将预训练完成的基础模型(如GPT-3)转化为实用、安全的指令跟随模型(如ChatGPT),重点讲解监督微调(SFT)与基于人类反馈的强化学习(RLHF)两大后训练核心技术。
本节课的结构大致参照 InstructGPT 论文,因为我们今天使用的大部分后训练流程仍然源自这篇论文。
一、课程背景与目标
预训练是将海量通用数据打包进模型参数,赋予模型推理、问答的潜力,而后训练则是通过针对性的数据和算法,引导模型展现我们期望的行为,让预训练模型学会遵循指令,提高安全性和产品化价值低。从 GPT-3(仅预训练)到 ChatGPT(预训练+后训练),后者彻底改变了大模型的落地形态。
本节课的核心问题是,
- 我们需要什么样的后训练数据?
- 如何高效利用这些数据调整模型行为?
- 如何规模化后训练过程,同时保证安全性?
标准后训练三阶段流程(InstructGPT范式)
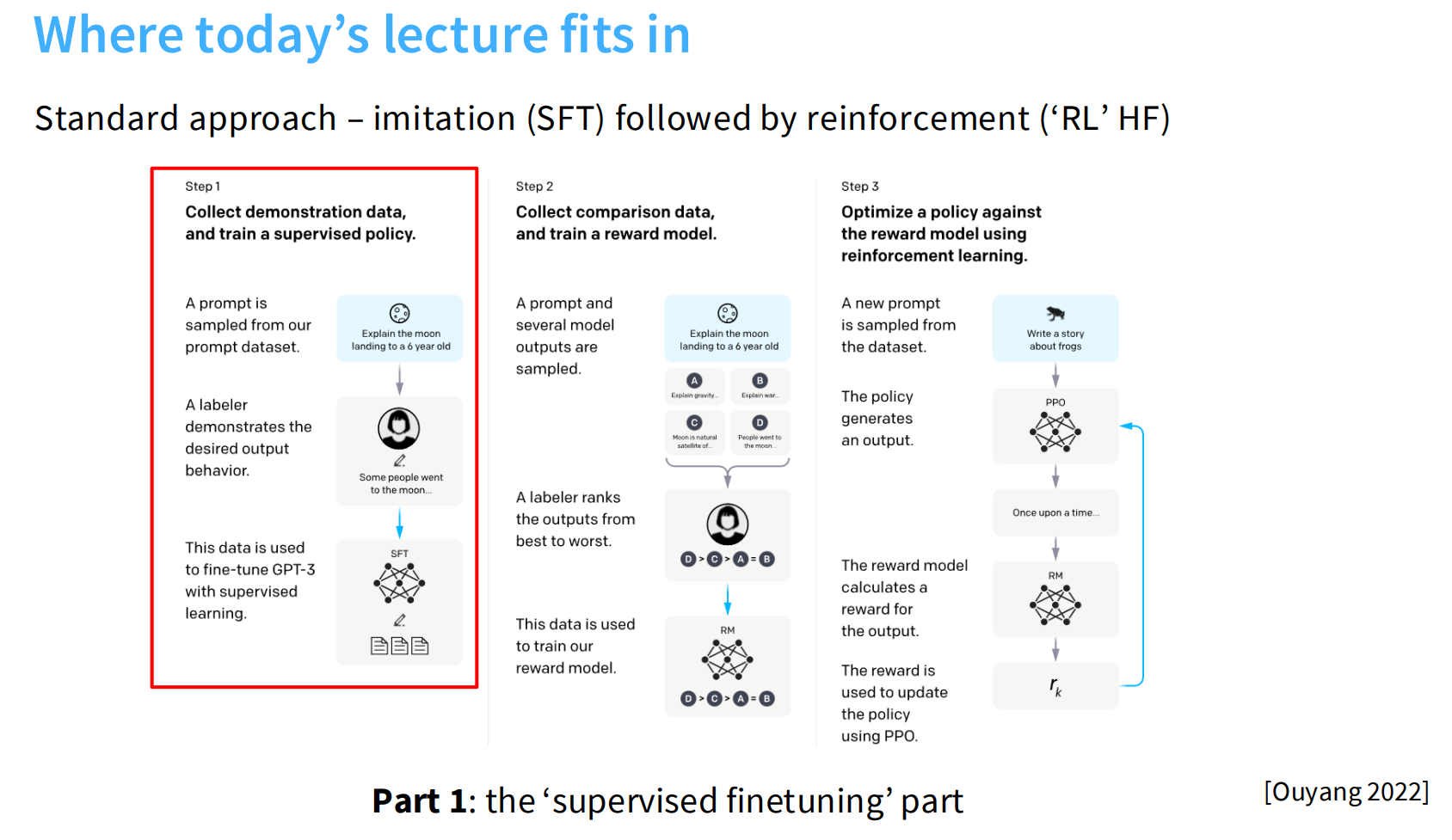
这个图大致描述了构建指令跟随模型的标准方法:先模仿(SFT),再进行强化(RLHF)。
- 监督微调(SFT):用专家演示数据训练模型模仿人类行为
- 奖励模型(RM)训练:用人类成对偏好数据训练评分模型
- 强化学习(RL):用奖励模型作为监督信号,通过PPO算法优化模型策略
下面我们就分SFT、RLHF两部分展开。
第一部分:监督微调(SFT)
SFT的本质是行为克隆:让模型模仿人类专家的输出,学习"应该怎么回答问题"。其效果取决于两个要素:训练数据质量和微调方法。
我们都知道数据非常重要,在后训练阶段更是如此。因为你只用非常少量的数据,就能让模型表现出你想要的精确行为。所以如果你的指令微调数据有噪声,模型就会产生一些非常奇怪的行为。
下面是三种不同构建方式的指令微调数据集的对比:
| 数据集 | 构建方式 | 核心特点 | 优缺点 |
|---|---|---|---|
| FLAN(谷歌) | 聚合69个现有NLP任务数据集(问答、分类、摘要等) | 数据量大、任务覆盖广、获取成本低 | 格式人工改造痕迹明显,与真实聊天交互差异大,回答普遍简短 |
| Alpaca(斯坦福) | 用175条人类种子指令+GPT-3生成更多指令+InstructGPT生成回答 | 格式接近真实用户输入,回答为长文本自然语言 | 指令多样性不足,存在生成式数据的固有偏差 |
| OpenAssistant | 全球线上爱好者众包编写 | 回答质量高、细节丰富,部分包含引用来源 | 收集成本极高,规模有限 |
人类和AI评判者都存在强烈的长回答偏好(约60%-70%的概率选择更长的回答)和列表格式偏好。这种偏好与事实正确性无关:即使长回答包含更多幻觉,也更容易被评为"更好"。 不能仅依赖开放式偏好评估,必须结合MMLU、GSM8K等客观基准测试。
在模型不知道的事实上进行SFT,会严重加剧幻觉。比如,训练模型输出引用格式时,如果模型本身不知道对应的文献,它会学会"只要遇到复杂问题,就在结尾编造一个引用"。对于模型的损失来说,编造一个引用比完全不写引用的错误要小。回答的结构必须被完整填充,因为你必须在正确的位置填上 token。约翰・舒尔曼(John Schulman)观点是,SFT只能"提取"模型预训练中已经存在的知识,不能可靠地注入新知识。强行注入会导致模型学习"格式捷径"而非真实知识。
这也是为什么基于策略的强化学习方法很重要的原因之一,因为你想知道模型已经知道什么,只教它那些它能做到的事情,以避免它产生幻觉。当它遇到不知道的事实时,也许你应该修改你的微调数据,让它说 "哦,我不知道这个事实",而不是强迫模型去回答。
指令微调有一个非常反直觉的现象,那就是一个完全正确、内容非常丰富的指令微调数据集,实际上可能对语言模型不是一件好事,因为它会教你的语言模型试图编造事实来匹配那种知识深度。
这就是我们要非常小心处理蒸馏数据(当教师模型比学生模型更强时)以及人类标注数据(当人类可能比模型知识渊博得多时)的原因之一。要让模型在不知道的时候能够得体地表示不知道。强化学习式的正确性优化可能会有所帮助,而在指令微调层面优化这个问题非常混乱和困难,至少在公开的研究文献中,人们还没有完全解决这个问题。
另外一个作用方面是安全性。少量安全数据即可大幅提升模型安全性。大概500条安全指令样本,就能让模型学会拒绝恶意请求,达到一个合理的水平。挑战在于如何平衡"拒绝有害请求"和"避免过度拒绝"。例如模型可能将"如何杀死一个Python进程"误判为有害请求而拒绝回答。
4. SFT的方法演进
(1) 基础方法:梯度下降
学术场景的标准做法:将指令和回答拼接成序列,用普通的自回归损失进行微调。这个方法代码很简单,本质上与预训练的训练循环完全一致。
(2) 中期训练(两阶段训练)
工业界预训练与后训练的边界逐渐模糊,有一个概念是mid-training(中期训练),它将原本SFT使用的数据混合到了预训练的最后阶段(学习率衰减阶段)。典型流程如下(miniCPM为例):
- 第一阶段(稳定阶段):纯预训练数据(Common Crawl、代码、书籍等)
- 第二阶段(衰减阶段):混合高质量预训练数据(维基百科)+ 指令微调数据(UltraChat、Stack Exchange、Evol-Instruct等)
- 最后进行一轮简短的纯SFT
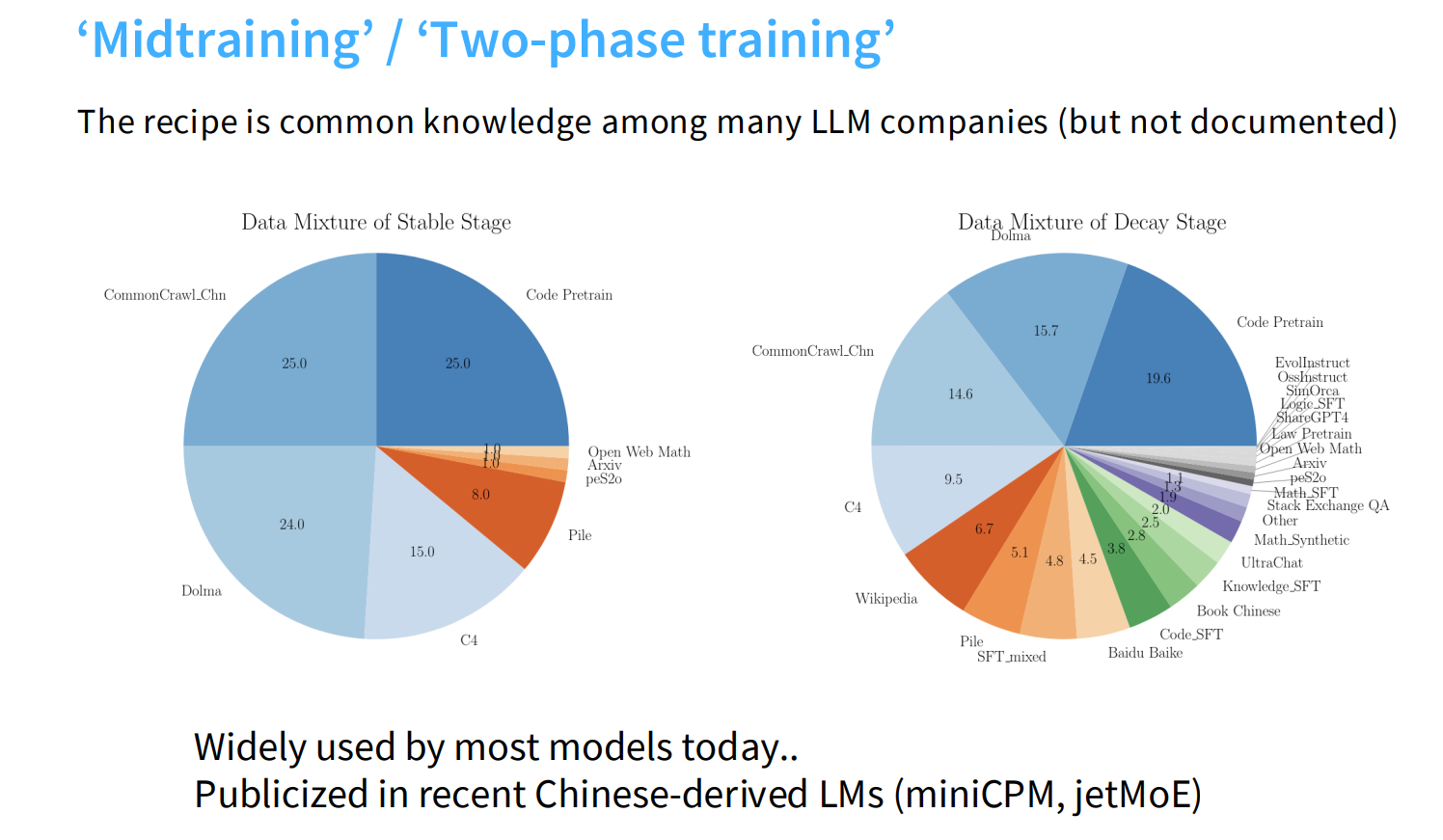 这样做的优势是可以避免灾难性遗忘,更好地利用指令数据,大幅提升最终效果;但是副作用是"基础模型"的定义越来越模糊——现在公开的所谓"基础模型",大多已经经过了隐式的指令调优。
这样做的优势是可以避免灾难性遗忘,更好地利用指令数据,大幅提升最终效果;但是副作用是"基础模型"的定义越来越模糊——现在公开的所谓"基础模型",大多已经经过了隐式的指令调优。
第二部分:基于人类反馈的强化学习(RLHF)
1. 从模仿到优化:为什么需要RLHF?
SFT需要人类专家生成完整回答,对于7B模型,SFT的标注成本约2.5万美元,而成对反馈(Pairwise Feedback)的标注成本仅约4000美元。成对反馈即给同一个问题的两个或者多个回答,让人挑哪个更好,是 RLHF 里专门用来训练 "裁判模型(奖励模型 RM)" 的数据。就像我们偶尔会在使用AI的时候被问到 "这个回答更好还是那个回答更好?",成对反馈就是在模拟这种评判过程。而且人类往往更擅长"判断哪个回答更好",而不是"写出最好的回答"。
2. RLHF的数据:成对偏好反馈
标准收集流程是用SFT模型对同一提示生成多个回答,然后让标注员对回答进行排序(通常是二选一的成对比较),用这些排序数据训练奖励模型,为任意(提示, 回答)对输出一个标量奖励值。主流评估维度是InstructGPT提出的三大支柱——有用性、真实性、无害性。
但在实际数据生产中,获得高质量、可验证的标注员非常困难。众包标注质量低、易受 AI 污染而且存在伦理与人口统计学偏差(比如标注员大多数是菲律宾人和孟加拉国人,用这些标注出来的模型不知何故比以前更与东南亚宗教对齐了)。后来人们就发现,GPT-4作为评判者的与人类的一致性,已经接近人类标注员之间的一致性,且成本低得多。主流应用有:
- UltraFeedback:开源的大规模AI反馈数据集
- 宪法AI(Anthropic):让模型根据一套"宪法"原则自我批判和改进
- Tulu3、Zephyr等开源模型:完全基于AI反馈完成RLHF,效果超过早期人类反馈模型
3. PPO:RLHF的原始算法
InstructGPT使用的原始算法,核心目标函数是:
- KL惩罚项:防止RL策略与原始SFT模型偏离过远,避免奖励过拟合
- 预训练损失项:缓解灾难性遗忘
PPO的缺点是实现极其复杂,调参困难,稳定性差。
DPO:彻底简化RLHF的革命
DPO(Direct Preference Optimization,直接偏好优化)在2023年提出,彻底简化了RLHF流程,目前几乎所有开源RLHF模型都使用DPO。
DPO的核心目标是彻底简化PPO的复杂实现。它去掉了PPO必需的奖励模型和在线rollout循环,本质是在成对偏好数据上做加权监督学习:对好的回答做正梯度更新,对坏的回答做负梯度更新。
-
RLHF原始目标:最大化期望奖励,同时用KL散度约束策略不偏离参考模型
-
非参数假设:假设策略类包含所有可能函数,则最优策略可表示为
由此可反解出隐含奖励:
-
代入Bradley-Terry偏好目标,得到最终DPO损失
DPO梯度的直观解释
- 当隐含奖励模型预测错误时,梯度更新幅度更大
- 本质就是"给好的东西加权,给坏的东西降权"
DPO的主流变体
DPO催生了数十种"*PO"变体,其中两个在工业界被广泛验证:
-
SimPO:
- 去掉了参考模型,失去了原有的数学严谨性,但保留了核心思想。同时加入了长度归一化:按回答长度缩放梯度幅度
-
长度归一化DPO:保留参考模型,仅在DPO目标中加入长度归一化项,解决了原始DPO偏向短回答的问题
RL研究的重要警示:结果高度依赖实验设定
强化学习中几乎没有通用结论,所有结果都高度依赖具体实验条件。AI2团队早期研究发现PPO优于DPO,但在后续Tulu 3工作中发现:高质量的SFT可以吃掉PPO和DPO的所有收益,只有带长度归一化的DPO能在SFT基础上获得小幅提升。不要把任何单一论文的实验结果当作绝对真理
RLHF的两大致命问题
RLHF存在两大致命问题,这也是催生RLVR(基于可验证奖励的强化学习)的核心动机:
-
过度优化(Overoptimization):本质是奖励模型的过拟合:随着RL训练步数增加,代理奖励持续上升,但真实人类偏好胜率先升后降。普遍存在于人类偏好和带噪声的AI反馈中,但不存在于无噪声的可验证奖励中。根本原因是人类偏好的噪声性和复杂性
-
校准性丧失:RLHF将模型从"概率分布建模"转变为"策略优化",不再是校准的概率模型。表现为:温度=1时模型严重过度自信,输出结果的置信度与实际准确率不匹配。这是设计使然,因为校准性从未被加入奖励函数
四、课程总结
- 指令微调(SFT)的威力远超预期:仅用少量高质量数据,就能让基础模型表现出类似ChatGPT的行为。
- 数据是后训练的核心:"高质量数据"的定义非常复杂,需要综合考虑风格、知识、安全性等多个维度。
- SFT只能"提取"预训练知识,不能可靠注入新知识,强行注入会导致幻觉。
- DPO彻底简化了RLHF,但本质上仍是加权监督学习,核心是"给好的加权,给坏的降权"。
- RLHF存在过度优化和校准丧失两大致命问题,这些问题催生了基于可验证奖励的RLVR方法。
- 预训练与后训练的边界正在消失:中期训练已成为工业界标准做法,重新定义了"基础模型"的概念。