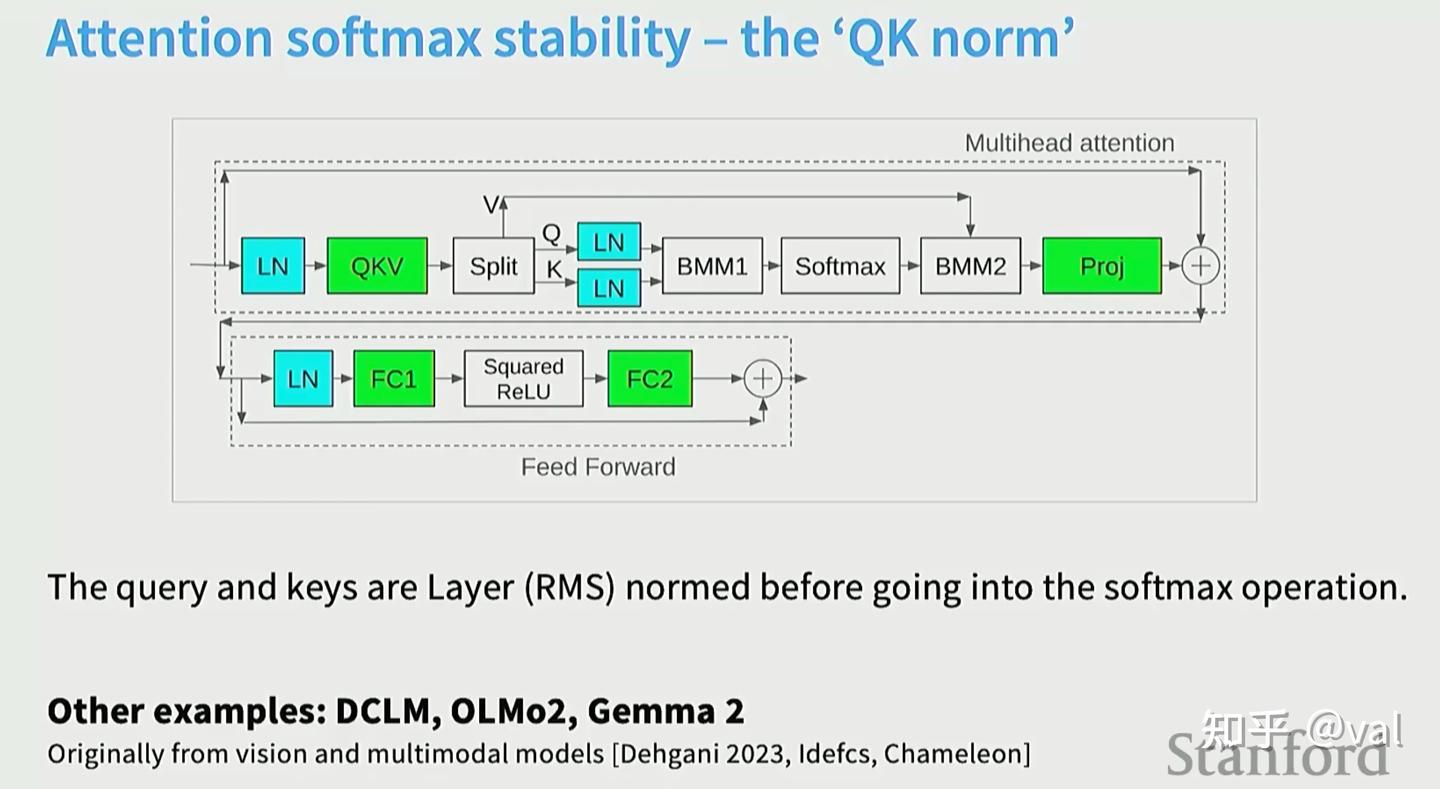 ### 3.3 Logits 软截断(Soft Capping) 这一方法是在注意力层的 logits(Q・K^T 的结果)送入 softmax 之前,通过 tanh 函数进行软截断。  当 logits 超过 soft_cap 时,tanh 函数会将其 “压制” 到 1 附近,从而限制 logits 的最大值,避免 softmax 数值爆炸。Soft Capping 能提升稳定性,但 Nvidia 的研究表明它会导致模型困惑度小幅上升,所以其普及度低于QK Norm,仅Gemma2、OLMo2等少数模型采用。 ## 四、注意力变体:推理优化与长上下文支持 注意力变体的核心优化目标为**降低推理开销**(MQA/GQA)和**支持超长上下文**(滑动窗口/混合注意力),是2024-2025年工程化落地的重要方向。 ### 4.1 MQA/GQA:推理吞吐量优化的核心 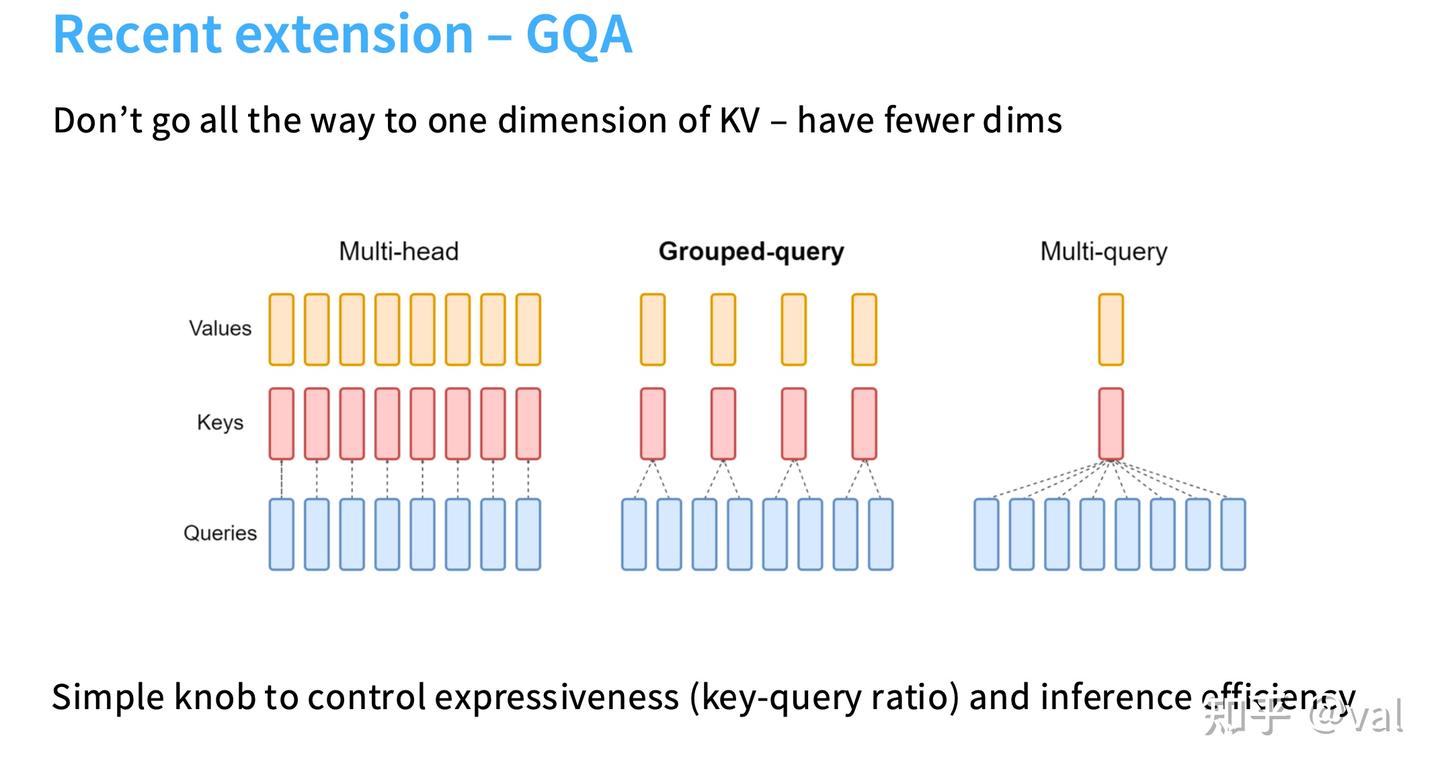 自回归推理时,KV Cache 是内存瓶颈(训练时批量计算GPU利用率高,推理时逐token生成,内存访问开销骤增,算术强度大幅下降)。而 MQA(多查询单KV头)和GQA(分组查询,一组查询共享一个KV头)通过解耦 Q 头与 KV 头数量(多 Q 头 + 少 KV 头),降低 KV Cache 开销,同时最小化性能损失。MQA 相比标准多头注意力(MHA),困惑度仅轻微上升,性能损失可忽略;而 GQA 在推理速度和性能之间取得了更优的平衡,几乎没有性能损失,成为生产级模型的首选。 ### 4.2 长上下文注意力的最新进展 针对千万级token的超长上下文需求,2025年最新模型均采用**滑动窗口注意力(SWA)+ 全注意力**的混合方案,替代传统的全局注意力(二次方计算开销)。 **(1)滑动窗口注意力(SWA)** **核心原理**:每层仅关注当前token的局部窗口(如512/1024个token),有效上下文长度=窗口大小×层数。 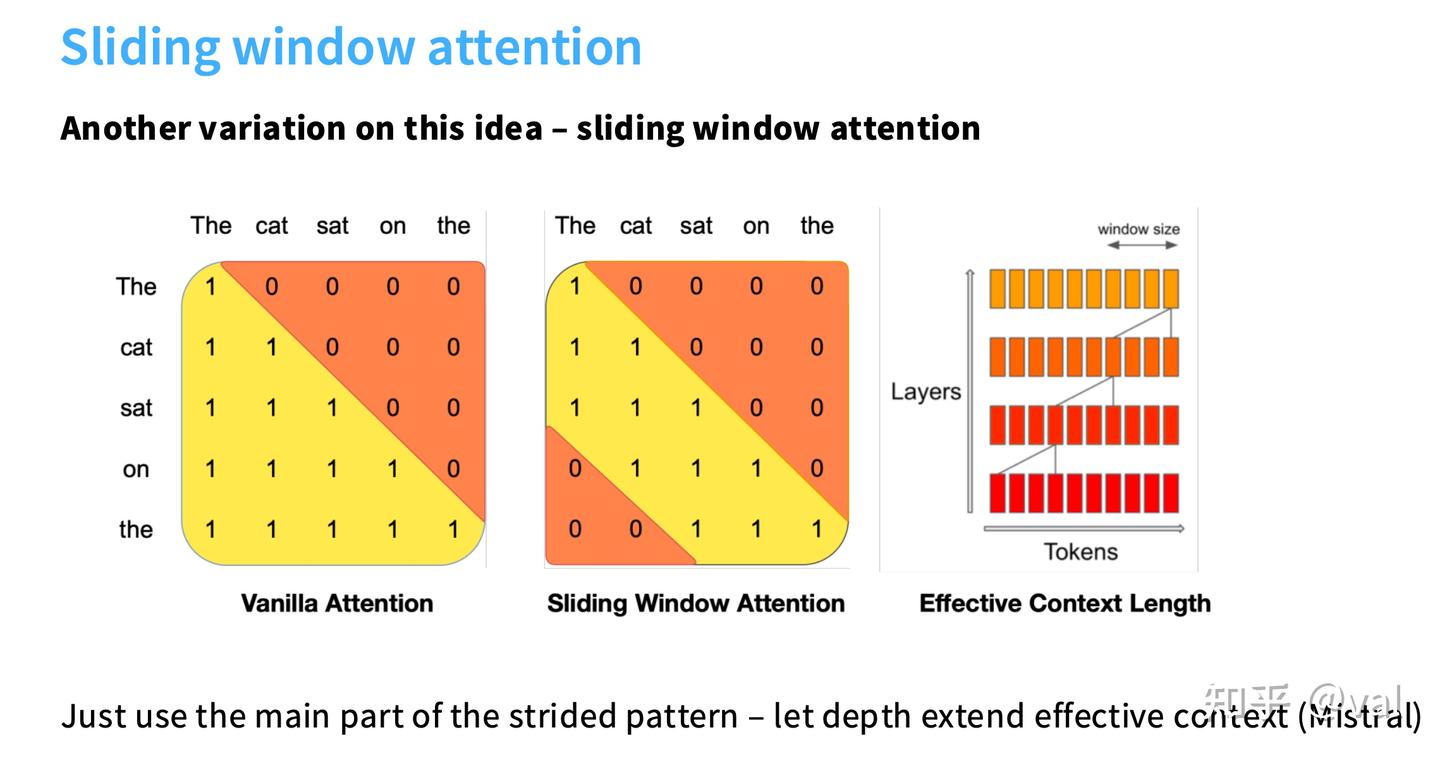 **(2)混合注意力** **原理**:每2-4个Transformer块为一组,其中1个块使用**无位置编码(NoPE)的全注意力**,其余块使用RoPE+滑动窗口注意力,兼顾短程信息捕捉和长程信息传递。  **优势**:既通过滑动窗口控制计算/内存开销,又通过定期的全注意力实现长程信息全局传递,支持千万级token上下文,是当前长上下文模型的唯一选择。 ## 五、一些可泛化的经验总结 1. 归一化是大模型训练稳定的「万能钥匙」,**Pre-Norm + RMSNorm**是2024-2025的共识,Double Norm或是未来趋势。 2. 架构设计不能只关注FLOPs,**内存访问开销**对运行效率的影响更大。 3. SwiGLU/GeGLU是门控激活的最优选择,能实现稳定性能增益,是所有现代模型的默认配置,且需按2/3缩放MLP维度以匹配参数量。 4. 超参数相对来说有一套行业的经验共识,调参的时候不用盲目调。 5. 大模型训练稳定性的核心是**优化Softmax数值行为**,**QK Norm + Z-Loss**是2025年的标准优化组合,兼顾稳定性与性能。 6. 推理优化的核心是**减少KV缓存开销**,GQA是性能与效率的最优平衡,远超MHA和MQA。 7. 长上下文模型的唯一解决方案是**混合注意力(SWA+全注意力)**,通过局部窗口控制开销,定期全注意力实现长程信息传递。 8. 2017-2025年主流LLM的核心差异仅在**位置编码、激活函数、分词方式**,核心Transformer架构无颠覆性变化,「类LLaMA架构」或成为行业通用模板。 