整理自 CS336 的 Lecture 9 和 Lecture 11。两讲都在回答同一个工程问题——给定有限算力,怎么精准预测超大模型的训练效果,避免无谓的试错浪费。
假设你有 100,000 块 H100,一个月。你要训一个最好的开源 LM,架构、数据集、分布式框架全都备好了。问题是超参数怎么选,参数量和数据量怎么分配,哪个架构值得押注。传统做法是挨个训大模型试,新的做法是先在小模型上建立定量关系,然后一次到位。Scaling Laws 讲的就是后者。
一、这不是什么新鲜事
Scaling Laws 这个思路,最早可能要追溯到 Bell Labs 1993 年的一篇 NeurIPS 论文,大意是在大型数据库上训分类器代价太高,我们需要在不完整训练的情况下预测模型好坏。他们给出的函数形式是测试误差 ≈ 不可约误差 + 多项式衰减项,换皮就是今天的缩放定律公式。他们甚至做了同样的事:训一批小模型,拟合曲线,预测更大规模的表现。
再往后是 Banko/Brill 的工作,研究 NLP 系统性能随数据量的变化——x 轴对数数据量,y 轴性能,直线关系,甚至讨论了"算法研发 vs 直接堆数据"的取舍,和今天预训练的思路如出一辙。
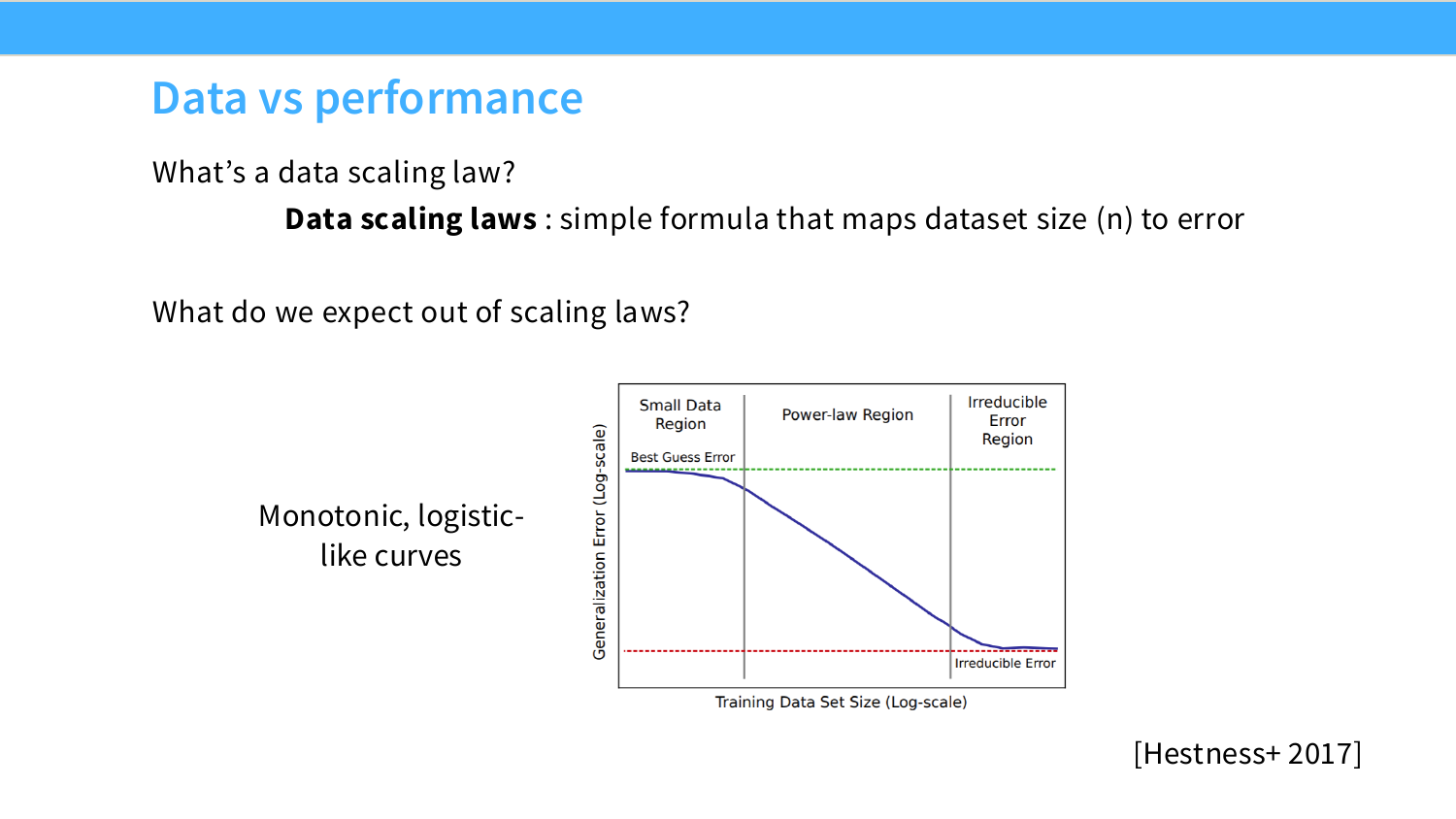
真正大规模的神经网络缩放定律实证是 Hestness et al. 2017(那时他们在百度),用机器翻译、语音、语言建模多个任务验证了误差以幂律形式下降。更重要的是他们提出了一个三段式框架:随机猜测区、幂律区、不可约误差区。
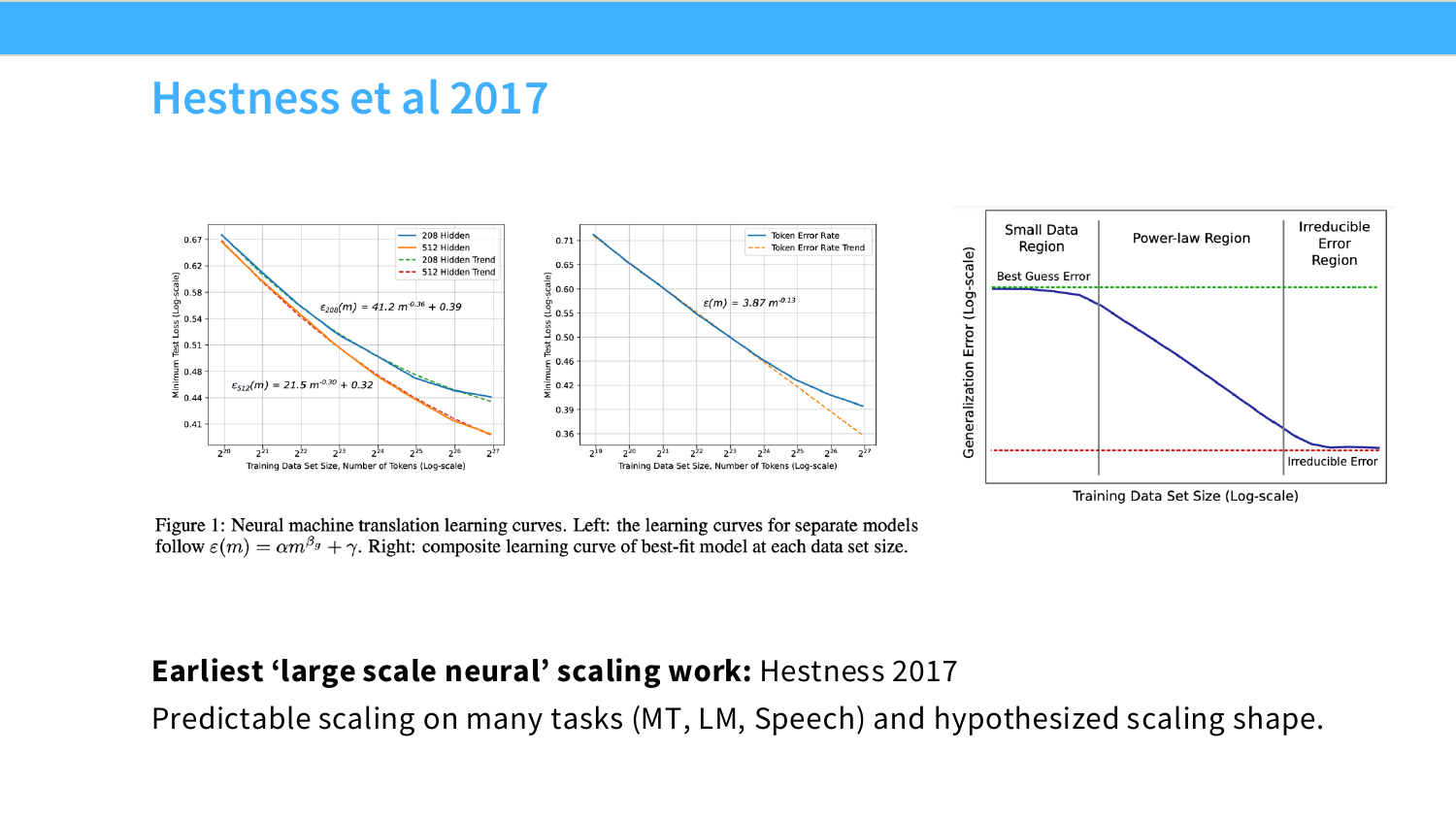
随机猜测区是模型还没学到东西,很难预测;不可约误差区是数据分布自身的熵下限,永远突破不了;中间的幂律区才是我们真正关心的,可预测,规律稳定。最近几年有人在谈"涌现能力"、"Scaling 计算是新事物",但仔细读过 Hestness 的人 2017 年就可以预见到这些了。
二、为什么是幂律
幂律的含义是在双对数坐标下 关于 是直线,等价于损失和数据量之间是多项式关系。
为什么多项式是自然的?从最简单的例子开始——估计一个 Gaussian 均值,n 个样本的估计误差是 ,斜率是 -1。往复杂推,如果是在 D 维空间里估计任意回归函数,用最简单的 nonparametric 方法(把空间切成小格子,每格取平均),推导下来误差是 ,斜率是 。
实际测到的斜率——机器翻译 -0.13,语音 -0.3,语言建模 -0.095——跟理论上的 -1 和 -0.5 差很远,原因就是自然语言的内在维度极高,每新增一倍数据,每个维度只能学到一点点。这个指数近似编码了任务本身的"学习难度"。-0.095 是语言这种高维数据的性质在实验中所展现的斜率。
三、数据缩放定律能做什么
基本公式(来自 Kaplan 2020):
有一个很有工程价值的结论是,数据成分对斜率没影响,只改变截距。你换数据混合比例——更多 Code,更多 Wikipedia,更少网页爬取——改变的是曲线在纵轴上的高低,但斜率不变。这意味着最优数据配比可以在小模型上确定,结论直接搬到大模型,不需要重新验证。
"我们要跑完互联网数据了怎么办"这个问题的答案是可以重复用数据,但大约 4 个 epoch 之后收益会急剧衰减,可以用修正的缩放定律建模"有效 token 数"随重复次数的变化来量化。给定训练 budget,多重复一遍精标数据还是用低质量的新数据,这两件事在缩放定律框架下也都可以量化再做决策。
使用时要注意三件事:一是不能进入饱和区,测数据缩放时模型要够大,测模型缩放时数据要够多,否则幂律就不成立了;二是只能预测预训练困惑度,下游任务的缩放行为远没那么稳定;三是双对数坐标下必须是干净的直线,有明显曲率或抖动就说明还没进入幂律区。
四、架构比较
传统做法是把候选架构都训到 GPT-3 规模再比。缩放定律的做法是在多个计算量级上都训一批,看曲线形状和相对偏移。
![]()
Transformer vs LSTM 的结论是,无论在哪个规模,LSTM 大概有 15 倍的计算效率劣势,对数坐标下是一条平行曲线,不会随模型变大消失。这个结论在小规模就可以看到,无需等到百亿级。Google E. Tay 等人做过更宏观的架构扫描,把一堆变体都跑了缩放曲线,只有两件事在缩放上稳定击败了标准 Transformer——GLU 和 Mixture of Experts。这就是今天工业界做 Switch Transformer 和 SwiGLU 的底层依据之一。
有个容易踩的坑是嵌入层参数不能混入非嵌入参数的分析中。嵌入层的缩放行为异常,会让双对数图出现弯曲,污染整个分析。
五、给定算力,参数和数据怎么分?
数据和架构都选好之后,还需要确定:给定总算力预算,应该训一个大模型用少量 token,还是一个小模型用大量 token?
这就是 Chinchilla 2022(DeepMind)解决的问题。他们系统地做了 isoflop 分析——在同等 FLOP 下,扫描不同的参数量和 token 数组合,找每个算力量级下的最优点,然后拟合出那条最优曲线。
结论是 20:1——每个参数对应 20 个训练 token。这当时推翻了"参数比数据重要"的普遍看法(GPT-3 用了约 1:1 的比例,严重欠训练数据)。
但 20:1 是"最小化训练计算量"下的最优解,不是"最小化总成本"的最优解。训练完之后模型要推理多年,推理成本才是真正的大头。从推理成本角度,用更多数据训一个更小的模型,部署才更便宜。各家自己跑的结果——Llama 3 70B 大约 39:1,Hunyuan-Large(MoE,活跃参数)96:1,MiniCPM 192:1——20 其实是一个不太稳定的基准。直接抄 20:1 不如自己做一次 isoflop 分析。
六、超参数怎么跨规模迁移
Chinchilla 分析解决了"训多大、训多久"的问题,但还有一个问题没解决:超参数怎么选?
小模型调好的学习率,放到大模型上往往就失效了——因为随着模型宽度增大,最优学习率会持续下移。每次换规模都要重新搜索,而在大模型上搜索超参数代价极高。
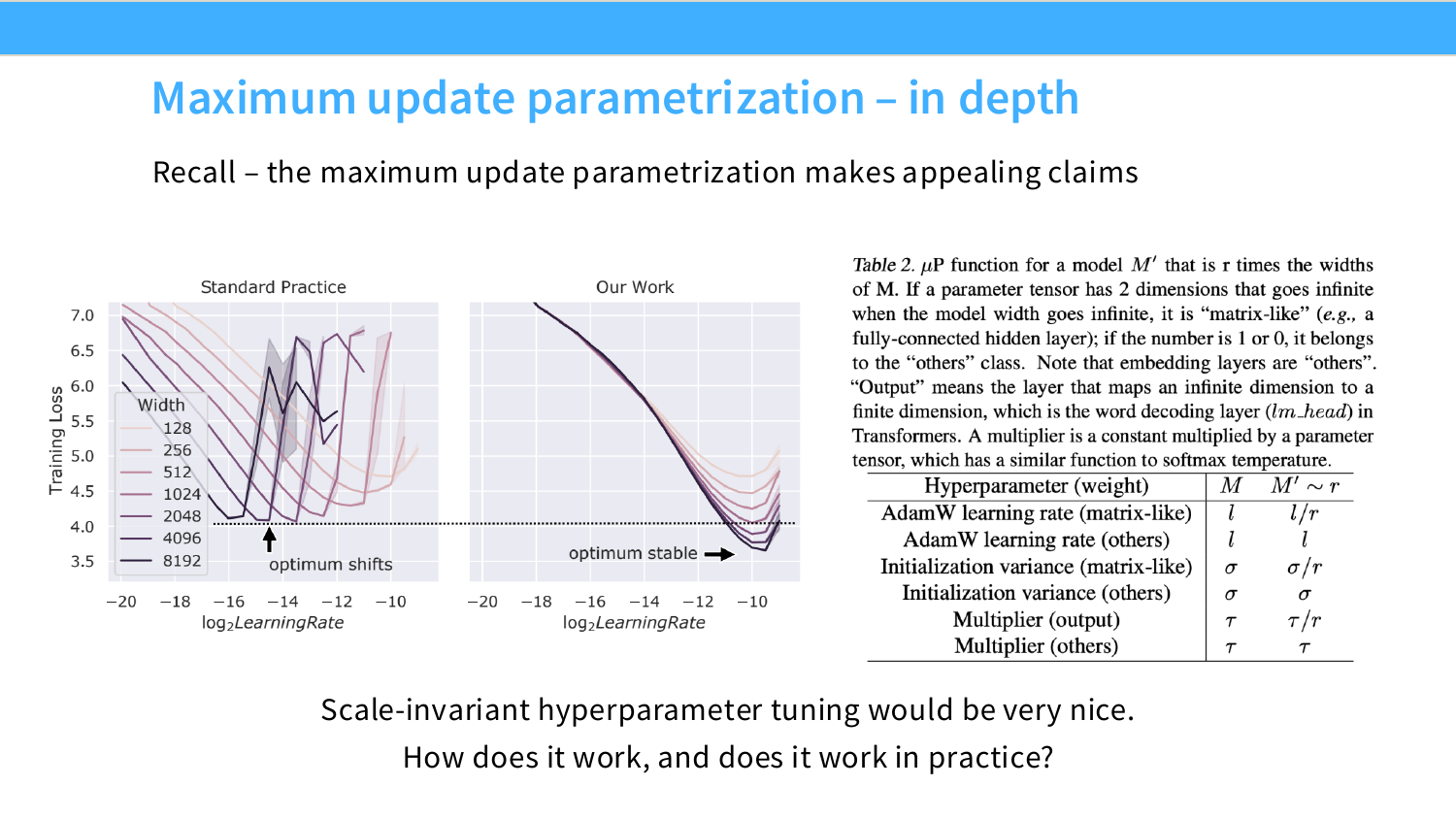
上图左边是标准参数化(Standard Practice):不同宽度的模型,最优学习率(图中各条曲线的最低点)持续向左漂移。右边是 muP:最低点在同一位置稳定不动。这就是 muP 解决的问题——让超参数跨规模稳定,一次调好,直接用到大模型。
muP 的核心操作
muP 基于两个假设:激活值的量级在宽度增大时保持稳定,以及一步梯度更新带来的激活值变化也要保持稳定。从这两个假设可以推导出:
- 初始化标准差 ,和标准 Kaiming 初始化一样,这部分不用改
- 学习率(Adam),每层不同,随宽度成反比——这是和标准参数化真正不同的地方
- Attention 内积缩放用 替代
对 SGD 来说 muP 和标准参数化差别不大;真正的区别在 Adam 上——如果你用 Adam(绝大多数情况都是),per-layer learning rate 才是要改的东西。
muP 的失效场景:可学习的 LayerNorm 增益或偏置、非标准优化器、过强的权重衰减(如 0.1)都会破坏迁移。另外 muP 不是必要条件,DeepSeek 没用 muP 也训出了好模型,只是学习率需要随规模手动调整。muP 的价值是让这个调整变可预测,不是 0 到 1 的开关。
七、工业界实际是怎么做的
有了"参数-数据最优比"和"超参数跨规模迁移"这两块,就可以看各家是怎么把它们组合成一套完整的训练配方的。
Cerebras-GPT 训了 0.1B 到 13B 的完整系列,这是 muP 最早的大规模公开验证之一。做法是压缩到 40M 极小模型做超参搜索,然后通过 muP 规则迁移到更大规模。标准参数化下损失曲线有抖动,muP 下和理论预测高度吻合。不是 muP 让模型更好,是 muP 让超参数更可预测——在小模型上把事情定好之后,你对放大之后的行为有更高的置信度。
MiniCPM 用了 muP,同时引入了一个叫 WSD 的学习率调度器来降低 Chinchilla 分析的成本。
做 Chinchilla 分析需要多个不同 token 数的训练结果。标准余弦调度的问题是每个终止时间点对应一条不同的余弦曲线,checkpoint 不能复用,n 个终止点就要从头训 n 次,是 的代价。
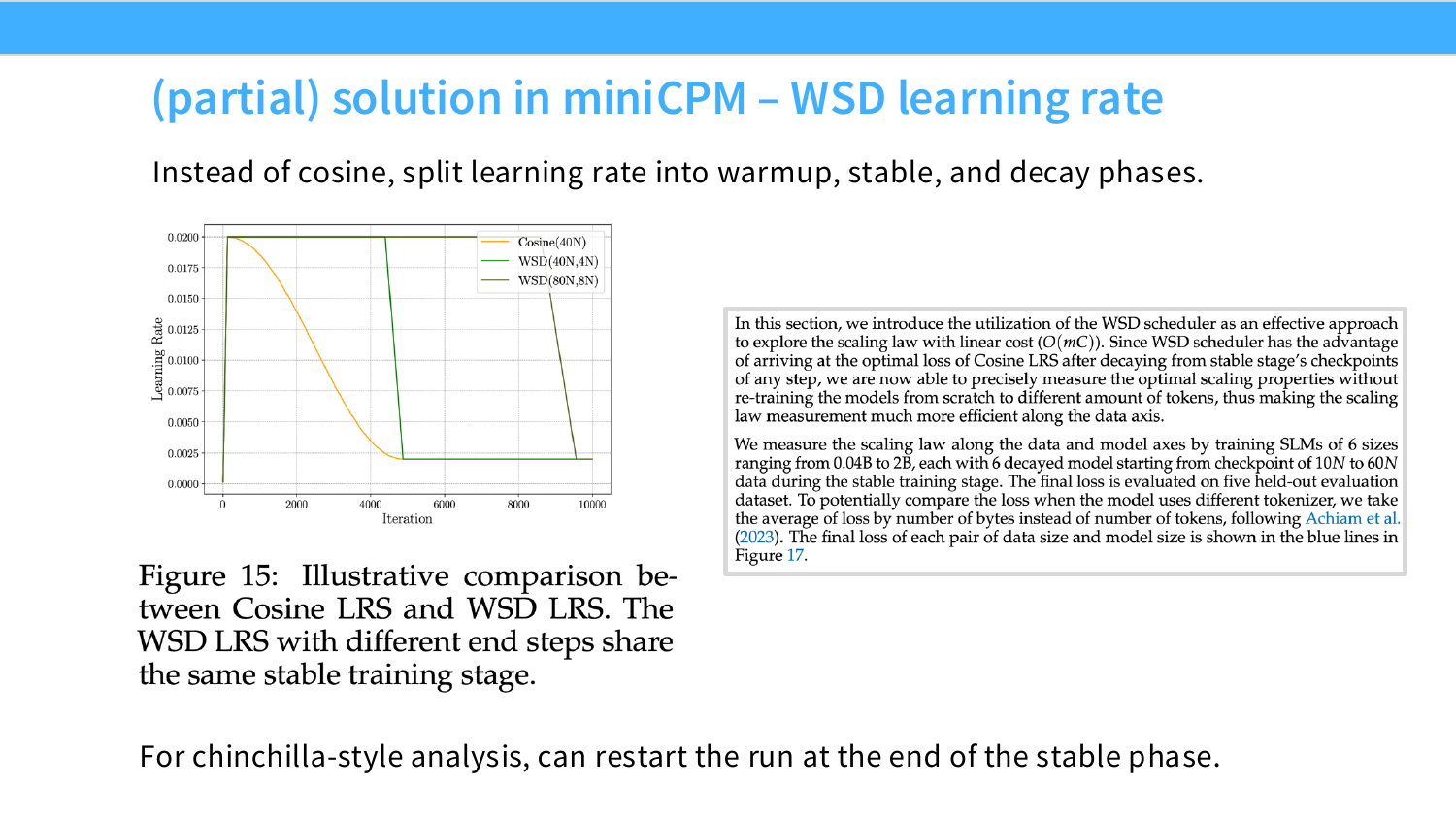
WSD 把学习率变成梯形——上升、平台期、下降。平台期的 checkpoint 可以复用,只需从某个节点开始下降就等同于完整训练到那个 token 数的结果,代价降到 。
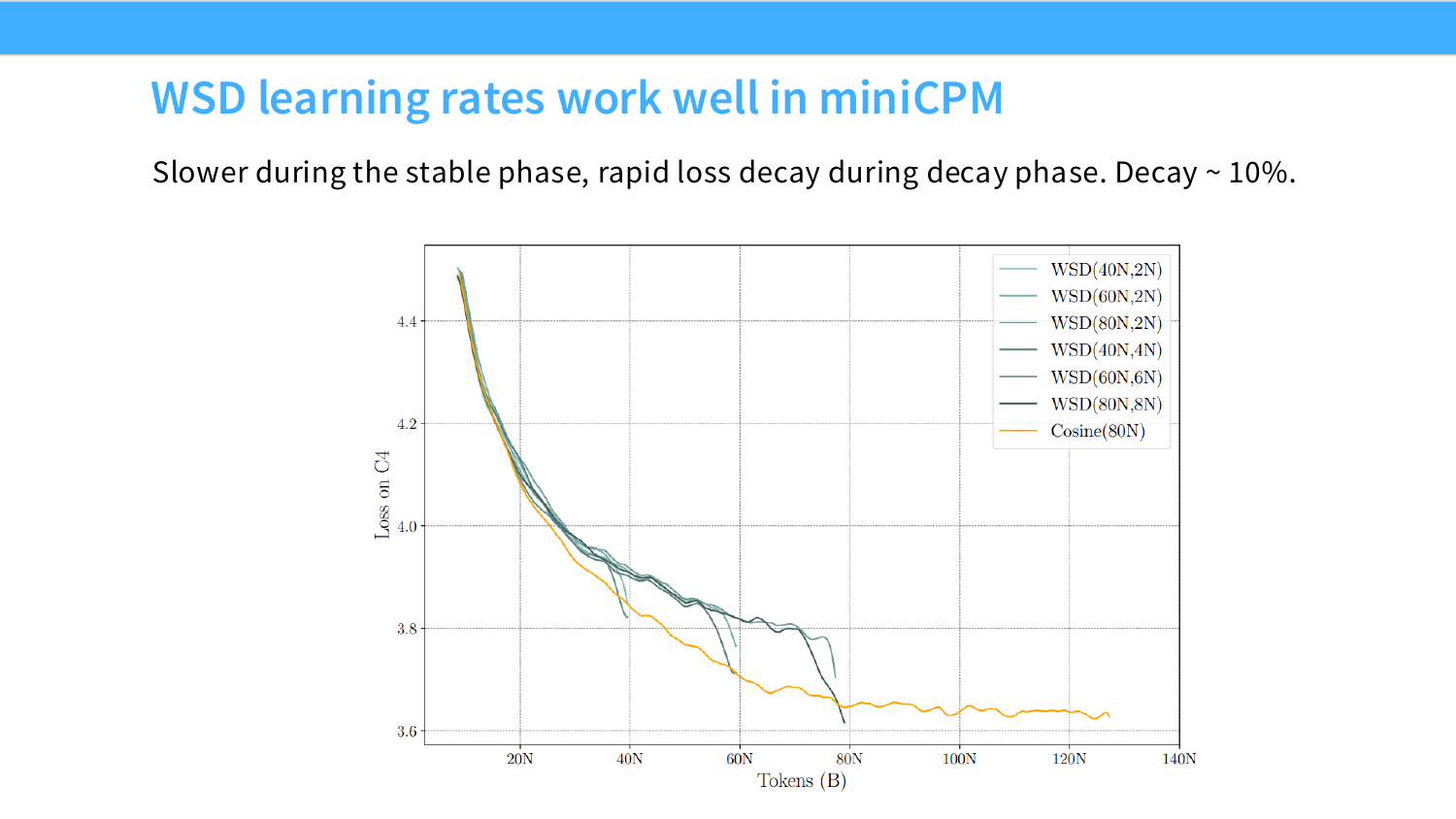
用 WSD 训练时 loss 曲线会呈现"长平台 + 急速下降"的形状,看起来很奇怪,但在每个 token 数节点上实际都不输余弦。MiniCPM 的 muP 验证结果如下——不同规模模型的最优学习率落在同一位置,跨 4 个数量级稳定:
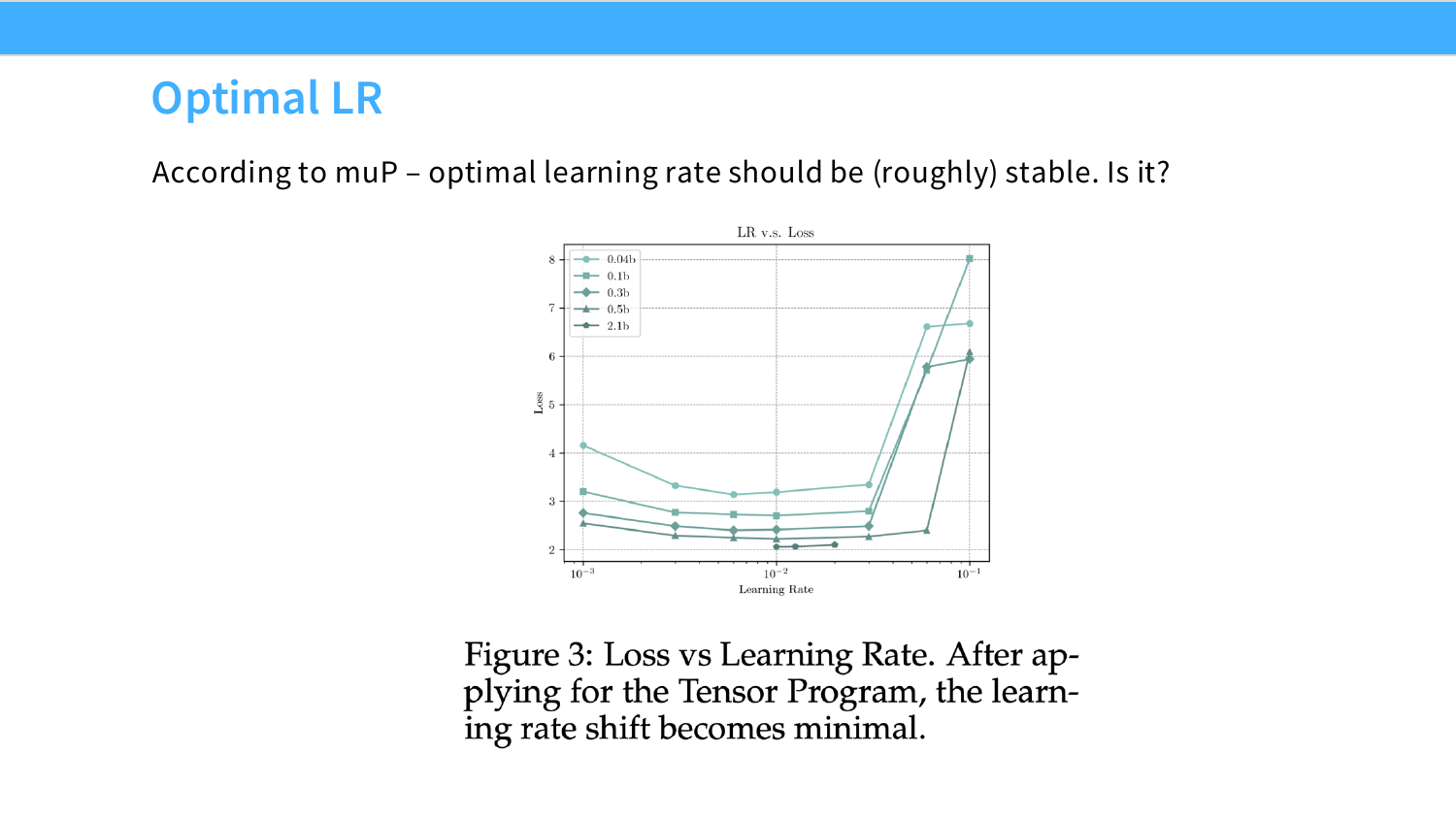
DeepSeek 完全不用 muP。取两个小规模模型,每个规模都做 batch size × learning rate 的网格搜索,找最优点,然后拟合这两个最优值随 FLOP 的变化曲线,外推到大模型。
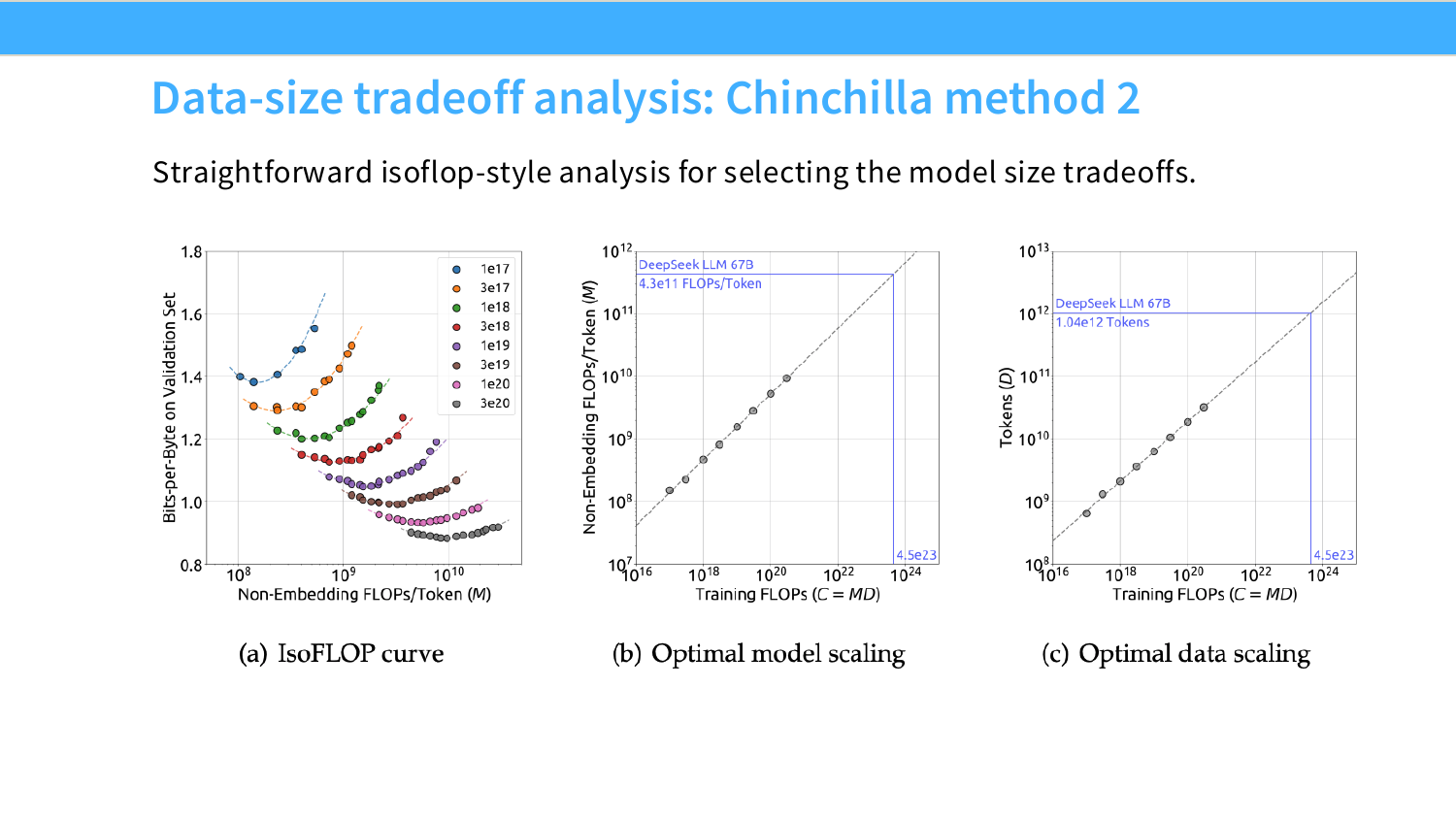
他们的 Chinchilla isoflop 分析拟合得非常干净——不同算力量级下的最优模型大小和 token 数都在一条平滑曲线上。batch size 的拟合也很干净;learning rate 的拟合稍微可疑一点(一条水平线可能也能解释数据),但他们用了斜线,7B 和 67B 的最终 loss 也完全符合小规模外推的预测。
三种路径底层逻辑是一样的——在小模型上做大量实验,建立定量关系,一次性打到大模型。区别只是 muP 需要改初始化和 per-layer 学习率,工程侵入性稍高;直接拟合更朴素,但要求对缩放定律有较强的信念。
八、批量大小
稍微补充一个常被忽视的细节。Batch size 小于某个阈值时,加倍 batch size 近似等于多走一步梯度,系统并行和优化效率同时赚到。超过这个阈值之后,额外样本不再减少有效噪声,进入边际递减。这个阈值就是 critical batch size。
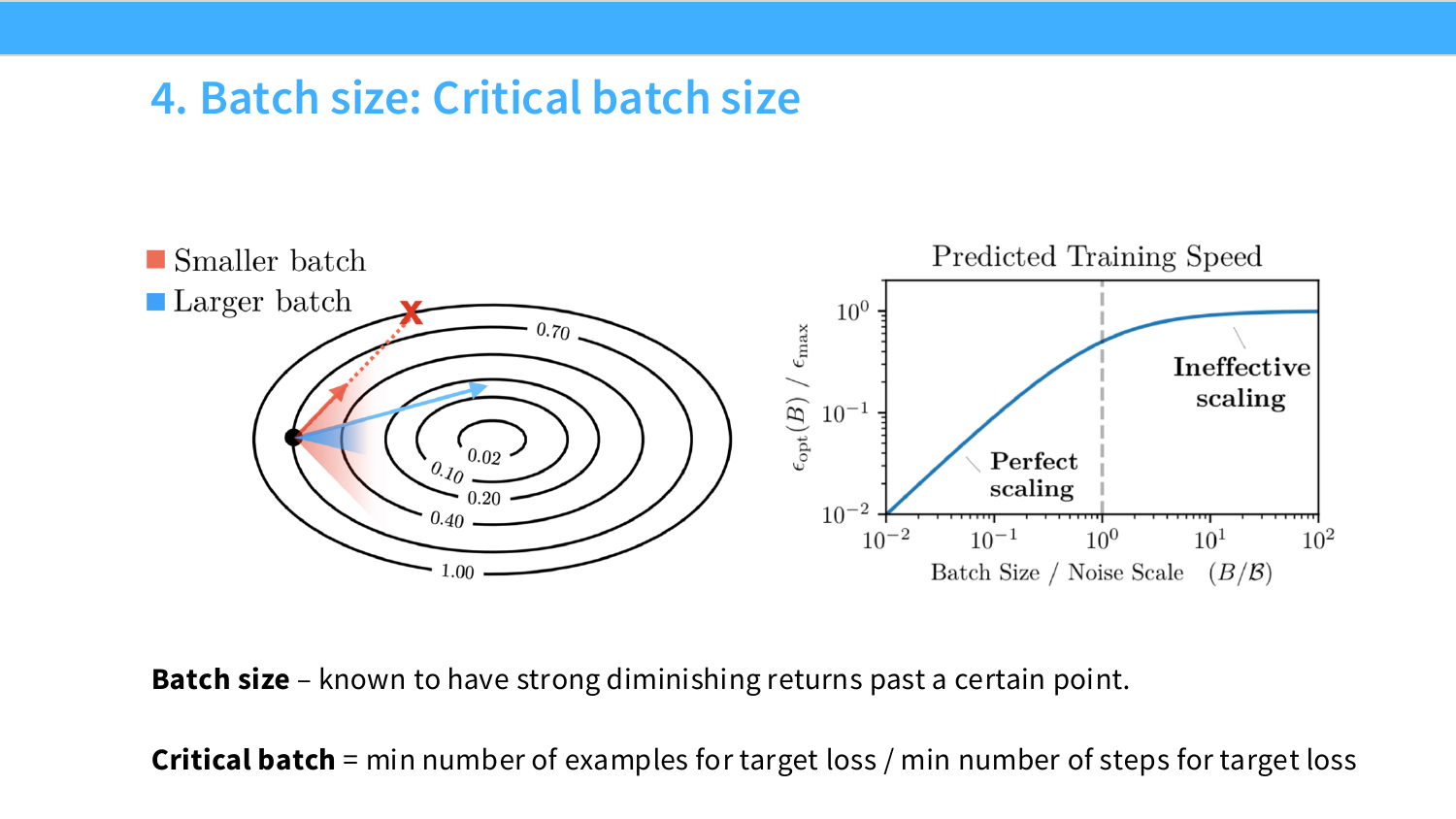
有趣的是 loss 越低,critical batch size 越大。模型训练到后期 loss 已经很低,这时候可以用更大的 batch size 继续保持效率。Llama 3 的训练报告里会出现"训练途中增大 batch size",就是这个性质的直接推论,不是任性操作。
核心要点
Scaling Laws 的本质:用万级算力的小实验,指导百亿级算力的大模型训练。它是一个工程决策工具,并非精准的物理定律。
幂律斜率的含义:它编码了任务的内在维度和学习难度。特定在语言这种高维数据上的实验结果就是 -0.095 。
**Chinchilla 20:1 不是 Magic Number **:各家的实际复现都各有差异。做自己的 isoflop 分析更靠谱。
muP 的核心差异:对 SGD 来说 muP 跟标准参数化差别不大;真正的区别在 Adam 上——per-layer learning rate 随宽度成反比。如果你用 Adam,这才是要改的东西。
WSD 调度器:不是因为它比余弦更好,而是因为它让 Chinchilla 分析的成本从 降到 。工程 hack,不是理论突破。
不同路径殊途同归:Cerebras/MiniCPM 用 muP,DeepSeek 用直接拟合,Llama 3/Hunyuan 做 isoflop 分析。底层逻辑是一样的:small-scale experiments → extrapolate → nail it once。