本文首发于知乎,现迁移至个人博客。
目录
一、MoE 的定义与基础架构
MoE 是对 Transformer 的 FFN 层做稀疏化改造,用路由选择层 + 多个稀疏激活(sparsely activated)的 FFN 专家模块,替换 Transformer Block 中单一的稠密 FFN 层。
- MoE 与稠密 Transformer 的唯一区别,仅在 FFN 层,自注意力层完全无改动;
- 工业界 99% 的落地 MoE 都只改造 FFN,对注意力头做 MoE 稀疏化的方案仅停留在论文阶段,无大规模落地 —— 这类方案训练稳定性极差,收益无法覆盖研发成本。
- MoE 在不增加前向传播浮点运算量(FLOPs)的前提下,大幅提升模型总参数量,让模型获得更强的知识记忆与特征拟合能力。
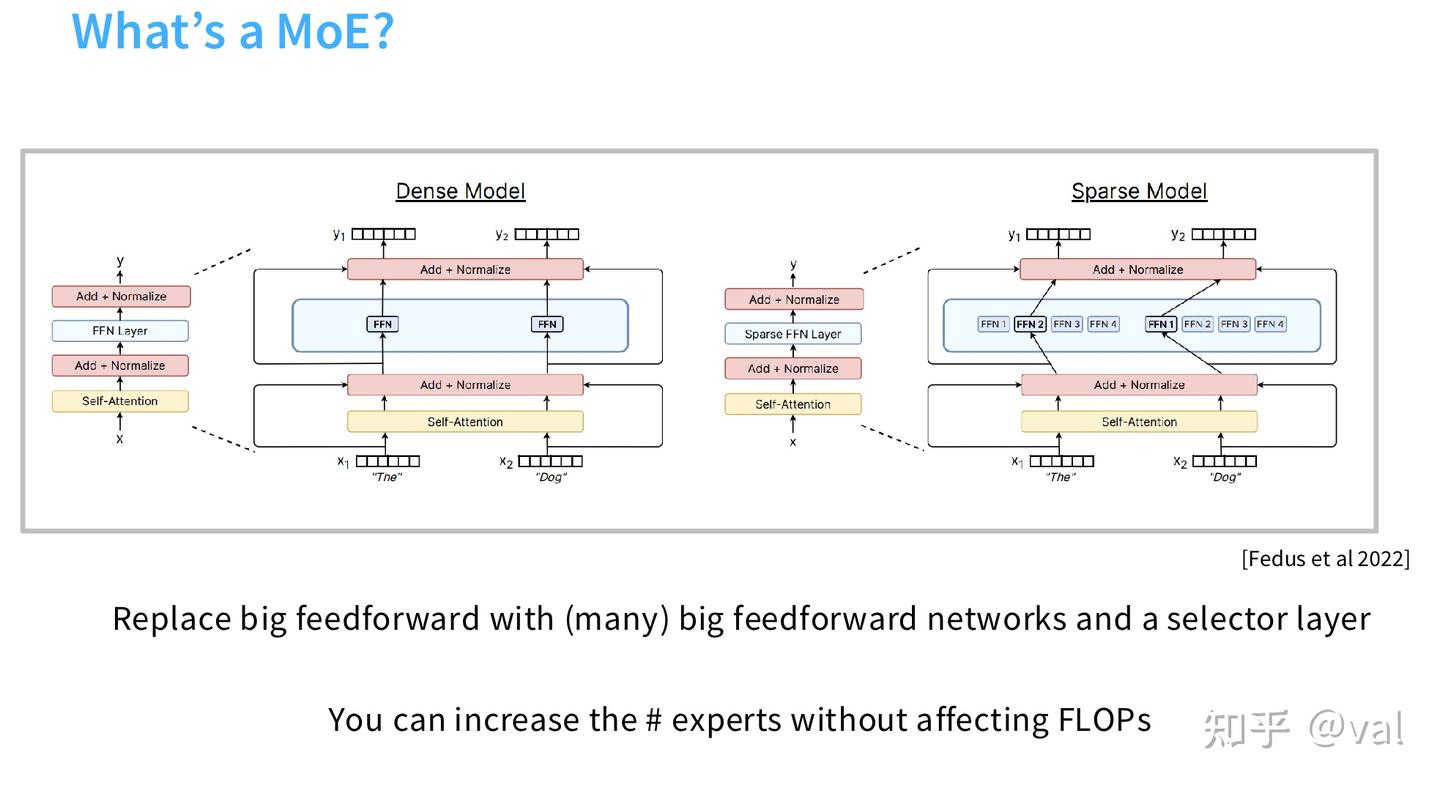
二、MoE 成为行业主流的主要原因
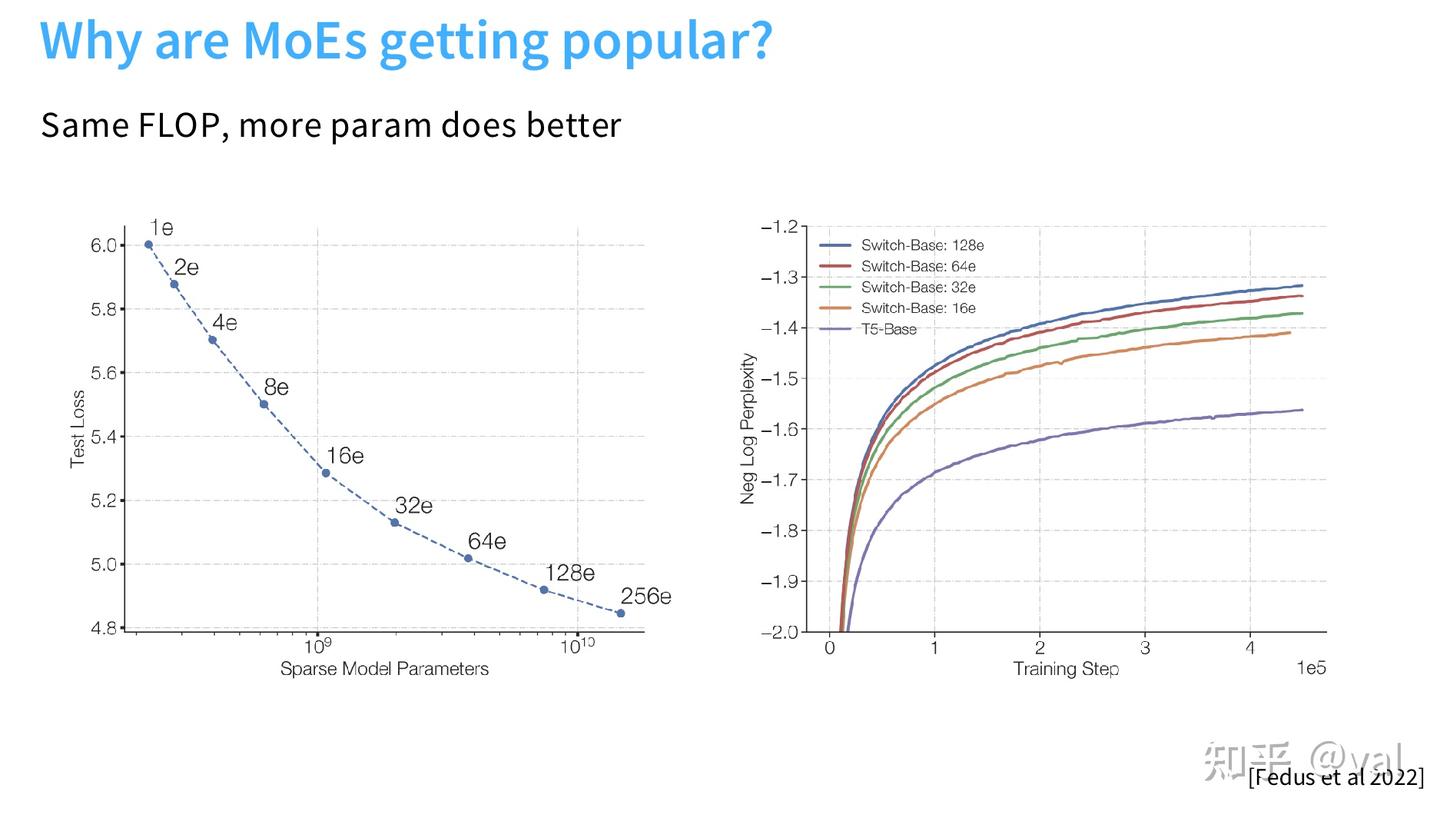
(1)同等FLOPs下,效果远超稠密模型
- Fedus et al. 2022 的对照实验显示,在训练算力完全一致的前提下,随着专家数量增加,语言模型的训练损失持续下降,128 专家的 Switch-Base 模型,困惑度下降速度远超同算力的稠密 T5-Base 模型;
- OlMoE 也复现验证了 MoE 模型达到同等下游效果,所需FLOPs比稠密模型少3倍,训练速度快2倍,算力效率优势很明显。
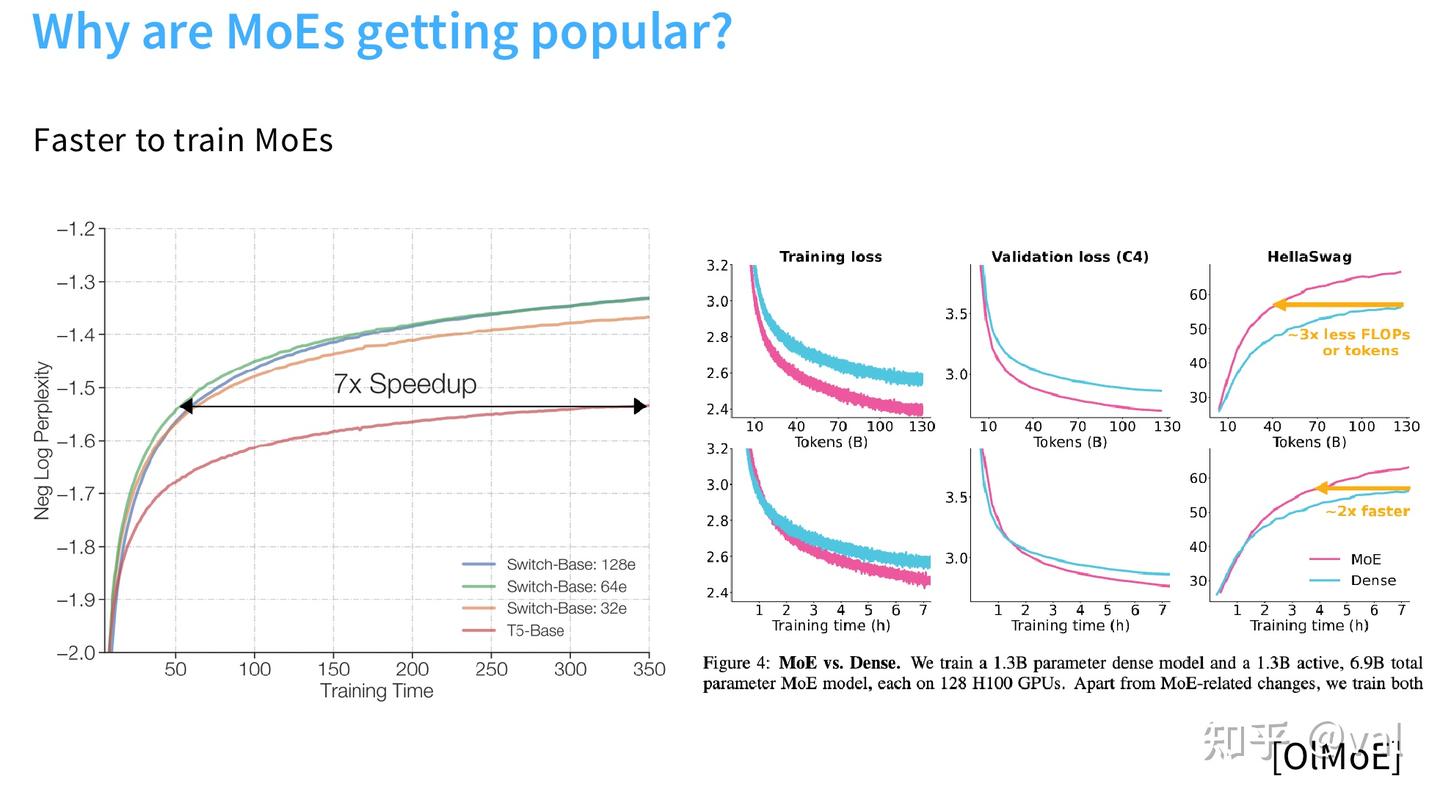
实际上哪怕不用任何可学习的智能路由,纯哈希随机分配 Token 的MoE,效果也比同FLOPs的稠密模型好。 MoE 的效果收益,不完全来自“把 token 分给合适的专家”,更大程度来自「稀疏架构本身带来的参数扩容收益」。哪怕路由完全没有语义匹配能力,只要能让模型用上更多参数,就会有确定性收益。具体的路由方法介绍见后文。
(2)训练效率与落地性价比高
- 128专家的Switch-Base模型,相比稠密T5-Base实现了7倍的训练加速,大幅缩短超大规模模型的训练周期。
- 当下所有顶尖开源模型(DeepSeek-V2/V3、Mixtral、Llama 4、Grok、Qwen等)均采用MoE架构,在激活参数量远低于稠密模型的前提下,实现了SOTA的下游任务效果。
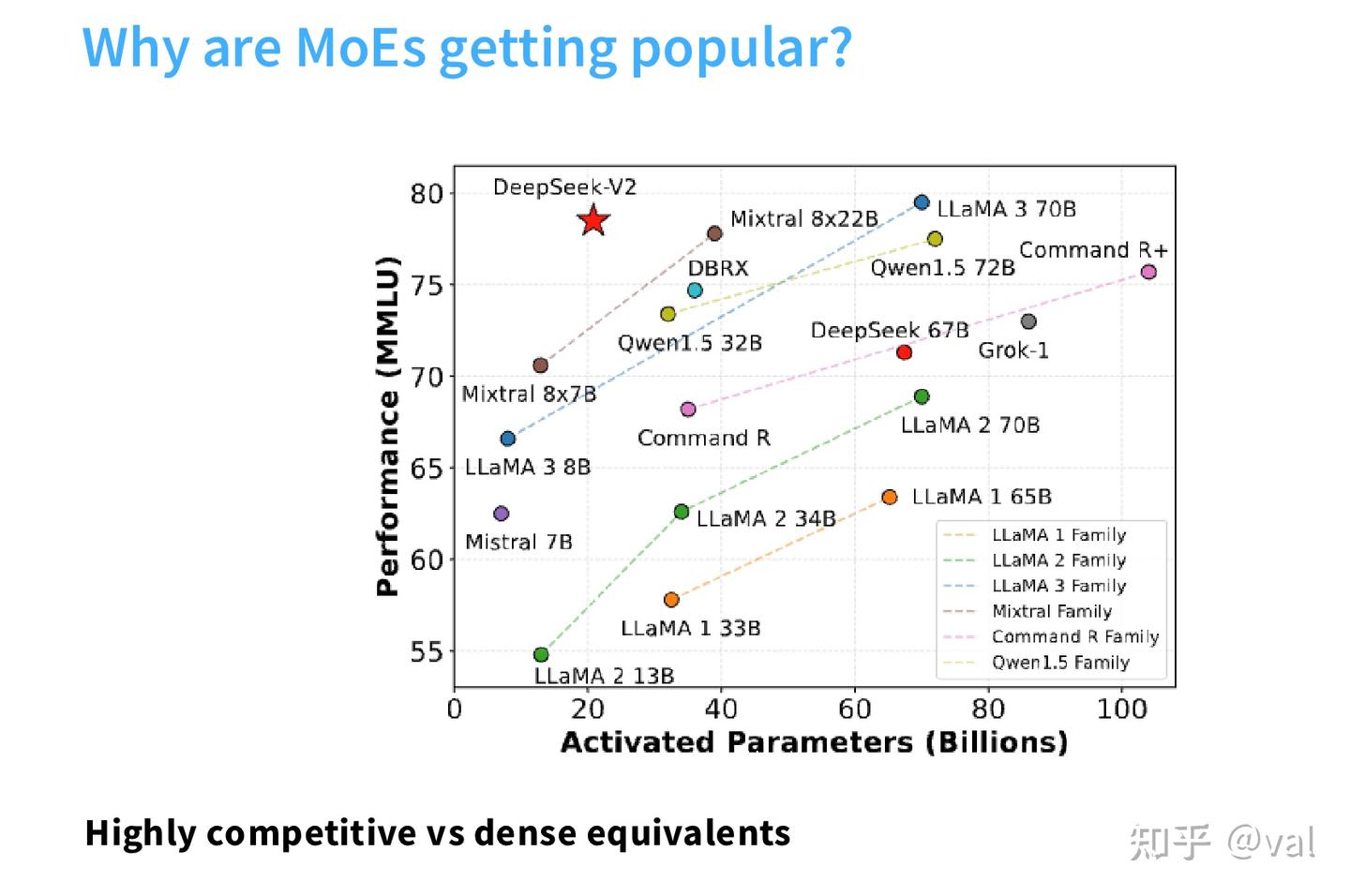
- 很多厂商的效果曲线横轴只标注“激活参数量”,刻意隐去总参数量。比如DeepSeek-V3用37B激活参数量对标70B稠密模型,但它的总参数量是671B——这不是“用更少参数做到更好效果”,而是“用更少的计算量,调动更大的参数容量”,二者的研发成本、部署门槛完全不是一个量级,评估MoE必须同时看总参和激活参。
(3)天然适配超大规模模型的分布式训练
专家的存在,让专家并行(expert parallelism) 成为非常自然的并行方式。MoE 有多个独立的前馈模块,可以把每个专家部署在不同设备上;由于专家是稀疏激活的,只需要把 token 路由到对应设备,计算就在该设备完成。这是模型分片到多设备的天然切分点,这也是 MoE 流行的另一大原因。想要并行化超大规模模型,这是必经之路。
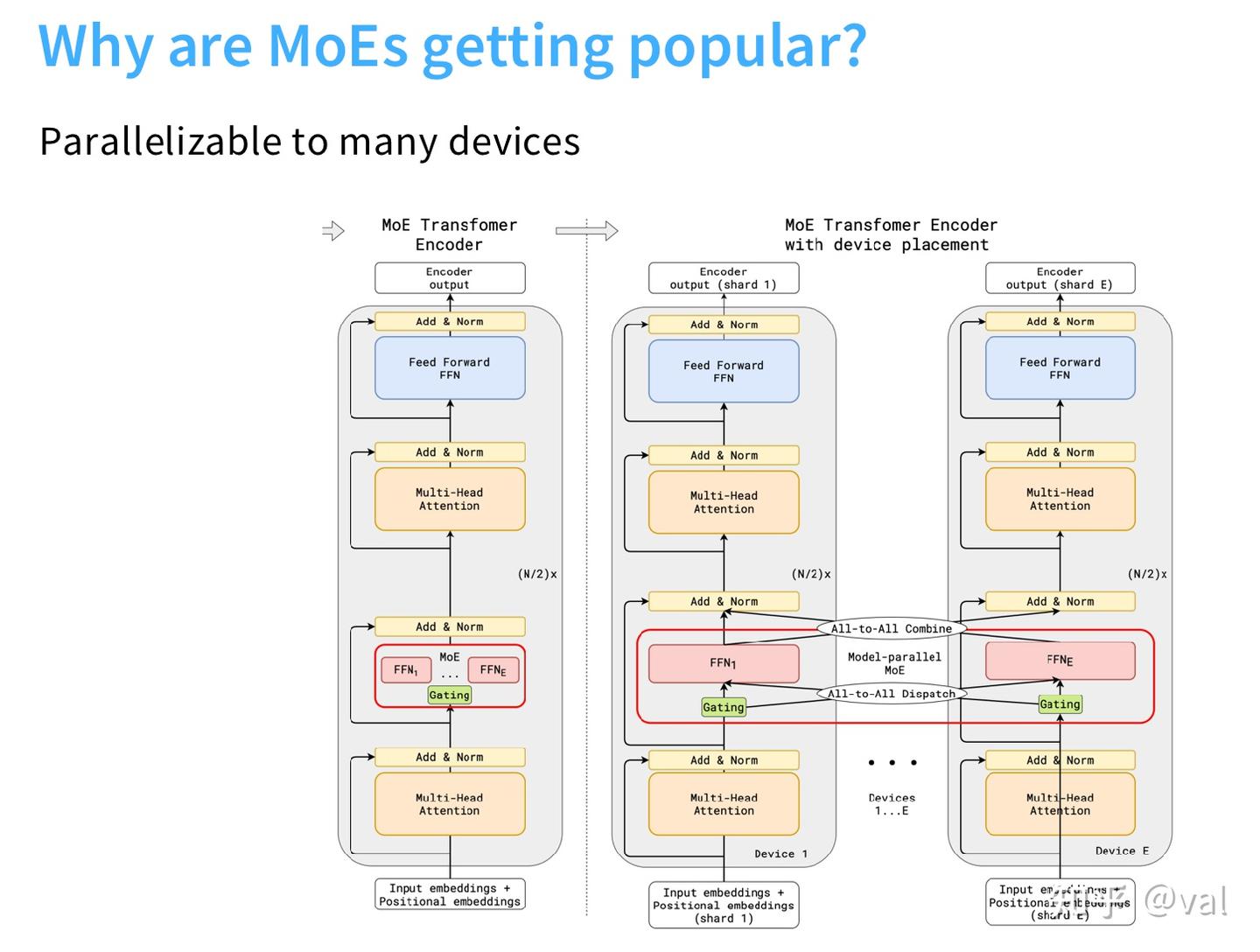
三、MoE 的通用架构与设计维度
不同 MoE 的设计差异主要体现在三个维度:
- 路由方式(Routing function)如何设计?
- 专家数量与单个专家规模(Expert sizes)如何设定?
- 不可微的路由模块训练(Training objectives)怎么进行?
路由函数(Routing function)
路由决策主要分为三类:
- token choice:每个 token 对不同专家计算偏好度,选择 Top-K 个专家;
- expert choice:每个专家对 token 排序,选择 Top-K 个 token 处理,优势是专家负载更均衡;
- global assignment:通过复杂优化问题,实现专家与 token 的均衡匹配。
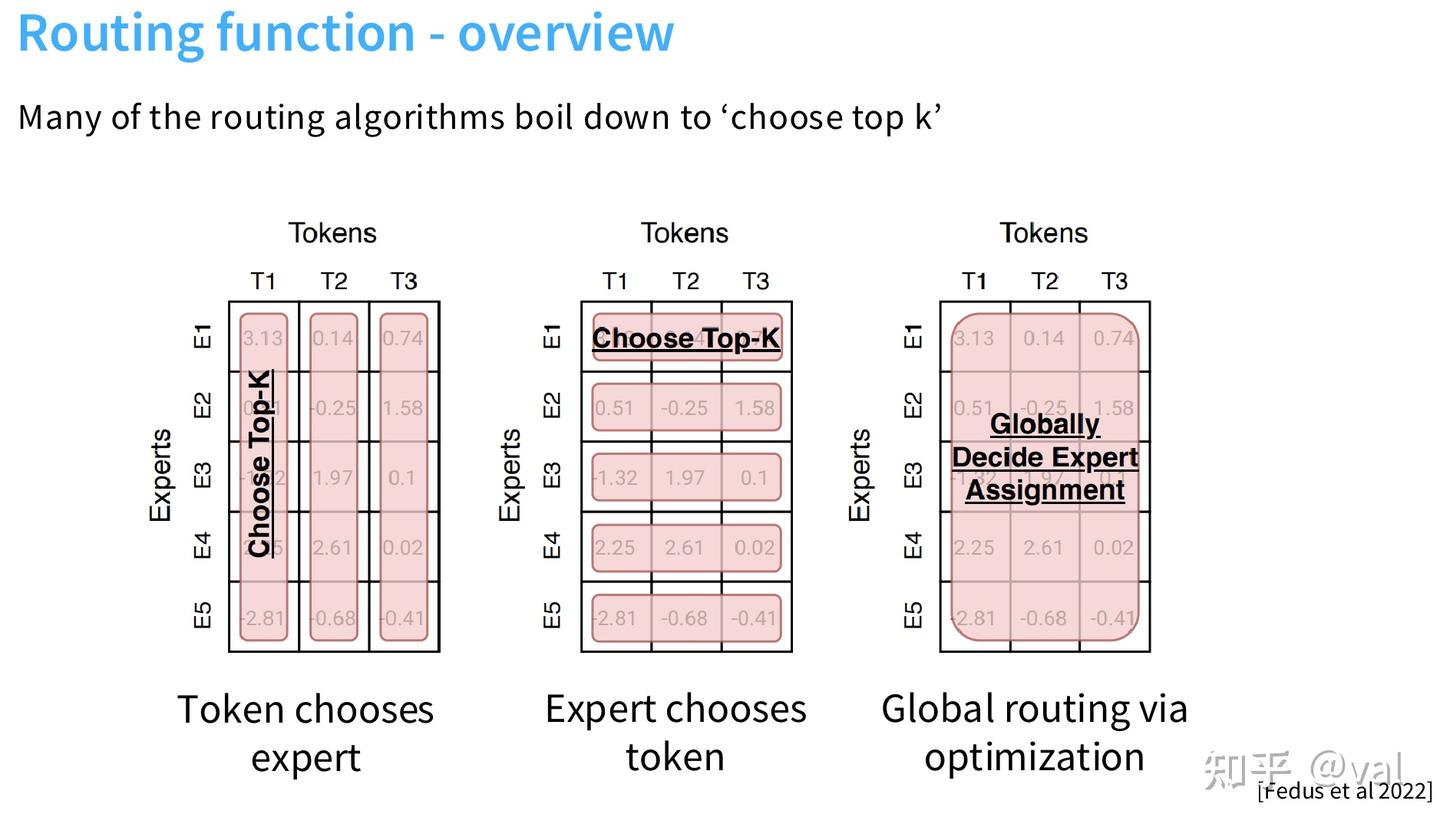
当前几乎所有落地MoE均采用Token 选择Top-K路由。MoE 发展早期,出现过各类路由方案,但主流模型最终都收敛到这一机制:每个 token 对专家按亲和度排序,选择 Top-K 个专家激活。核心计算流程如下:
- :第 l 层输入的残差流隐状态
- :第 i 个专家的前馈网络
- :门控权重,仅Top-K个专家非零,其余置0,定义为:
- :token 与专家的亲和度评分,经典实现为 ,其中 为第 i 个专家的可学习路由向量。
【Q&A】 Q1:路由决策是基于 token 本身,还是它的位置? A1:基于 token 的隐层状态(hidden state)。token 会经过位置编码等完整处理,生成隐层状态后,再输入路由模块与专家层,位置信息已经被编码在隐状态中了。 Q2:为什么这里要先做 Softmax 再取 Top-K?Softmax 会倾向于突出单一最大值,和 Top-K 选多个专家的逻辑不是矛盾吗? A2:不要把这里的 Softmax 当成“概率选择”,它的核心作用只是归一化到1,保证后续加权求和的权重和为1。如果去掉 Top-K、直接用 Softmax 门控所有专家,就会完全丧失稀疏性,丢掉MoE的系统效率优势——Top-K才是保证稀疏性的核心,Softmax只是数值归一化的工具。
Top-K 路由的主流变体与设计细节
- K 值选型:不同模型的 K 值设计不同,Switch Transformer (k=1)、GShard/Grok/Mixtral (k=2)、Qwen/DBRX (k=4)、DeepSeek 系列 (k=6~8)。关于 K 值设计,有一个很重要的设计思路:Top-K 选 K=2,核心目的不是增加计算量,是为了训练时的探索。很多人以为 K=2 是为了双专家提升拟合能力,但真实初衷是解决路由的探索 - 利用困境:如果 K=1,模型会永远只选当前最优的专家,陷入 “强者恒强” 的局部最优,其他专家永远拿不到训练信号,直接 “死掉”;K=2 相当于给了模型探索的机会,让第二名的专家也能拿到梯度信号,学习差异化特征。
- Softmax 位置调整:DeepSeek-V3、Mixtral、DBRX 等模型,将 Softmax 从 Top-K 选择之前,调整到了 Top-K 选择之后,仅对选中的 K 个专家做 Softmax 归一化,进一步提升训练稳定性。
- 哈希路由:无学习过程,通过哈希函数将 token 映射到对应专家,是 MoE 的最低成本基线方案,仅用于效果对照,无工业落地价值。
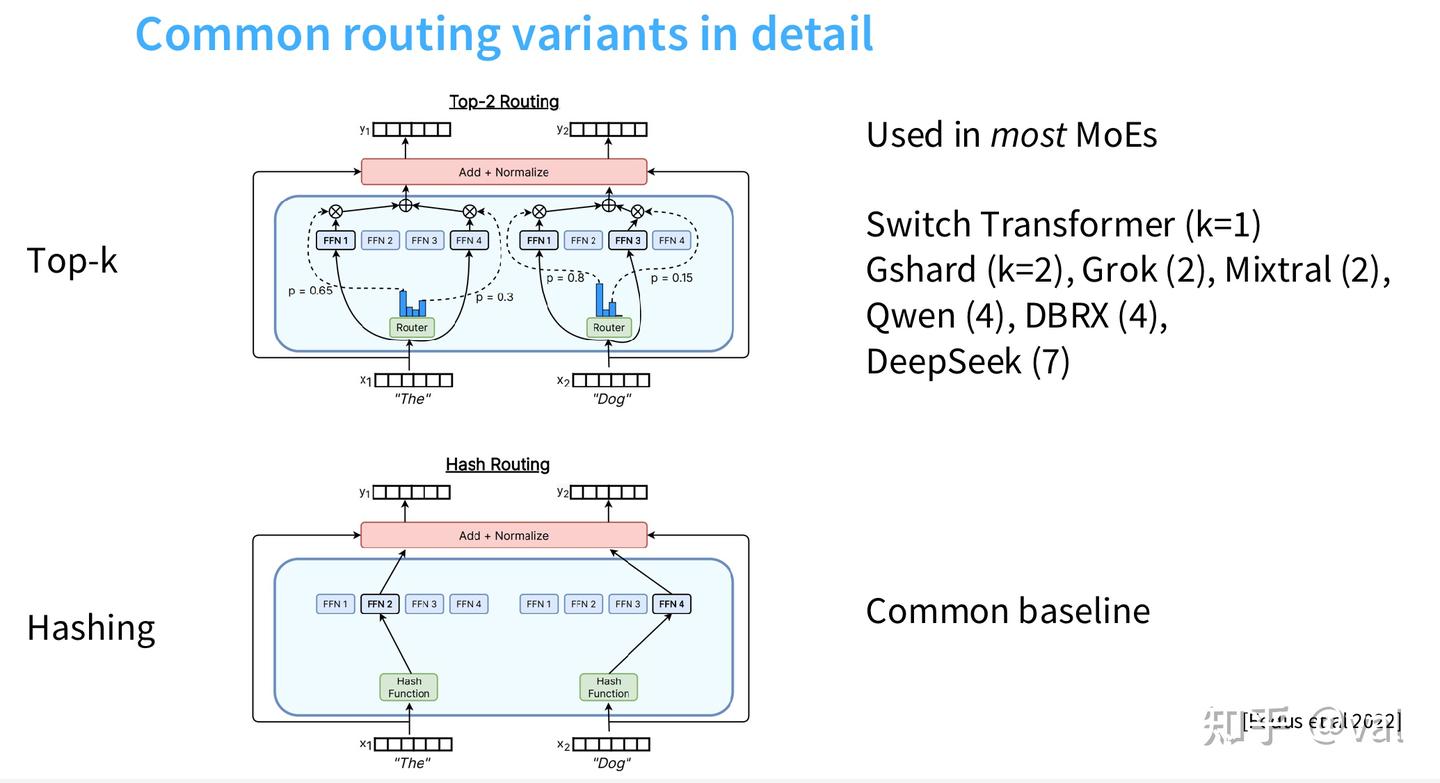
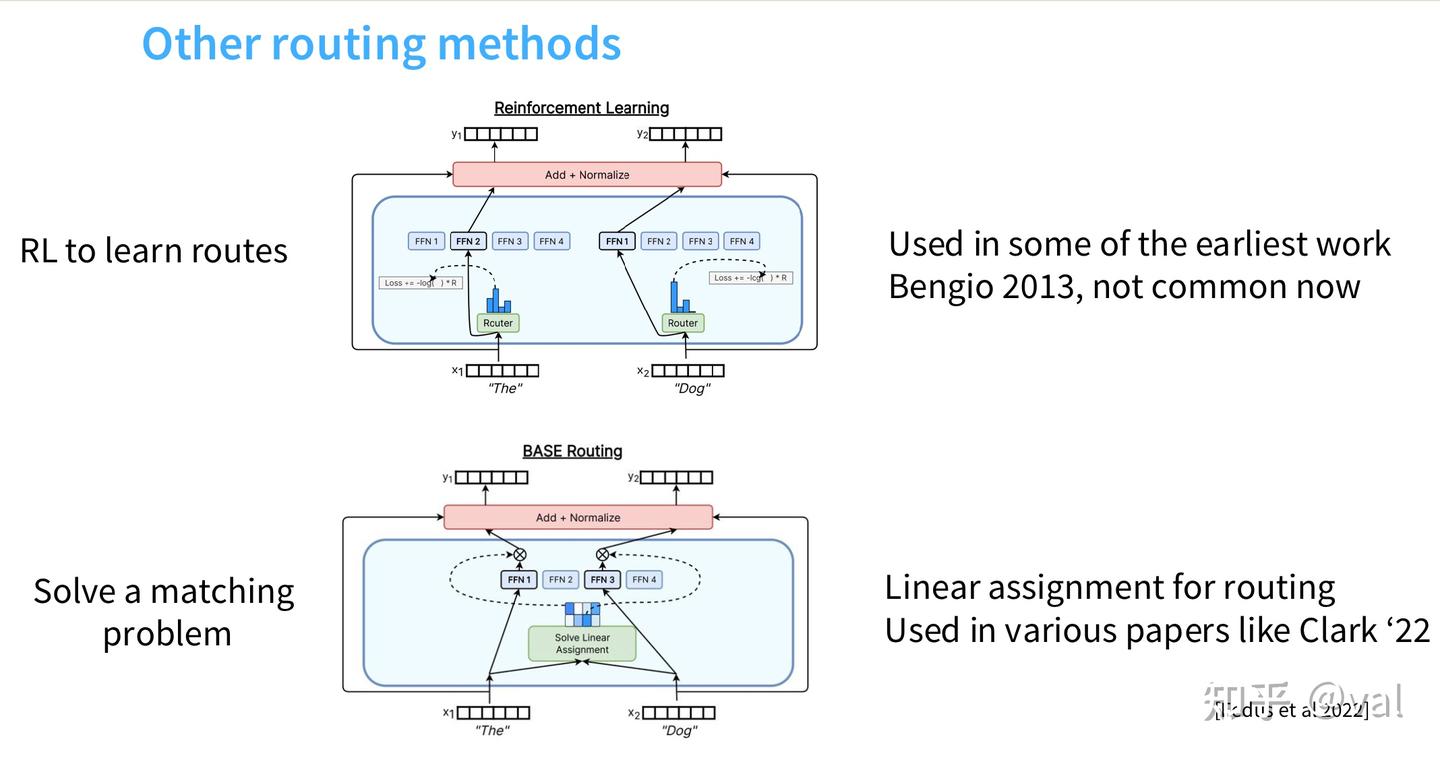
已弃用的小众路由方案:
- 强化学习(RL)路由:早期 Bengio 2013 提出,用 RL 优化离散路由决策,是理论上最适配的方案,但梯度方差大、训练复杂度高,无收益优势,工业界已完全弃用;
- BASE 线性分配路由:通过线性匹配优化全局 token - 专家分配,目前仅停留在论文阶段,尚无大规模落地。
【Q&A】 Q3:路由是MoE的核心,为什么路由模块设计得这么简单?为什么不用更复杂的MLP做路由? A3:有两个核心原因。第一是系统开销,路由的每一点FLOPs开销,都是纯额外成本,不会带来模型效果的直接提升,必须保证路由足够轻量化。第二是路由的梯度信号本身就非常间接,哪怕把路由模块做复杂,也无法保证能学到最优的路由策略,反而会加剧训练不稳定性。早期谷歌论文做过MLP路由的消融,没有拿到确定性的正向收益,工业界自然不会用。
专家规模设计(Expert sizes)
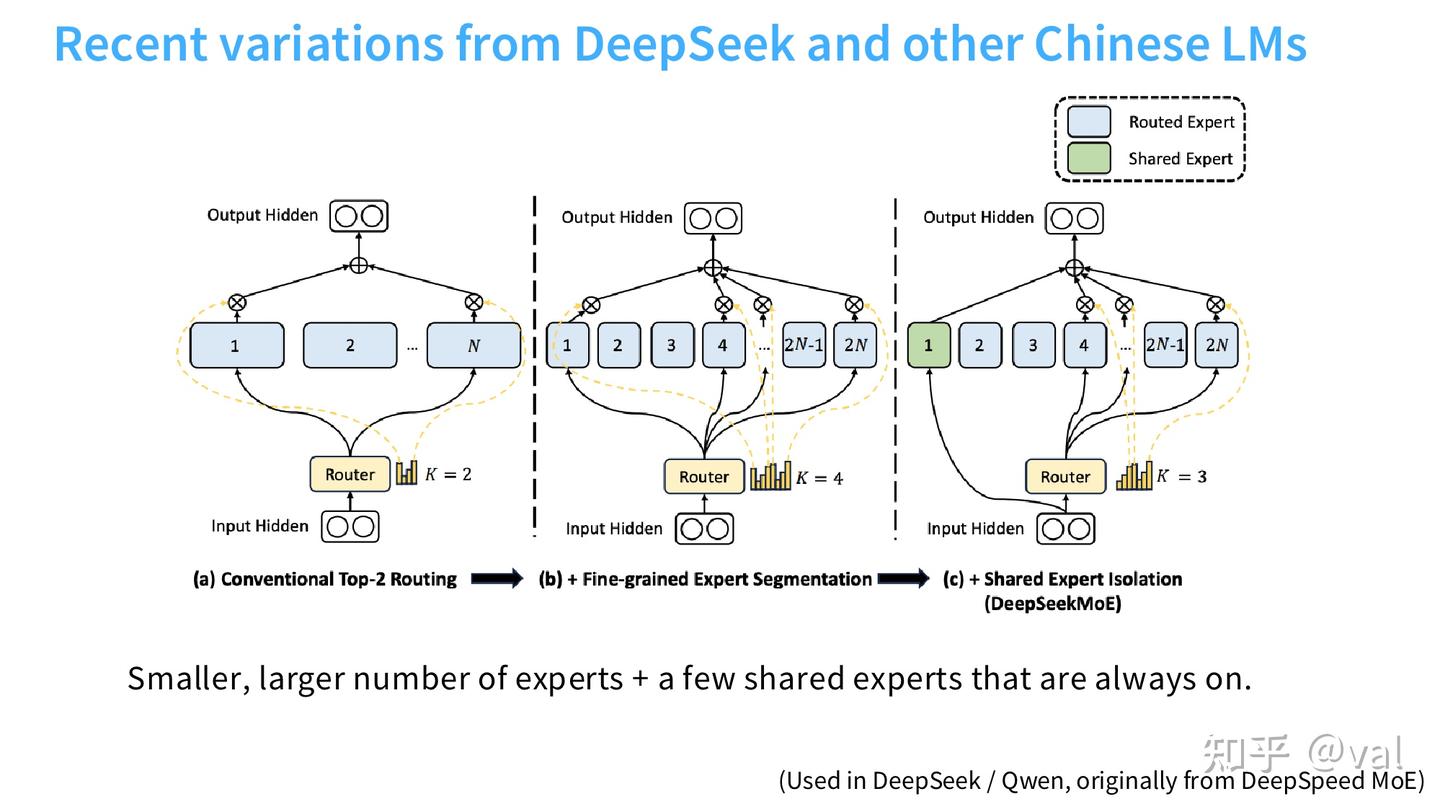
(1)细粒度专家(Fine-grained Experts)
- 设计思路:将标准 Transformer 的 FFN 按比例缩小(如 DeepSeek v1 为 1/4、v3 为 1/14),在激活参数量不变的前提下,大幅增加专家总数,提升专家的特征特异性。
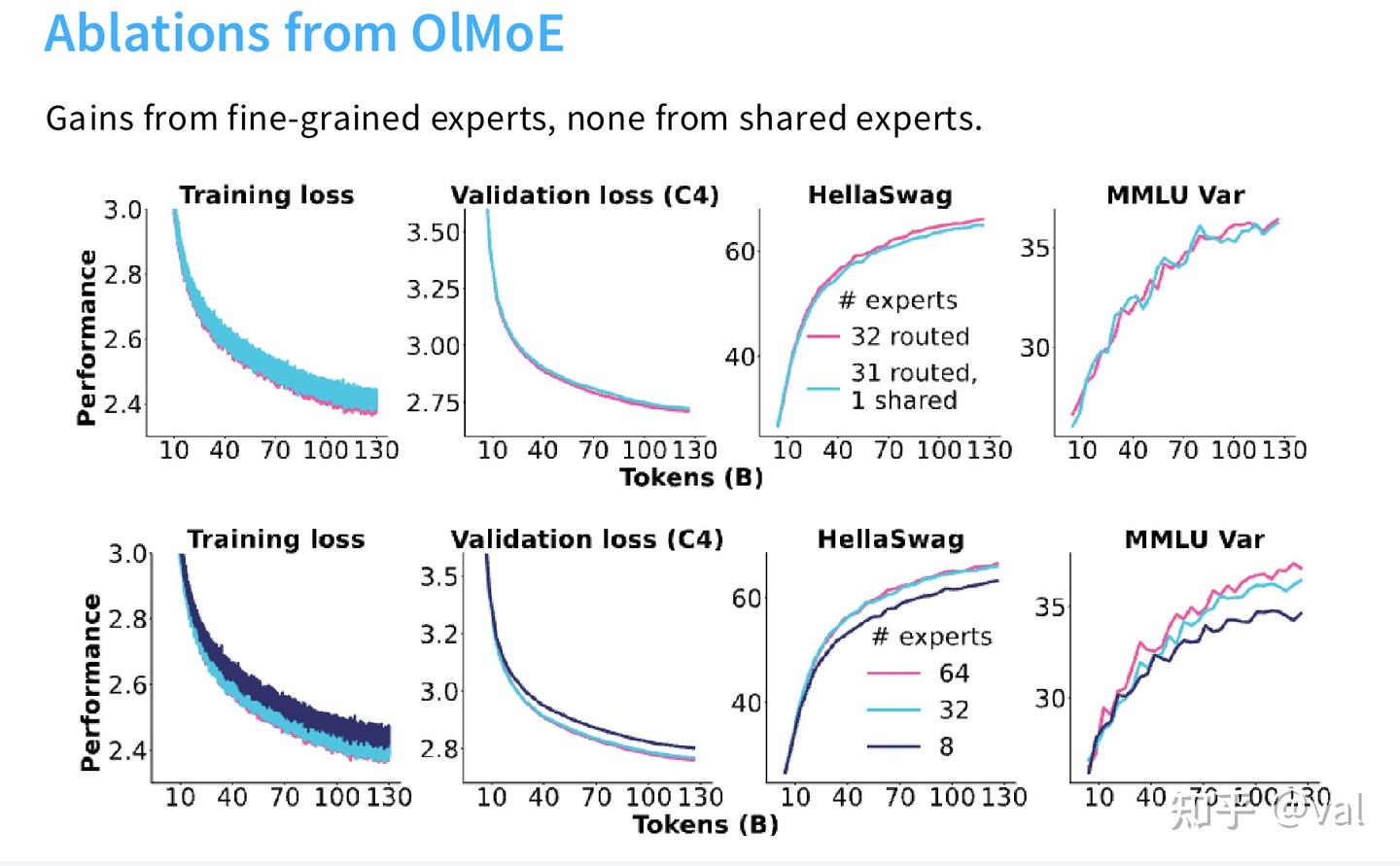
- 实验验证:OlMoE 的消融实验显示,细粒度专家从 8 个增加到 32、64 个,模型损失持续下降,收益极为显著。
- 架构设计的通用经验:细粒度专家是几乎无成本的正向优化,只要显存能装下,专家越细,效果越好,当前已成为所有工业级 MoE 的标配设计。
(2)共享专家(Shared Experts)
- 设计思路:设置 1~4 个始终激活的专家,处理所有 token 的通用语义特征,避免通用信息走稀疏路由造成的算力与参数浪费。
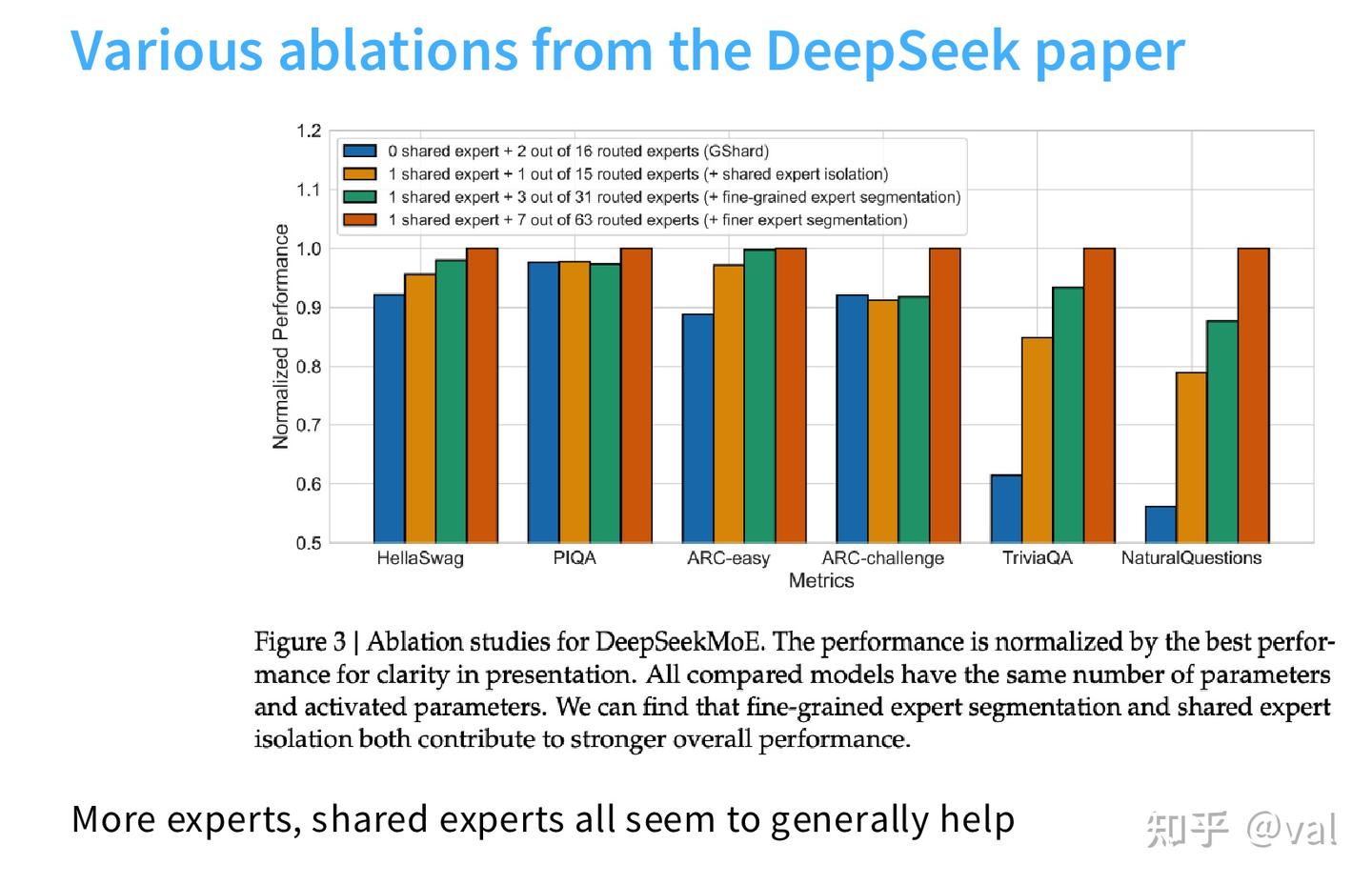
- 实验验证:DeepSeek 论文的消融实验显示,共享专家 + 细粒度专家的组合,能全面提升下游任务效果;但 OlMoE 的实验中,共享专家收益并不稳定,甚至出现负向效果,OlMoE 最终未采用共享专家。
四、MoE 训练的挑战与解决方案
MoE 训练的困境是效率与可微性的矛盾:
- 必须保持训练时的稀疏性,否则需要承担所有专家的 FLOPs 成本,完全丧失 MoE 的效率优势;
- 但稀疏门控的路由决策是离散、不可微的,无法直接通过梯度下降优化,同时极易出现专家负载不均衡,导致多数专家完全失效。
训练方案的演进
工业界最终放弃了 RL、随机扰动等复杂方案,收敛到了Top-K 路由 + 启发式负载均衡损失的朴素方案,用最低的成本解决了核心矛盾。
(1)强化学习(RL)优化路由(Reinforcment learning to optimize gating policies)
- 原理:将离散路由决策视为 RL 的动作,通过 REINFORCE 算法优化路由策略,是理论上最适配离散决策的方案;
- 工业界结论:梯度方差大、训练复杂度高、调试成本极高,收益完全覆盖不了成本,已完全弃用,无大规模落地案例。
(2)随机扰动近似(Stochastic perturbations)
- 原理:给路由 logits 添加高斯噪声 / 均匀乘性扰动,提升路由的探索性,避免模型陷入局部最优;
- 工业界结论:随机扰动会降低专家的特征特异性,对训练稳定性与效果无正向帮助,后续论文已验证其无效性,工业界已完全弃用。
(3)启发式负载均衡损失(Heuristic ‘balancing’ losses)

这是当前所有工业级 MoE 的训练核心,通过辅助损失强制各专家的 token 分配均匀,避免少数专家接管所有 token、其余专家失效。 ① Switch Transformer 基础均衡损失
- :第 i 个专家实际分配的 token 占比;
- :路由模块预测的第 i 个专家的概率占比;
- 核心特性:对分配 token 越多的专家,惩罚力度越强,强制模型均衡使用所有专家。
② DeepSeek v1-v2 双维度均衡优化 针对分布式训练场景,新增双维度均衡损失:
- 专家级均衡损失:保证单个专家之间的 token 负载均匀,和 Switch Transformer 基础损失一致;
- 设备级均衡损失:按 GPU/TPU 设备聚合统计,保证多机多卡间的计算负载均匀,适配分布式训练。

③ DeepSeek-V3 创新:无辅助损失均衡 为每个专家设置可在线学习的偏置bi,根据每批次的 token 负载动态调整:专家分配 token 过少则上调bi,提升路由优先级;分配过多则下调bi,降低优先级。大幅提升了训练稳定性,避免辅助损失对主任务的干扰;并且新增序列级辅助损失,避免单条推理序列内出现极端专家负载不均衡。

关于负载均衡损失,有一个很重要的认知纠偏:它的本质不是为了系统效率,而是为了不浪费参数。绝大多数资料会把负载均衡损失解释为 “让多机多卡负载更均匀,提升训练效率”,但它的第一优先级根本不是系统优化 —— 哪怕你单卡跑 MoE,不做任何分布式训练,也必须加负载均衡损失。没有约束的路由,一定会在训练初期就把所有 token 分给 1-2 个专家,剩下的所有专家完全收不到任何 token,永远不会被更新,相当于你花了大量显存存了一堆完全没用的参数,模型直接退化成了比稠密模型还差的小模型。负载均衡损失的首要作用,是保证所有专家都能被用到,不浪费参数容量,其次才是系统层面的负载均衡。
OlMoE 的对照实验验证了去掉负载均衡损失后,训练初期 1-2 个专家就会接管几乎所有 token,其余 6 个专家完全失效,模型退化为 2 专家 MoE,验证损失大幅上升,参数利用率极低。
MoE 训练稳定性的优化方案
根据实践经验,MoE 训练 90% 的崩溃问题,都出在路由模块的 Softmax 数值精度上。路由模块的 Softmax 对数值精度极度敏感,bfloat16 下 0.5 的舍入误差,就会导致门控权重出现 36% 的波动,引发训练损失剧烈 spike,甚至训练崩溃;工业界解决方案:
五、MoE 的工程系统侧设计
MoE 的理论非常简单,就是 “路由 + 多 FFN”,但它之所以没有像 Transformer 一样成为 NLP入门课的标准内容,是因为要让 MoE 高效跑起来,需要解决的工程基础设施问题,比理论难 10 倍都不止。它的优势只有在多节点、大规模分布式训练的场景下才能完全释放,单卡小模型用 MoE,不仅没有收益,还会因为路由、通信的额外开销变得更慢、效果更差。
专家并行:MoE 的分布式并行方案
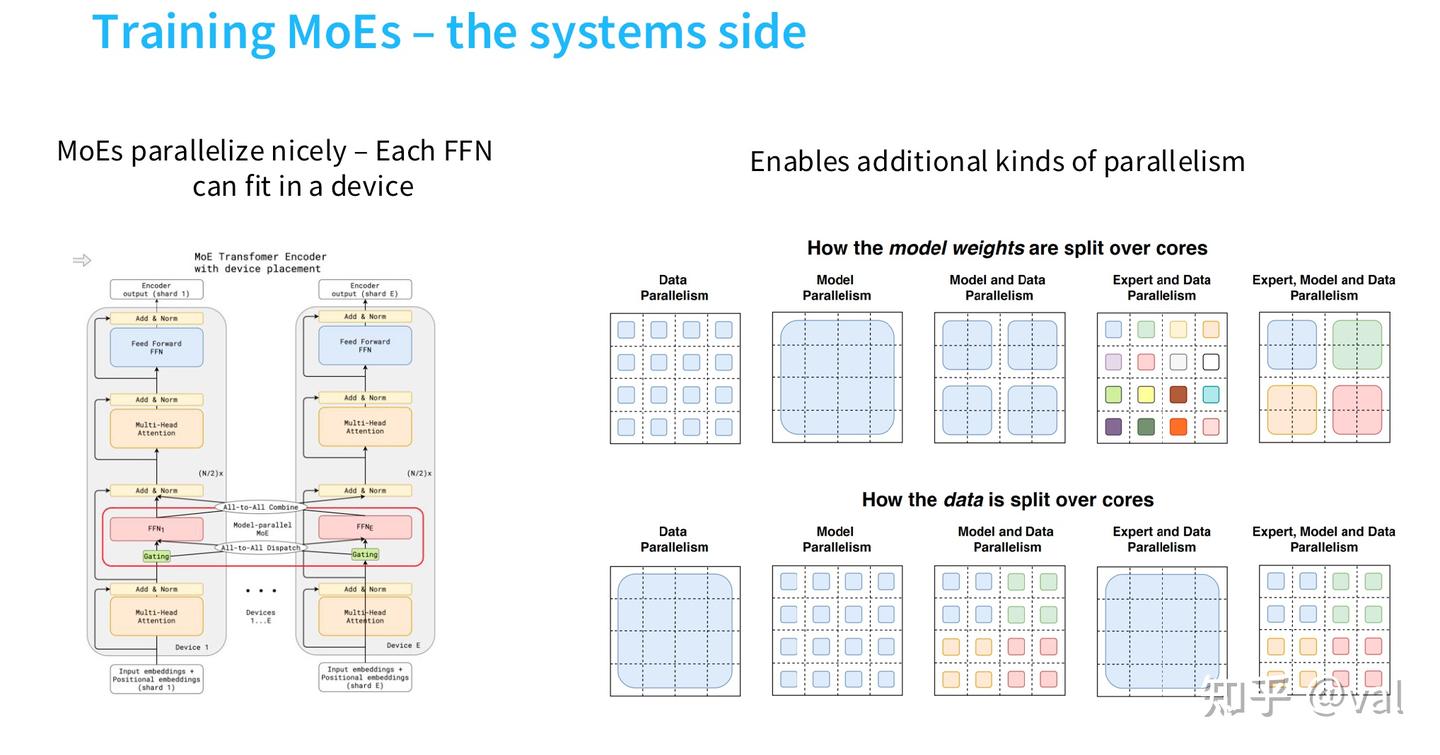
MoE 提供了独立于数据并行、张量并行、流水线并行的全新并行维度——将不同专家独立部署在不同 GPU/TPU 设备上,路由模块将 token 分发到对应设备完成计算,再通过 All-to-All 通信回收结果;
大模型分布式训练的核心就是在数据并行、张量并行、流水线并行之间做权衡,找到适配集群硬件的最优切分方式。而专家并行,给了我们一个全新的、完全独立的切分维度,可以和其他并行方式灵活组合,适配不同的集群网络、显存规格,这才是它在超大规模模型训练中不可替代的原因。
单设备稀疏计算优化
现代稀疏计算库(如 MegaBlocks,被多数开源 MoE 采用),利用 GPU 的块稀疏矩阵乘法引擎,优化单设备上多专家的稀疏计算,避免无效的零值运算,最大化算力利用率。
【Q&A】 Q4:上节课(Lecture 3)你提到,哪怕是可忽略的 FLOPs 操作,也可能带来极高的实际耗时,MoE 里有没有这种情况? A4:这正是 MoE 最大的落地痛点。很多人算 MoE 的收益,只看理论上的 FLOPs,但真正决定 MoE 能不能跑起来、跑的快不快的,是那些不计入 FLOPs 的开销 —— 比如 token 路由的 All-to-All 通信开销、专家分片的调度开销、负载不均衡导致的设备空等开销、稀疏矩阵乘法的调度开销。工业界做 MoE,80% 的工作量都在优化这些 “非 FLOPs 开销”,而非优化模型架构本身。
MoE 推理侧特性
(1)推理非确定性:token dropping
MoE 有一个有趣的随机特性:推理时如果批量 token 大量路由到同一专家,会触发token dropping 。这是因为推理时为了保证系统稳定性,每个专家都有一个容量上限,如果同一个批次里,大量 token 都被路由到了同一个专家,超出容量的 token 会被直接丢弃,MLP 层直接走残差连接,输出结果就会变; token 会不会被丢弃,完全取决于同批次里其他的请求会不会把专家占满 —— 这是一个完全不可控的、跨请求的随机因素。 所以触发 token dropping 的时候即使 temperature 设为 0 ,输出依旧是不确定的,这也是 GPT-4 早期推理非确定性的潜在原因之一(此前英伟达有一则有趣的泄密信息显示,GPT-4 可能是GPT-MoE-1 BT架构)。
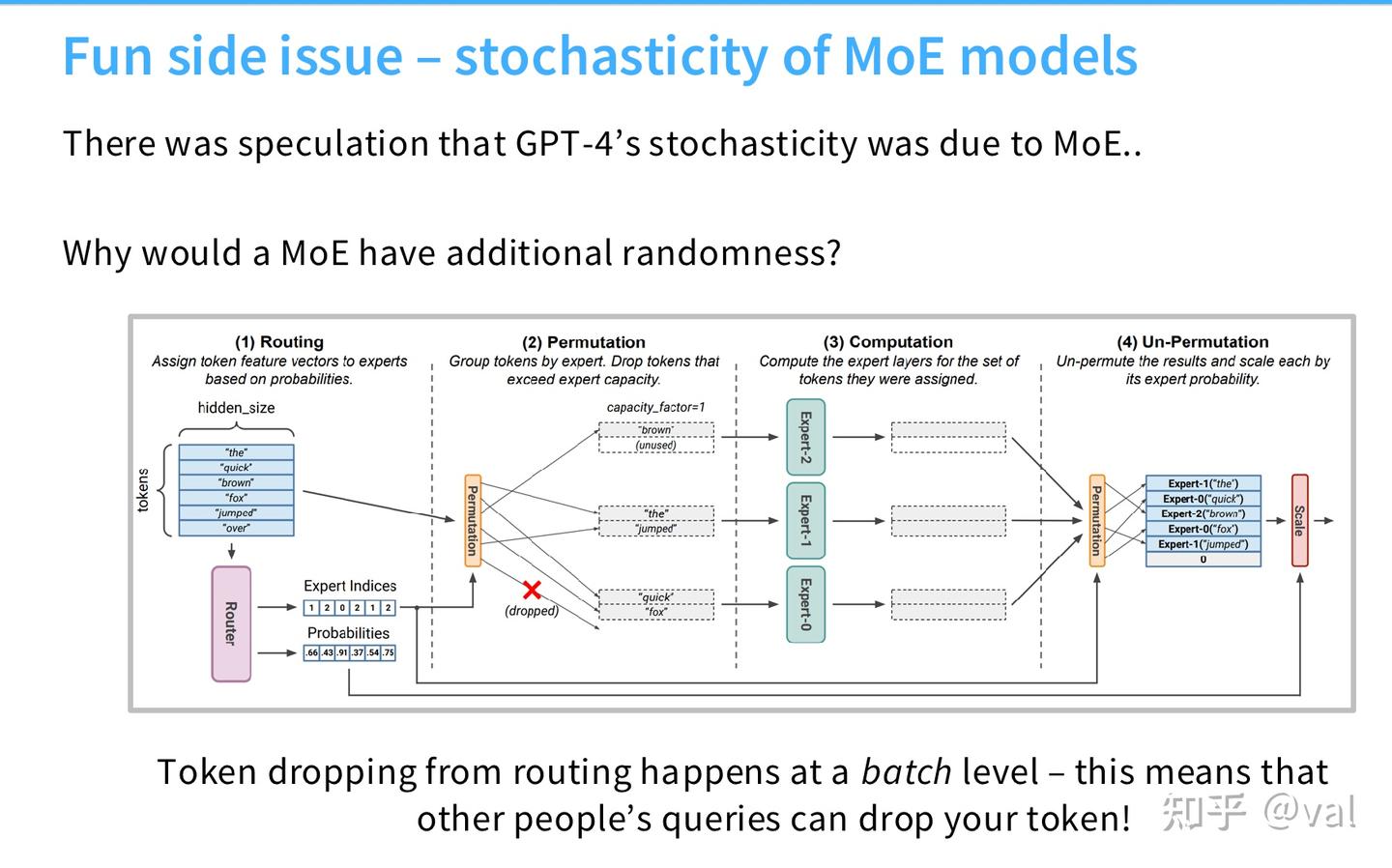
(2)MoE 推理成本的常见误区
很多人以为 MoE 的激活参数量小,推理成本就一定低,但真实落地中:如果 MoE 的专家被分散在多台机器上,每次推理都要跨机器做 token 路由和结果回收,通信延迟带来的成本,会完全覆盖激活参数量小带来的收益。工业界部署 MoE,往往会把多个专家打包放到同一张卡上,尽量减少跨机通信,甚至很多团队会为了降低推理延迟,直接把 MoE 改成稠密模型部署 —— 这也是很多论文里的推理速度,在真实线上场景里完全复现不出来的原因。
六、MoE 落地痛点与实操优化技巧
MoE 微调过拟合
MoE 的总参数量极大,哪怕激活参数量很小,总参也往往是同级别稠密模型的几倍甚至十几倍,在小数据集上微调,必然会严重过拟合。工业界验证有效的解决方案有两个:
中小团队 MoE 落地最优方案:稠密模型 Upcycling
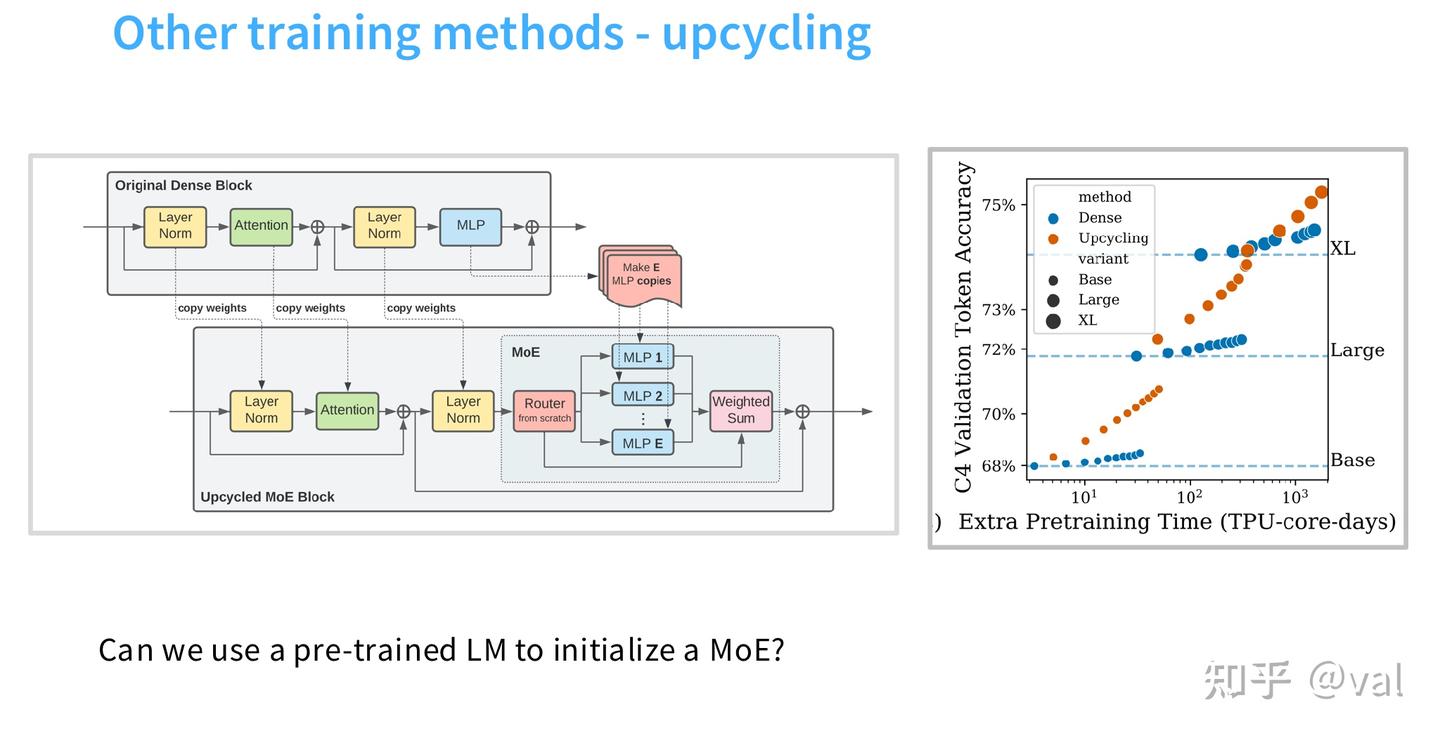
用预训练稠密模型的 FFN 权重,初始化 MoE 的多个专家,仅路由模块从头训练,无需从零开始预训练 MoE,大幅降低训练成本;这是中小团队落地 MoE 性价比最高的方式,没有之一。绝大多数团队不需要从零开始预训练一个 MoE,最优方案是拿一个已经训好的稠密模型,把它的 FFN 层复制多份初始化专家,只训练路由模块,用不到原稠密模型 10% 的预训练算力,就能得到效果远超原模型的 MoE。 案例:
七、DeepSeek MoE 架构演进
最后我们梳理下 DeepSeek MoE 的架构演进: DeepSeek MoE V1:160 亿总参数,28 亿激活参数,2 个共享专家 + 64 个细粒度专家,激活 4-6 个,标准 Top-K 路由 + 专家 / 设备均衡损失; DeepSeek MoE V2:2360 亿总参数,210 亿激活参数,架构基本不变,新增 Top-M 设备筛选:先选 Top-M 个设备,再在设备内选 Top-K 专家,降低通信成本,同时添加通信均衡损失; DeepSeek-V3:6710 亿总参数,370 亿激活参数,保留核心 MoE 架构,将门控值归一化、改用 Sigmoid 替代 Softmax,采用无辅助损失均衡 + 序列级均衡,保留 Top-M 设备优化。 此外,DeepSeek-V3 还做了两处非 MoE 架构优化:
- MLA(多隐层注意力):压缩 KV 缓存,将隐层状态投影到低维向量缓存,需用时再上投影为 K/V,合并矩阵乘法保证运算量不变,同时适配 RoPE 位置编码;
- MTP(多 token 预测):通过轻量级单层 Transformer,并行预测未来多个token(实际仅预测下一个),提升训练效率。
八、课程总结
整体来说,MoE 已成为高性能大规模大模型的核心架构,依托稀疏激活机制,在同等算力下实现更优效果。离散路由是其核心挑战,但启发式优化方案已被验证有效。在算力受限的场景下,MoE 是性价比极高的选择,值得深入学习。
- 认知层面:MoE 的核心价值是利用稀疏性,实现同等 FLOPs 下更高的参数量与更优的模型效果。2025 年MoE 对稠密模型的优势已无争议,是超大规模大模型的工业级主流架构。
- 架构层面:工业界已完全收敛到 token 选择 Top-K 路由 + 细粒度专家的成熟范式,共享专家需结合场景做消融验证,复杂路由方案尚无落地价值。
- 训练层面:离散路由是 MoE 的主要优化挑战,工业界最终选择了Top-K 路由 + 启发式负载均衡损失的朴素方案,负载均衡的首要目的是保证参数利用率,而非单纯的系统效率。
- 工程层面:MoE 的落地瓶颈是工程系统复杂度。专家并行给分布式训练提供了全新的灵活维度,而决定落地成败的是通信、调度等系统开销。
- 落地层面:中小团队最高效的 MoE 落地方式,是基于稠密模型做 Upcycling 升级,而非从零预训练;MoE 微调的核心是解决过拟合,只能通过冻结专家或海量数据实现,无捷径可走。