本文首发于知乎,现迁移至个人博客。
一、推理概述
先下个定义:推理即给定一个已训练完成的固定模型,根据输入提示词(prompt)生成对应回复的过程。 推理的应用很广泛,包括但不限于:
- 实际应用(聊天机器人、代码补全、批量数据处理)
- 模型评估(例如,针对指令遵循能力的评估)
- 测试阶段的计算(“思考”过程需要更多的推理资源)
- 基于强化学习的训练(生成样本,随后进行评分)
1.1 为什么推理效率至关重要
- 训练是一次性成本,推理是反复执行的持续性成本
- 行业数据:OpenAI每天生成1000亿单词;Cursor每天生成10亿行被采纳的代码
- 趋势:推理成本在大模型总拥有成本中的占比持续超过训练成本
1.2 推理的性能指标
| 指标 | 定义 | 关键影响场景 |
|---|---|---|
| 首token时延(TTFT) | 用户发起请求到看到第一个token的等待时间 | 交互式应用。 |
| 单token延迟 | 第一个token生成后,后续每个token的生成间隔 | 交互式应用。关注单个用户的最差体验 |
| 吞吐量 | 单位时间内系统生成的总token数 | 批处理任务、高并发服务。关注整体效率 |
二、理解推理的负载
- 训练:能看到所有token,可对序列做完全并行计算,Transformer的矩阵乘法能充分利用算力
- 推理:自回归生成,每个token依赖所有历史token,必须串行执行,难以充分利用硬件算力,且天然内存受限
2.1 算术强度
用一张来自 sacling-book 的图回顾一下 transformer:
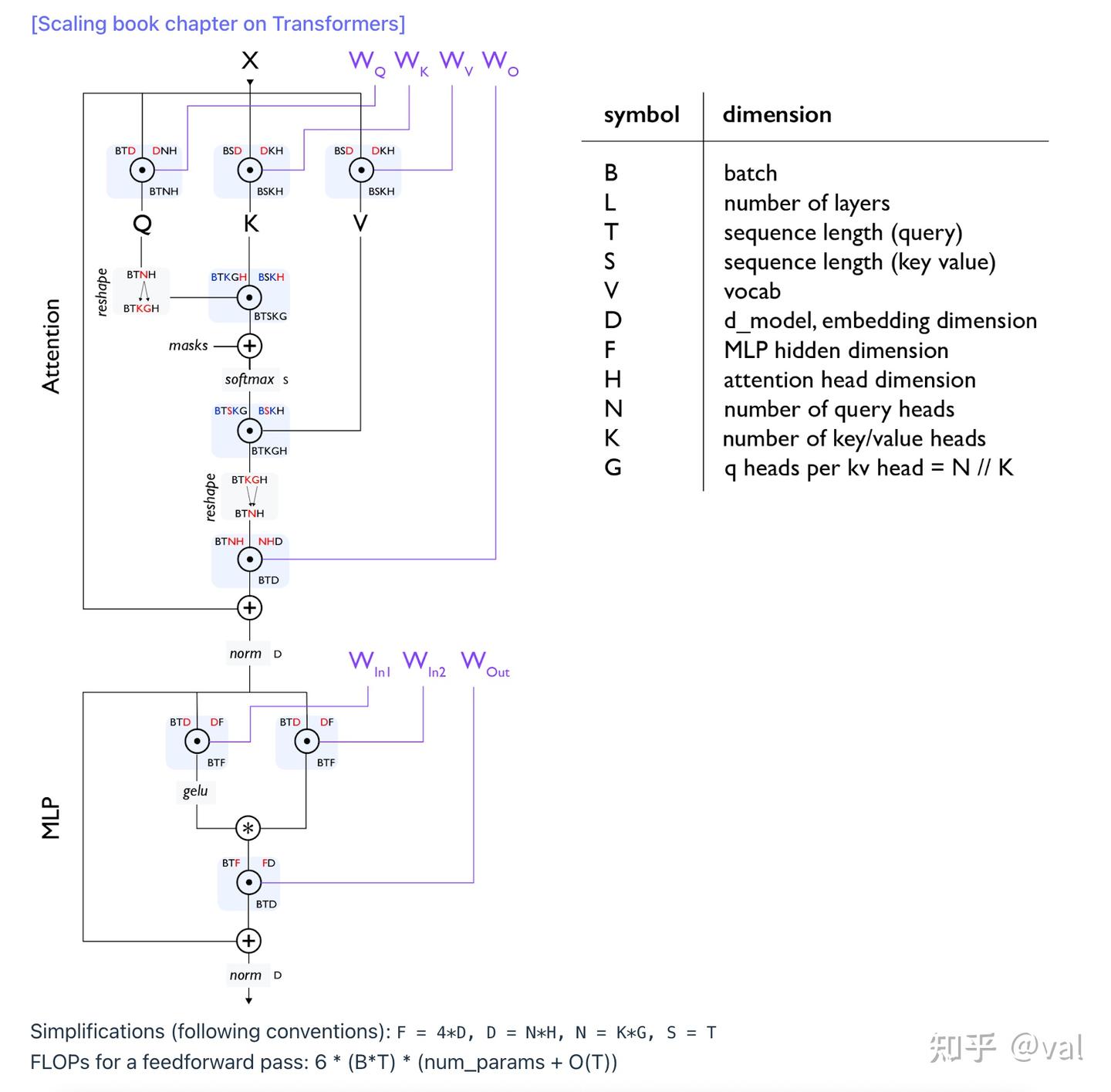
用于判断一个计算是算力受限还是内存受限的核心指标是 arithmetic_intensity(算术强度): ,含义是每传输一个字节,要做多少次浮点运算。
以最基础的矩阵乘法为例,X[B×D] × W[D×F] ,B 表示批量大小,D 表示隐藏维度,F 表示 MLP 中的上投影维度。
- FLOPs:
- 内存读写:
为了简化分析,通常 ,则有算术强度 ≈
接下来还要看加速器的性能(硬件阈值),以H100为例:
- H100浮点运算速度是 989 TFLOPs/s(bf16)
- 内存带宽:3.35 TB/s
两者相除得到加速器强度: 当计算强度 > 加速器强度时,任务算力受限(能充分利用GPU);当计算强度 < 加速器强度时,任务内存受限(大部分时间在等内存读写,不太理想)
这些都算是比较理想化的简化分析,实际的细节要复杂得多。 在极端情况下,例如 B=1(矩阵向量乘法),算术强度=1,严重内存受限。这正是推理的生成过程面临的处境。
2.2 KV缓存:推理的核心优化
朴素推理(Naive inference)的问题
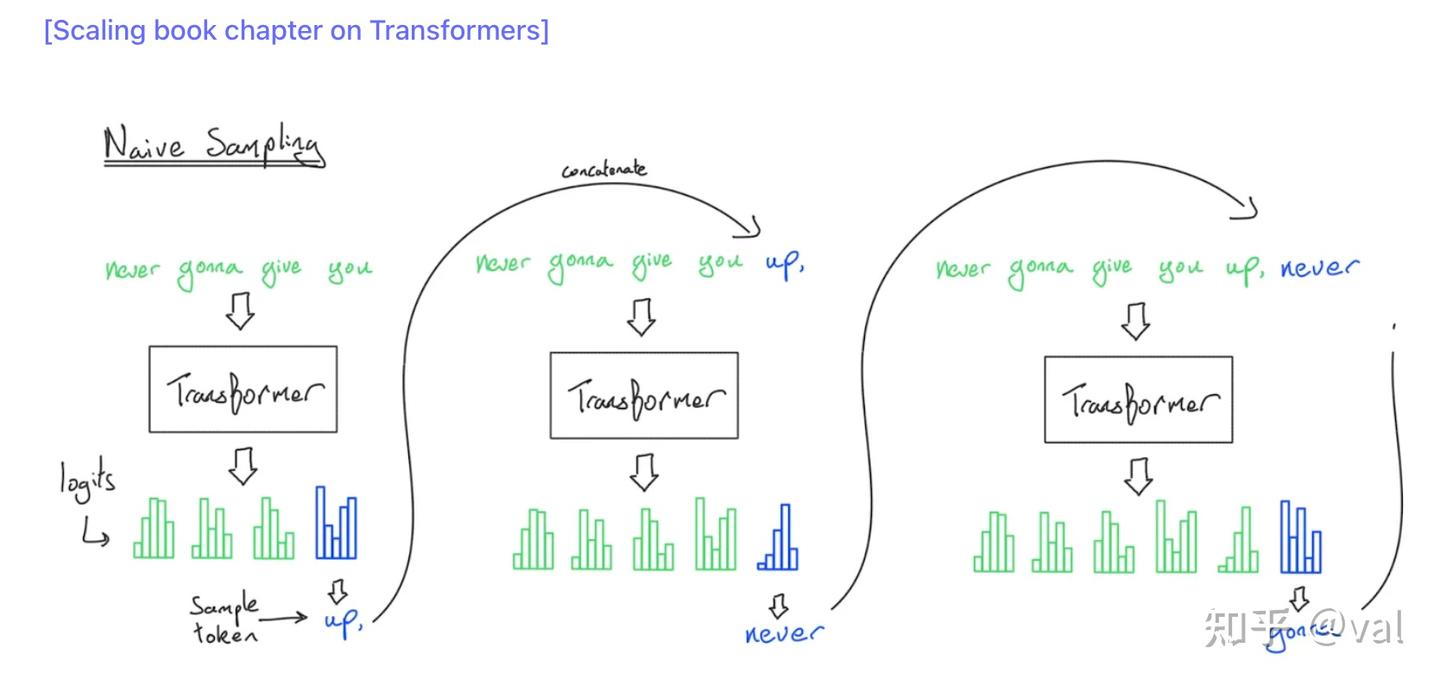
朴素推理的复杂度很不理想,每生成一个 token 都要重新计算整个历史序列的所有注意力,生成T个token的复杂度为 ,存在大量冗余计算。 对自回归因果 Transformer来说,前缀的计算结果完全可以复用。解决方案就是KV Cache,把缓存存在高带宽内存(HBM)中,因为这里有足够的存储空间。
2.3 KV Cache 原理
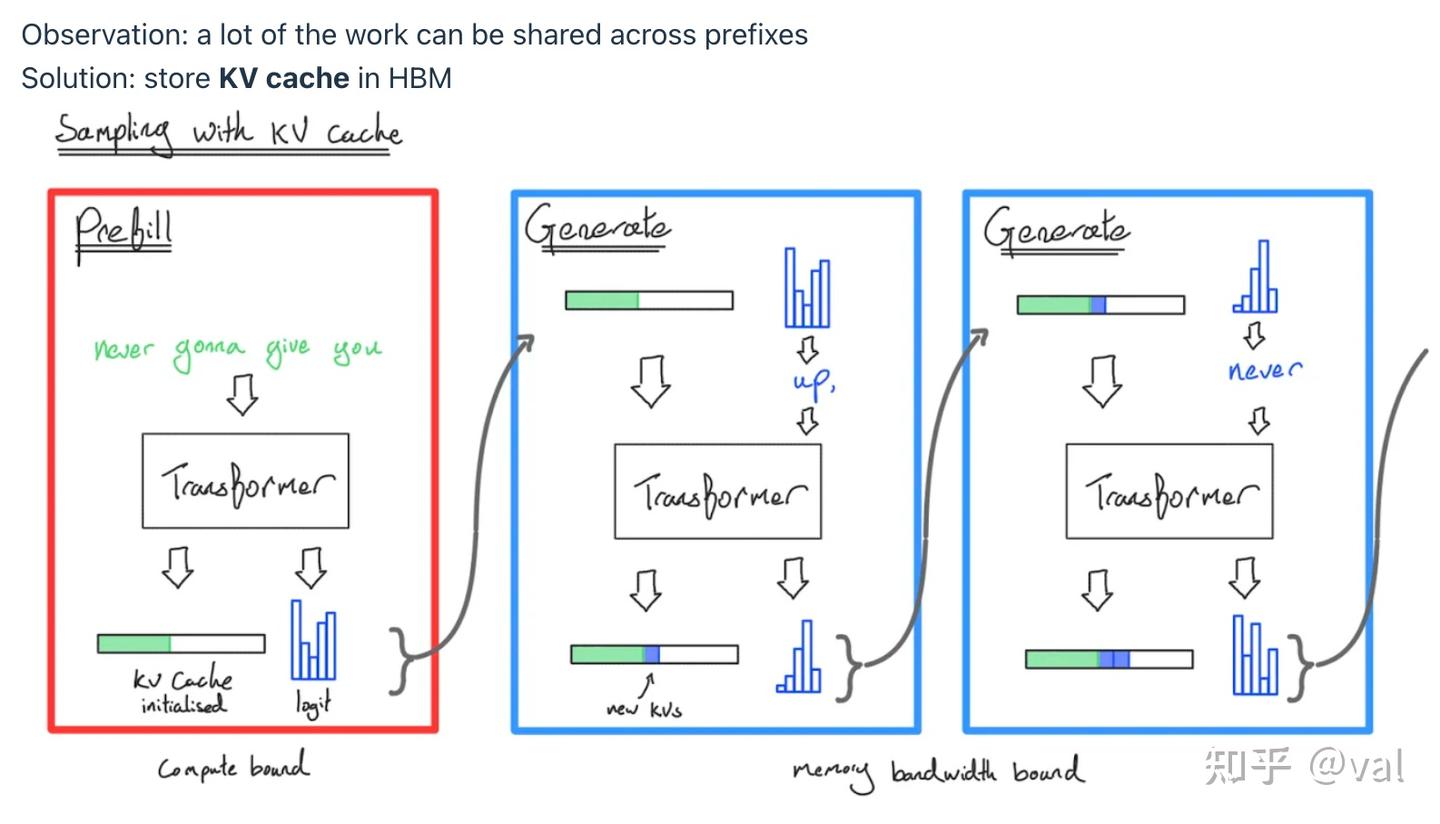
- 缓存所有历史token的键(K)和值(V)向量,无需重复计算
- 每生成一个新token,仅需计算该token的K/V向量并追加到缓存中
- 复杂度从 降至
具体来说,KV缓存需要为批次中每个序列、每个token、每一层、每个注意力头,存储一个H维向量——可想而知,这会占用大量内存。
推理的两个阶段
| 阶段 | 特点 | 计算特性 | 效率 |
|---|---|---|---|
| 预填充(Prefill) | 输入提示词,一次性计算所有prompt token的K/V缓存 | 并行计算,和训练一致 | 算力受限,效率高 |
| 生成(Generation) | 逐一生成回复token,每次仅处理1个新token | 串行计算 | 内存受限,效率低 |
2.4 Transformer 各层的算术强度
接下来看一下 Transformer 各层在两个阶段的算术强度。
MLP层
- 算术强度:
- 预填充阶段(T=S): ,容易达到算力受限
- 生成阶段(T=1): ,依赖并发请求数提升效率
预填充阶段BT可以很大,即便B=1,只要序列足够长也能保证效率;但生成阶段T=1,只能靠增大B(并发请求数)提升效率。这意味着推理效率依赖大批次,能把多个请求打包处理就能提升吞吐量,但如果请求稀疏,硬件利用率就会很低——这也是推理的动态特性。
注意力层
- 算术强度:
- 预填充阶段(T=S): ,序列足够长时算力受限
- 生成阶段(T=1): ,永远内存受限,且与批次大小B无关
注意力的算术强度和批次B无关,因为MLP层所有序列共享同一套权重,而注意力层每个序列都有独立的KV缓存,批次无法带来内存复用收益。从数学上看,FLOPs和内存传输都与B成正比,比值会约去B;而MLP层的内存传输主要来自权重(与B无关),因此比值会保留B。
- 预填充是算力受限,生成是内存受限
- MLP效率可通过增大批次提升,注意力效率无法通过批次提升
- 推理的核心瓶颈是生成阶段的注意力层
2.5 吞吐量与延迟的理论计算
通用公式: KV缓存大小公式
- S:序列长度,L:层数,K:KV头数,H:头维度
- 4:2(键+值)× 2(bf16每元素字节数)
Llama 2 13B在H100上的实测(S=1024)
| 批次大小B | 内存占用 | 单token延迟 | 吞吐量 | 实验现象总结 |
|---|---|---|---|---|
| 1 | ~26GB | ~8ms | 124 tokens/s | - |
| 64 | ~79GB | ~23ms | 2689 tokens/s | 延迟增加吞吐量大幅提升 |
| 256 | ~240GB | ~70ms | 3561 tokens/s | 延迟继续上升吞吐量增长放缓(边际效应) |
至此我们可以总结一下关于延迟-吞吐量的 trade off:
- 小批次:低延迟,低硬件利用率
- 大批次:高吞吐量,高延迟,但受内存限制无法无限增大批次。
之前的 Lecture7/8 讲过训练的并行策略,复杂且繁琐;而推理的一种并行方式非常简单:直接启动M个模型副本,延迟不变,吞吐量线性提升M倍——不要忽略这种简单有效的方法。
不过如果模型太大,单张GPU放不下,就需要对模型分片,部分场景下还需要分片KV缓存以提升效率,具体细节可参考 Scaling Book。
首 token 时延(TTFT)由预填充阶段决定,即 encode prompt 的耗时,通常是算力受限,固定架构下很难优化,减小批次可小幅提升,但要提升吞吐量仍需增大批次。
三、推理的有损优化
3.1 架构级KV缓存优化
1. GQA(分组查询注意力) 原理和思路老生常谈不再赘述。
Llama 2 13B用1:5 GQA(40个查询头→8个KV头)
2. Multi-head latent attention(MLA,多头潜在注意力,from DeepSeek V2)
- 核心思路是不减少KV头数,而是将每个KV向量从 维投影到更低的 维
- DeepSeek V2将16384维投影到512维(不过需要额外加64维来适配RoPE),KV缓存大幅减小,获得延迟和吞吐量的优势。
3. Cross-layer attention(CLA,跨层注意力)
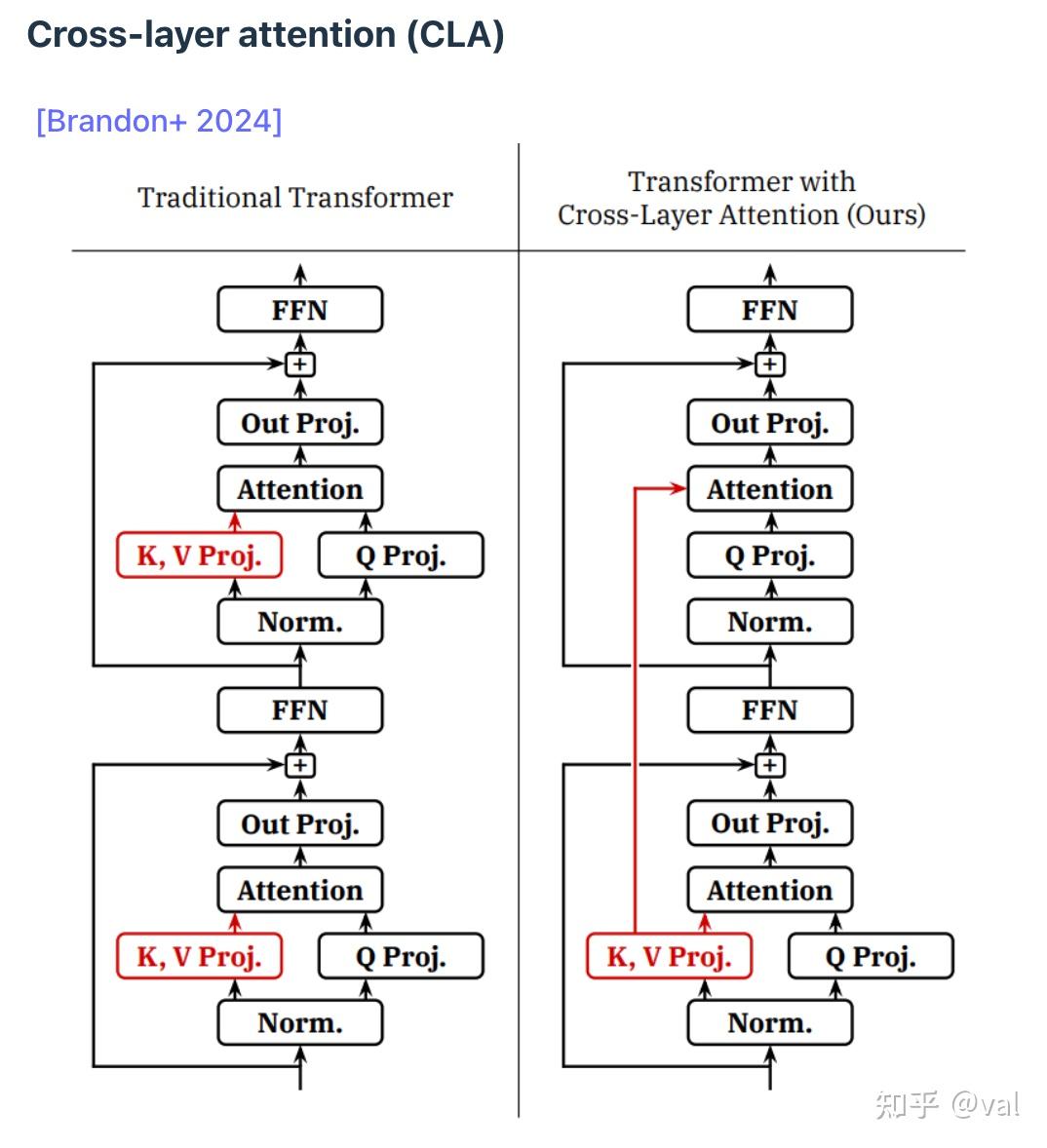
核心思路是跨层共享KV投影和缓存(正如GQA是跨头共享KV),实验证明这种方法能在准确性跟 KV 缓存大小之间,取得更好的平衡,优化精度-效率帕累托边界。
4. Local attention 局部注意力
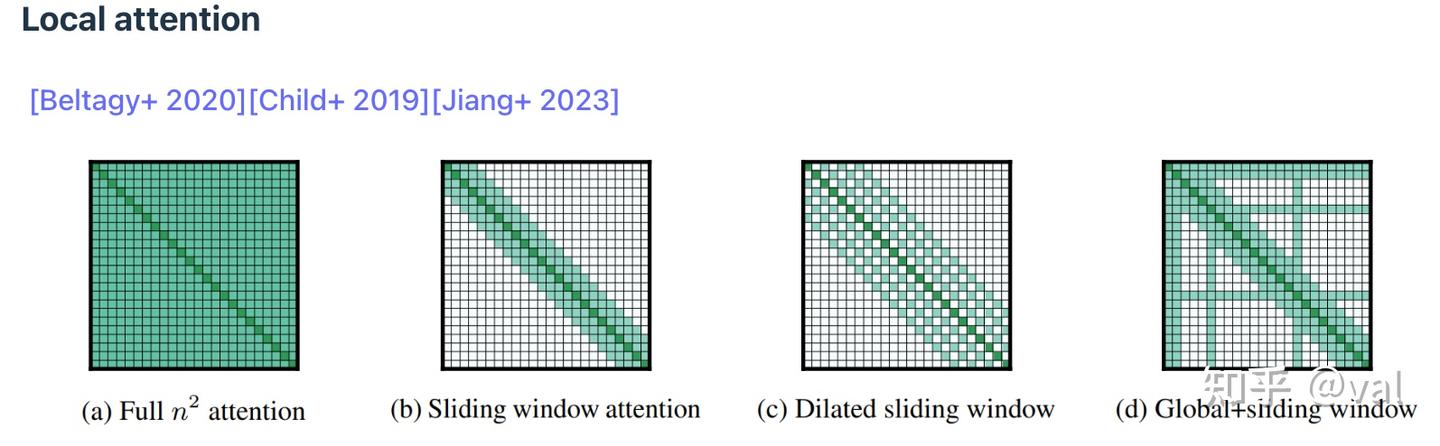
核心思路是仅关注过去K个token,超出窗口的token直接丢弃,KV缓存大小不再随序列长度增长(变为常量)。但这样会是损失长距离依赖能力,表达能力有限——我们之所以要用注意力机制而不是RNN,就是我们希望模型能够捕捉长距离的依赖关系。
不过我们可以混合局部+全局注意力(如每6层放1层全局注意力)。

3.2 更激进的新架构
Transformer的自回归+全注意力是推理瓶颈的根源,新型架构从根本上改变计算模式。 1. 状态空间模型(SSM)
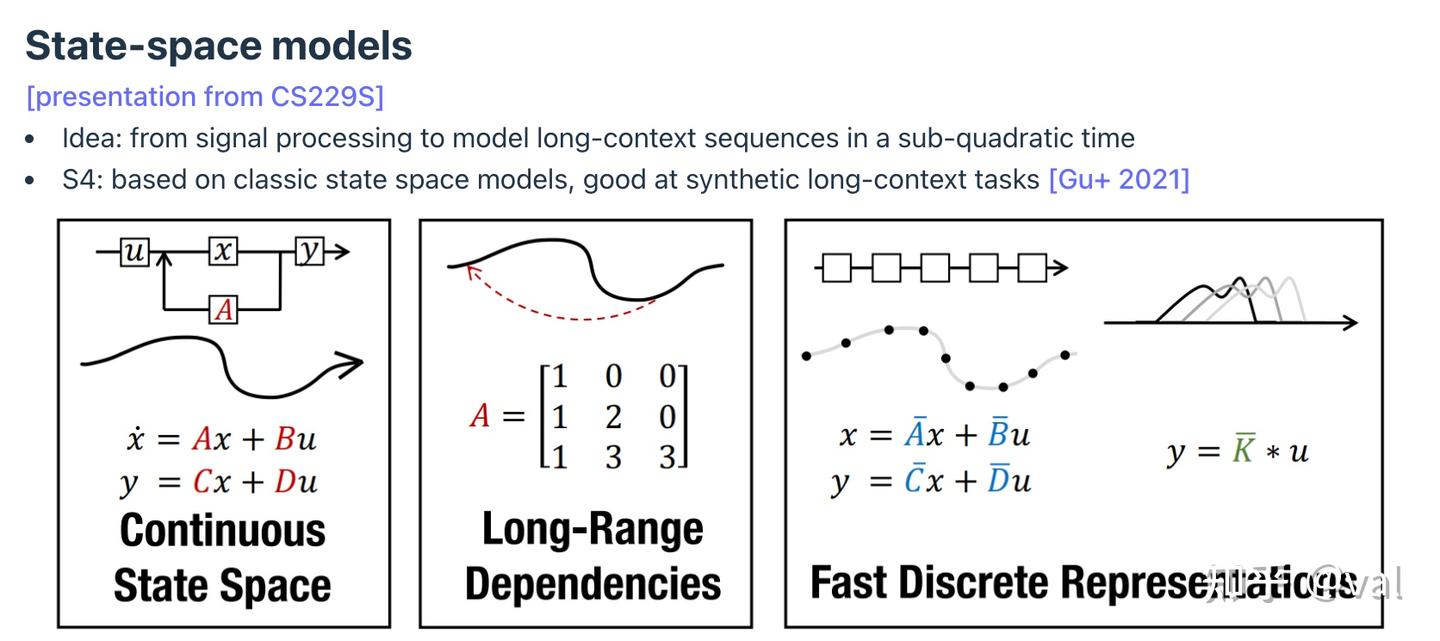
思路是利用信号处理技术,以亚二次方时间复杂度对长上下文序列进行建模。
发展路线:S4(长序列建模)→ Mamba(解决关联召回问题)→ Jamba(Mamba+Transformer混合)→ BASED(线性注意力+局部注意力)
- 优势:将KV缓存从O(T)变为O(1),推理效率大幅提升
- 劣势:不擅长解决对语言至关重要的联想回忆任务(而这正是 Transformer 的强项)。
- 现状:MiniMax 用线性注意力训练出456B参数MoE模型,仅保留少量全注意力层。或许我们现在还没法完全不用全局注意力机制,但至少大部分全局注意力机制已经被替换掉了。
2. 扩散模型
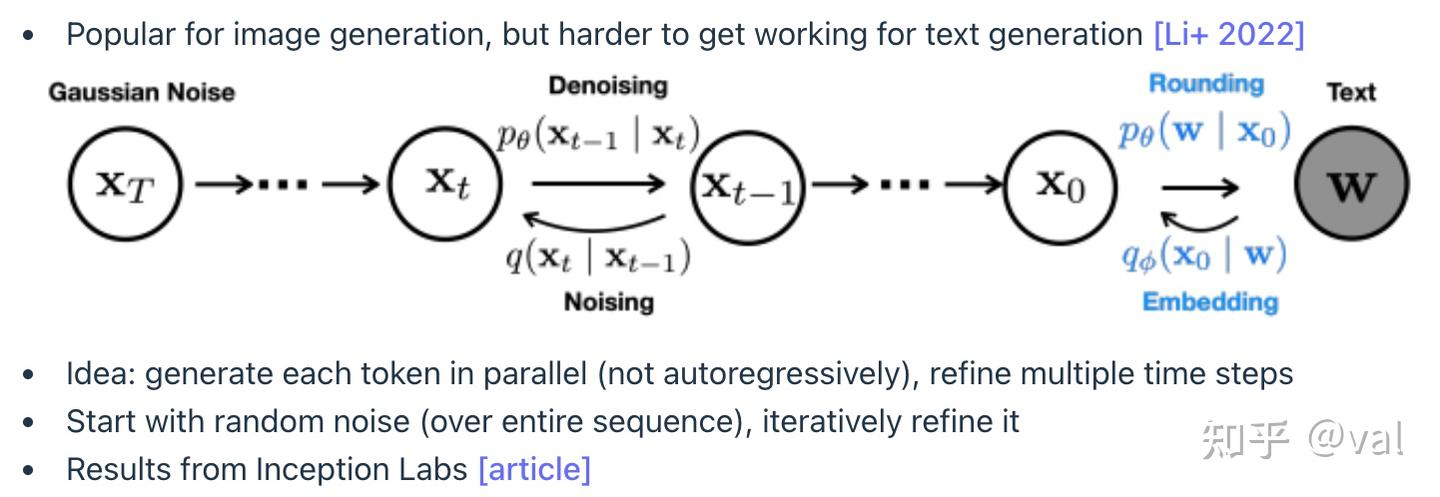
核心思路是放弃自回归,并行生成所有token,通过多次迭代 refine 结果
优势:能充分利用GPU算力,生成速度远超Transformer
现状:Inception Labs的扩散模型在代码生成任务上速度显著领先,通用性仍在验证中。但速度优势极大,可通过增加算力弥补精度损失(如果需要的话)。
全新的架构对推理来说确实非常令人兴奋,因为它能帮助我们越过一些根本性的障碍。
处理注意力机制时,会遇到KV缓存的根本性障碍。虽然可以量化和优化,但他始终存在。
而通过构建状态空间模型,就能把它缩小到一个固定大小。
扩散模型也是类似的原理,自回归生成是主要瓶颈。如果能改用并行生成,整个局面就彻底改变了。
所以推理优化方面还有很多工作要做。推理这个领域比乍起来看的要广阔得多,关键不仅在于系统层面的速度优化,或许真正的突破可能来自架构的根本性变革。
3.3 量化与剪枝
量化
- 核心思路是降低数值精度,减少内存传输,降低延迟、提升吞吐量,代价是可能损失精度。
- 精度层级:FP32(训练)→ BF16(推理默认)→ FP8/INT8 → INT4、
- 方式:有训练时量化跟训练后量化两种方式,前者需要重新训练模型,后者更常用。
- 经典方法:
模型剪枝
- 核心思路是移除模型冗余部分,再通过知识蒸馏修复精度
- NVIDIA方案:用小校准集识别重要层/头/维度→剪枝→蒸馏
- 效果:15B模型剪至8B精度几乎无损,剪至4B仅有小幅精度下降
总结有损优化的两种实现路径:一是从头训练:直接设计高效架构并训练;二是知识蒸馏:用大模型(教师)训练更快的小模型(学生),继承大模型能力。
四、无损优化:Speculative sampling(推测解码)
4.1 核心洞察
校验比生成快:预填充(并行校验多个token)是算力受限,速度快;生成(串行生成单个token)是内存受限,速度慢。
4.2 算法流程

- 用轻量草稿模型提前自回归生成K个token
- 用目标大模型并行校验这K个token(预填充逻辑)
- 按概率接受正确的token,拒绝则从目标模型采样修正
4.3 关键特性
该方法能保证从目标模型得到完全精确的采样结果,实际可实现2倍左右提速。草稿模型越小越快,越接近目标模型精度越高,还可结合Medusa(草稿模型并行生成多个token)、EAGLE(草稿模型复用目标模型的高层特征)等优化。
五、系统级优化:处理动态负载
在实时流量中对序列进行批量处理是一项棘手的任务。
- 请求到达的时间各不相同(等待凑齐批量会拖慢先到达请求的响应速度);
- 序列之间存在共享前缀(例如,系统提示词或生成多个样本的场景);
- 序列长度不一(padding 操作会导致效率低下)。
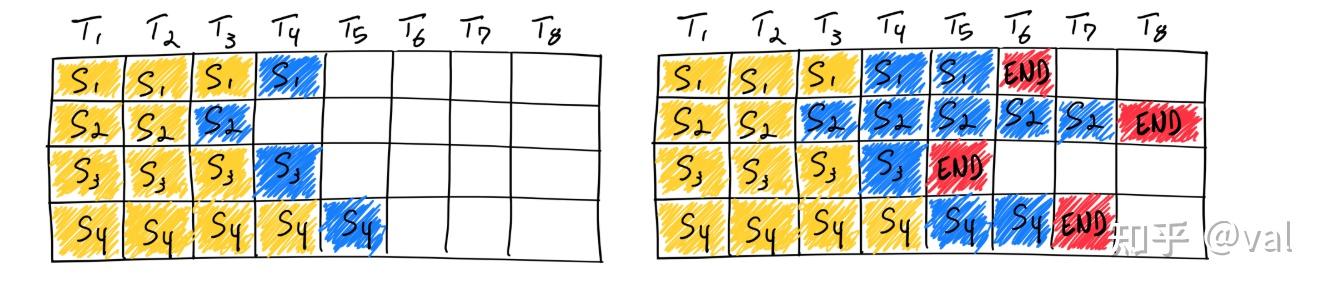
5.1 Continuous Batching
- Iteration-level scheduling(迭代级调度),每生成一个 token 后检查是否有新请求,动态加入批次不需等待。
- Selective batching(选择性批处理),对不同长度的序列,计算注意力的时候单独处理每个序列,MLP层将所有序列扁平化后并行计算。
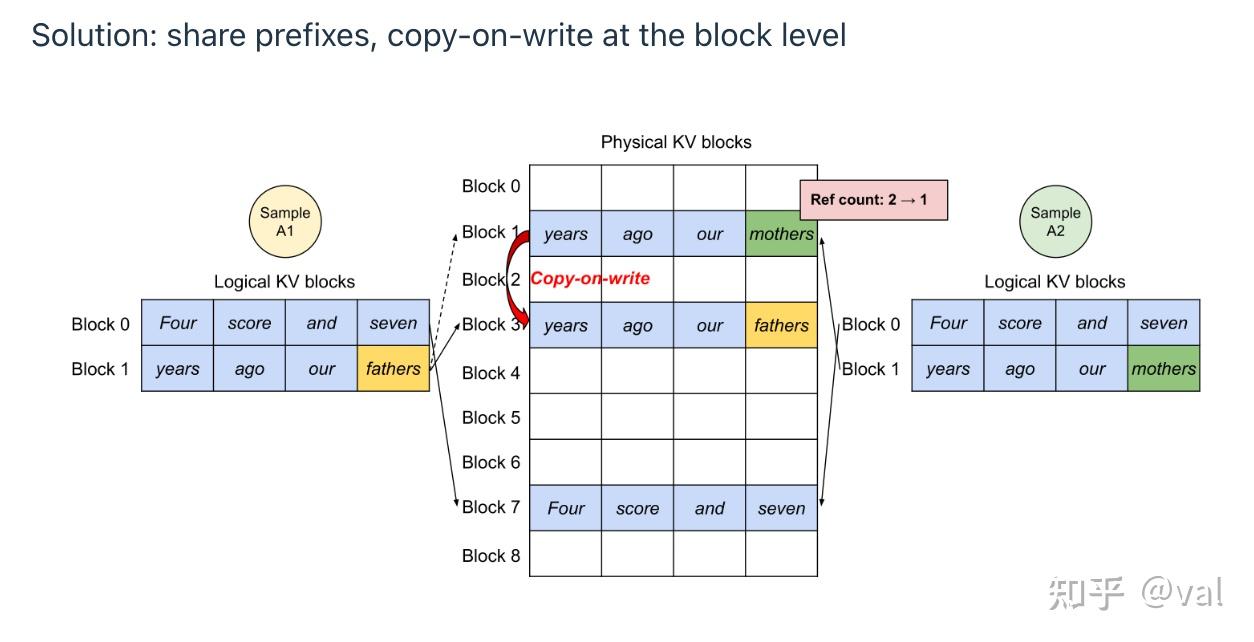
5.2 PagedAttention
- 问题:预分配固定大小的KV缓存导致严重的内存碎片(内部+外部)
- 借鉴操作系统虚拟内存机制,将KV缓存切分为固定大小的块,分散存储在空闲内存中;用页表管理块的映射关系,无需连续内存
- 结合写时复制(CoW)机制,共享前缀的序列复用缓存块,通过引用计数管理, diverge时复制分块(如系统提示、少样本提示)
六、课程总结
- 推理贯穿模型的使用、评估、训练全流程,是大模型落地的核心成本
- 推理与训练截然不同,生成阶段天然内存受限,核心瓶颈是KV Cache
- 优化技术:
- 很多理念源自系统领域(推测执行、分页机制)
- 新型架构在性能提升方面蕴藏着巨大的潜力