如果你关注大模型系统工程(LLM Sys),你一定知道投机解码(Speculative Decoding)。为了打破大模型自回归(Decode)阶段受限于显存带宽(Memory-Bound)的物理枷锁,让轻量的小模型(Draft)先“猜”、大模型(Target)再并行“验”,已经成了行业共识。
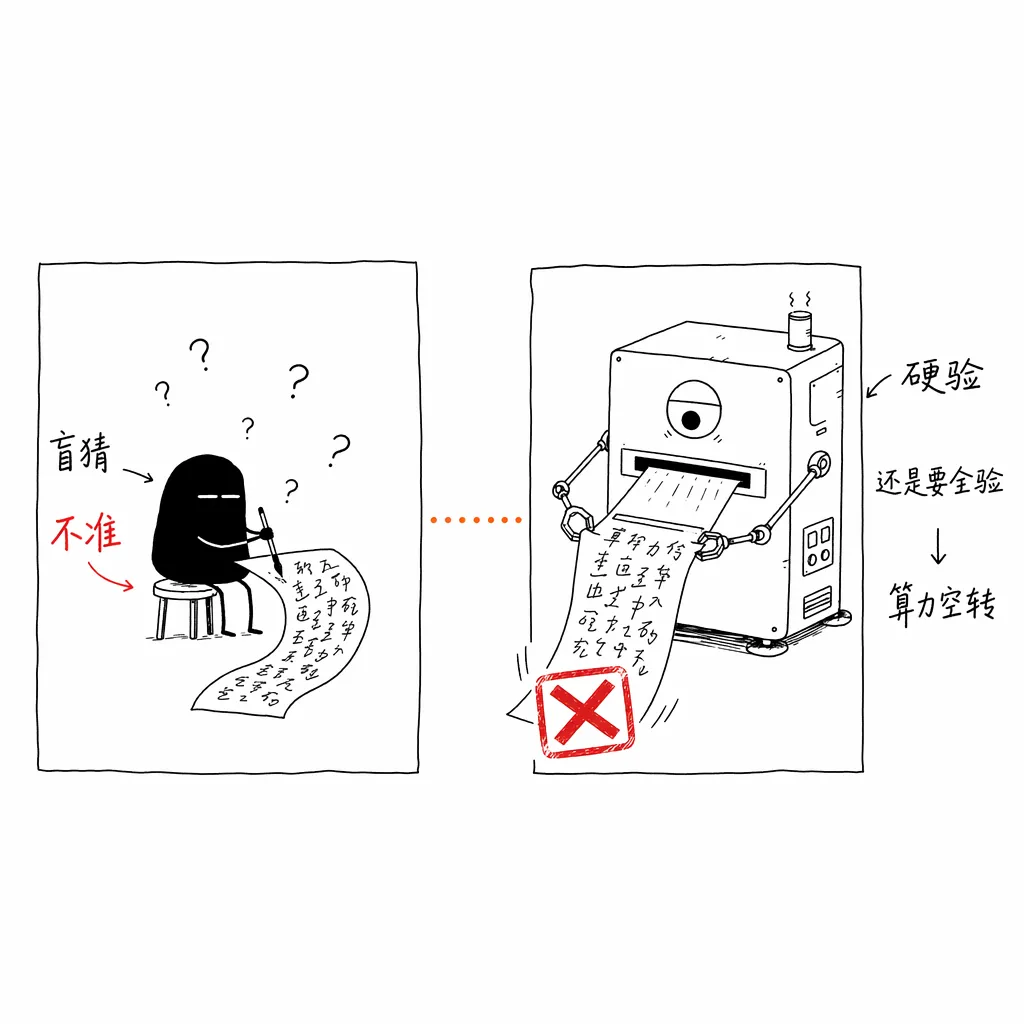
但在实际落地的万卡生产环境里,投机解码长期面临着两个尴尬的硬伤:
- 小模型“盲猜”不准:为了快,有些小模型采用并行生成,字与字之间缺乏因果逻辑,导致大模型频繁拒收,偷鸡不成蚀把米。
- 大模型“硬验”极费:不管小模型猜得有多烂,系统都死板地把固定长度的 Token 塞给大模型验证,导致高并发时算力空转、严重浪费。
近日,DeepSeek 扔出了一套全栈软硬件协同的开源投机采样方案:DeepSpec(全栈开发库)与 DSpark(高性能加速框架及模型)。在保证模型输出完全无损的前提下,直接将 DeepSeek-V4 系列模型的每用户推理速度飙升了 60% 到 85%。
今天这篇博客,我们就结合技术报告的硬核细节,由浅入深地扒一扒 DeepSeek 是如何解决这两个终极矛盾的。
矛盾一:小模型怎么猜得更准?(从 DFlash 到 Domino 的半自回归演进)
要让草稿模型快,串行生成(生成 个词需要走 次前向传播)是不可接受的。于是学术界提出了 DFlash(块扩散模型)。它在输入端将未来的 个位置全部用特殊的 [MASK] 占位,然后只需经历一次 GPU 的前向传播,利用双向注意力机制(Bidirectional Attention)一次性将这 个位置的特征全部并行计算出来。
这种 的常数级常驻延迟极具诱惑力,但它带出了一个经典的学术问题:多模态冲突(Multi-modal Conflict)。
并行带来的“多模态冲突”
在概率论中,模型的输出往往是多峰分布(Multi-modal Distribution)。比如输入 我喜欢去,接下来既可以是 北京 也可以是 上海。
DFlash 一口气同时预测未来多个位置。因为第 2 个位置在预测时,根本不知道第 1 个位置最终采样的结果,它可能在第一个位置采样了 北,在第二个位置独立采样了 海(来自“上海”的概率峰值),拼接起来就变成了荒谬的 北海。这种缺乏因果联合概率建模的缺陷,导致大模型的平均接受长度(Average Acceptance Length)惨不忍睹。

DSpark 的解法:半自回归架构与低秩马尔可夫头(Markov Head)
为了在享受 DFlash 并行速度的同时找回因果逻辑,DSpark 吸收了 Domino 框架的精髓,演进为了半自回归架构(Semi-autoregressive Architecture)。
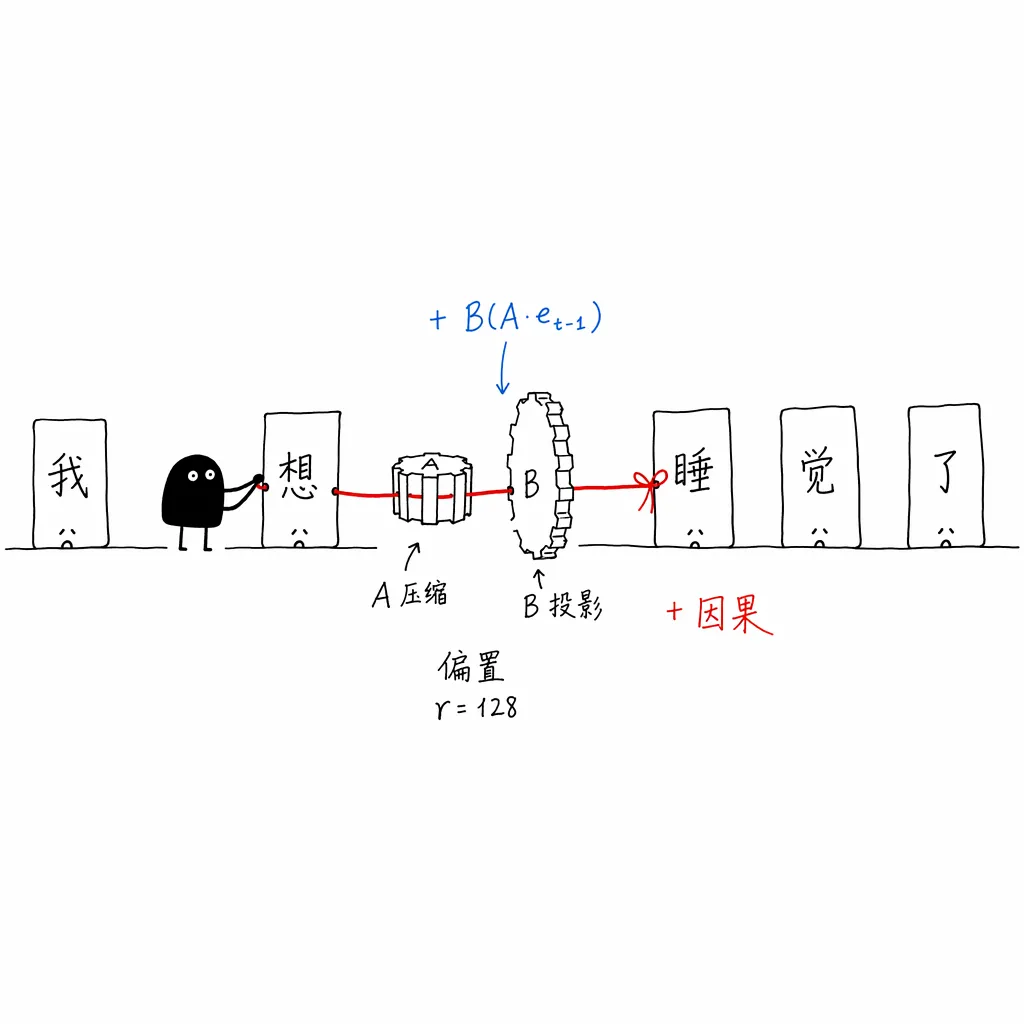
它的核心巧思是:在 DFlash 并行网络刷出初步的特征(Logits)后,在上面叠加一个极轻量的马尔可夫头(Markov Head)。
这个马尔可夫头采用一阶马尔可夫假设(当前词只与前一个词相关)。为了不让词表大小()导致的 转移矩阵撑爆显存,DSpark 巧妙引入了低秩分解(Low-rank Approximation)。它维护了两个低秩矩阵 和 (秩 ,如 ):
当前一个位置采样出真实的 Token 时,通过矩阵 压缩降维检索出语义,再通过 重新投影回 维空间,得到一个偏置向量(Bias Vector)。
根据信息论,在 Logits 空间做加法,等价于在概率空间做乘法()。它强制把前一个词的条件概率,乘到了并行盲猜的概率上。这种在局部注入依赖的精细对齐,让 DSpark 的平均接纳长度比业界前代标杆(如 Eagle3)再次暴涨了 26.7% 到 30.9%。
矛盾二:大模型怎么验得更高效?(硬件感知前缀调度器)
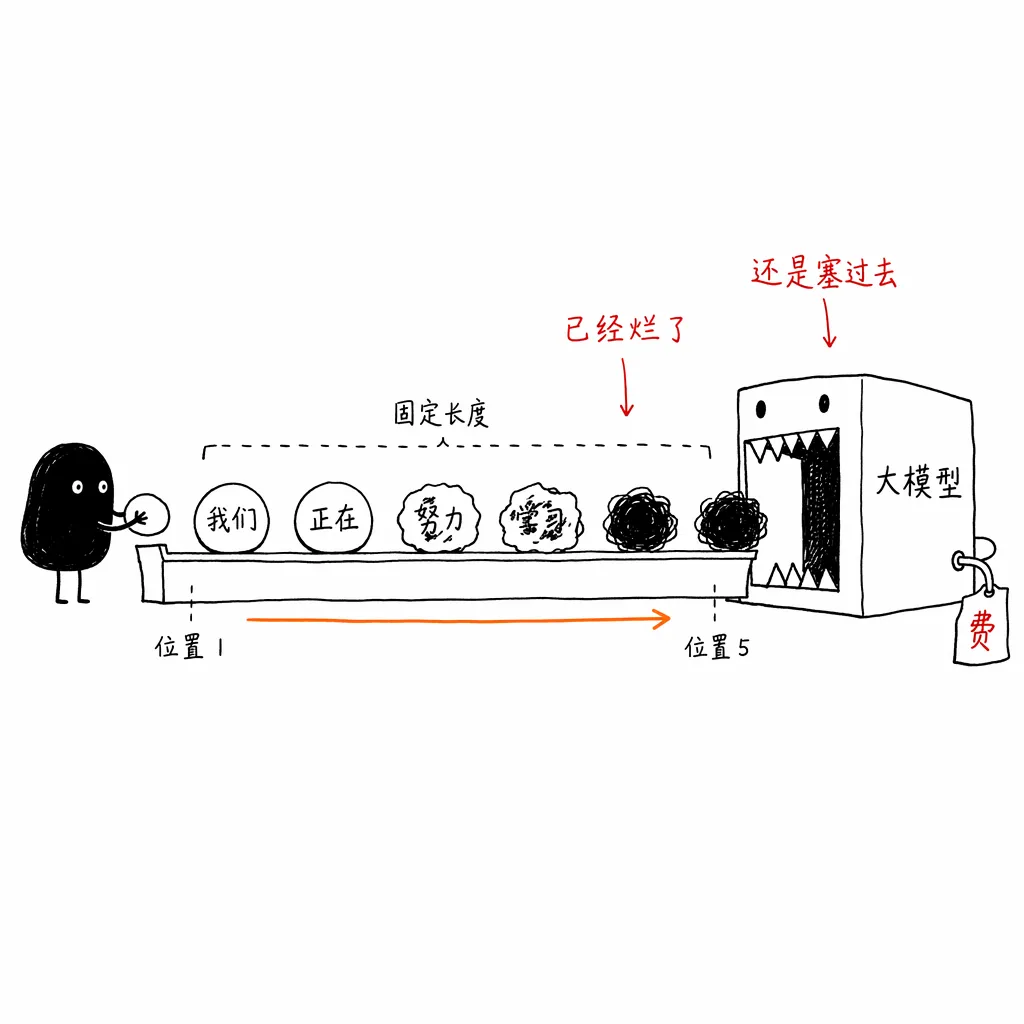
解决了“猜”的问题,接下来要解决“验”的问题。
传统投机采样采用固定长度验证(Fixed-length Verification),设定好验 5 个词,就雷打不动送 5 个。但实验表明,随着位置变远,小模型猜对的概率呈指数级后缀衰减。在高并发、大 Batch Size 的真实生产环境(吞吐量拉满)下,计算核心(ALU)极度宝贵,把注定会被大模型“拒收”的垃圾后缀 Token 强行送去验证,会造成严重的高并发验证浪费。
硬件感知前缀调度器(Hardware-aware Prefix Scheduler)
DSpark 引入了类似 D-Cut 的动态剪枝思想,在系统层做到了“硬件感知”。
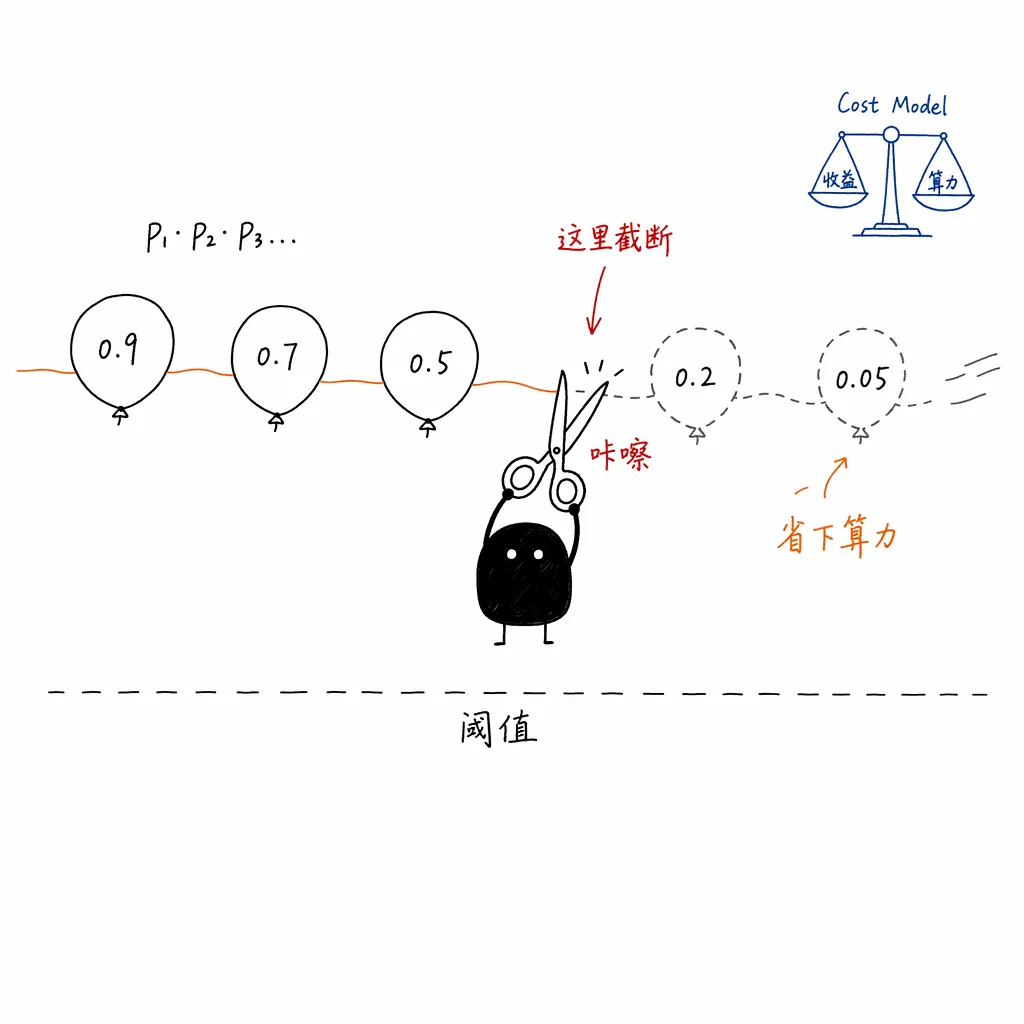
在服务启动时,调度器会首先对当前硬件(如 NVIDIA B200 节点)进行 Profile,测绘出不同并发下大模型验证不同长度 Token 的绝对硬件开销,构建出一个开销模型(Cost Model)。
在线上运行时,小模型(经过 Domino 头修正后)在输出块的每个位置都会吐出一个置信度 。由于大模型的验证是链式截断的(前面错了后面全作废),调度器会计算每个位置的联合存活概率(Survival Probability):
调度器会设定一个动态阈值。一旦某一步的累乘存活概率跌破安全线,调度器判定后续的验证期望收益已经低于硬件计算开销,就会立刻在此处截断(Cut),不让大模型去验证后面的垃圾 Token。把算力省在刀刃上,从而实现了真正的自适应验证深度。
全栈的胜利:从开源库 DeepSpec 到落地 DSpark
在 LLM 领域,在玩具模型上跑通算法发论文,与在数千亿参数、工业级并发的生产线上落地,中间隔着一万个工程大坑。DeepSeek 令人惊叹的地方,正在于其恐怖的工程化整合能力。
为了喂饱这个高精度的小模型,DeepSeek 推出了 DeepSpec 全栈开发库。它不仅定义了投机采样的全生命周期,还公开了其极具工业价值的“训练配方”:在数据准备阶段,让大模型离线生成标准答案,构建了高达 38 TB 的 Target Cache 离线缓存!用海量的高质量大模型“思考轨迹”去强监督对齐小模型。
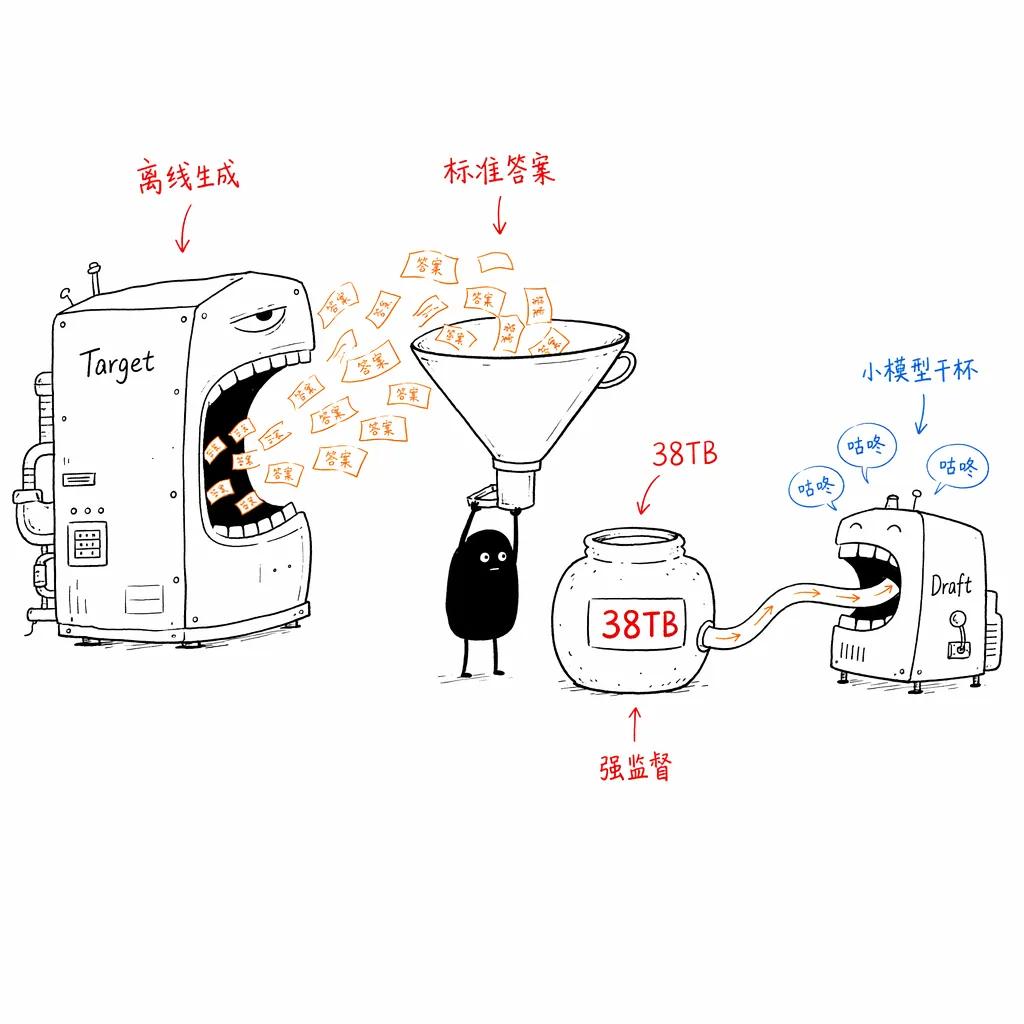
同时,DeepSpec 内置了包括 GSM8K、MATH500、LiveCodeBench 在内的 9 大核心基准,并使用宏平均接受长度(Macro-average Acceptance Length)作为天平——先算出每个垂直任务的平均接受长度,再做算术平均,确保每个技术场景在成绩单上权重平等,拒绝刷榜,死磕全场景泛化。
总结
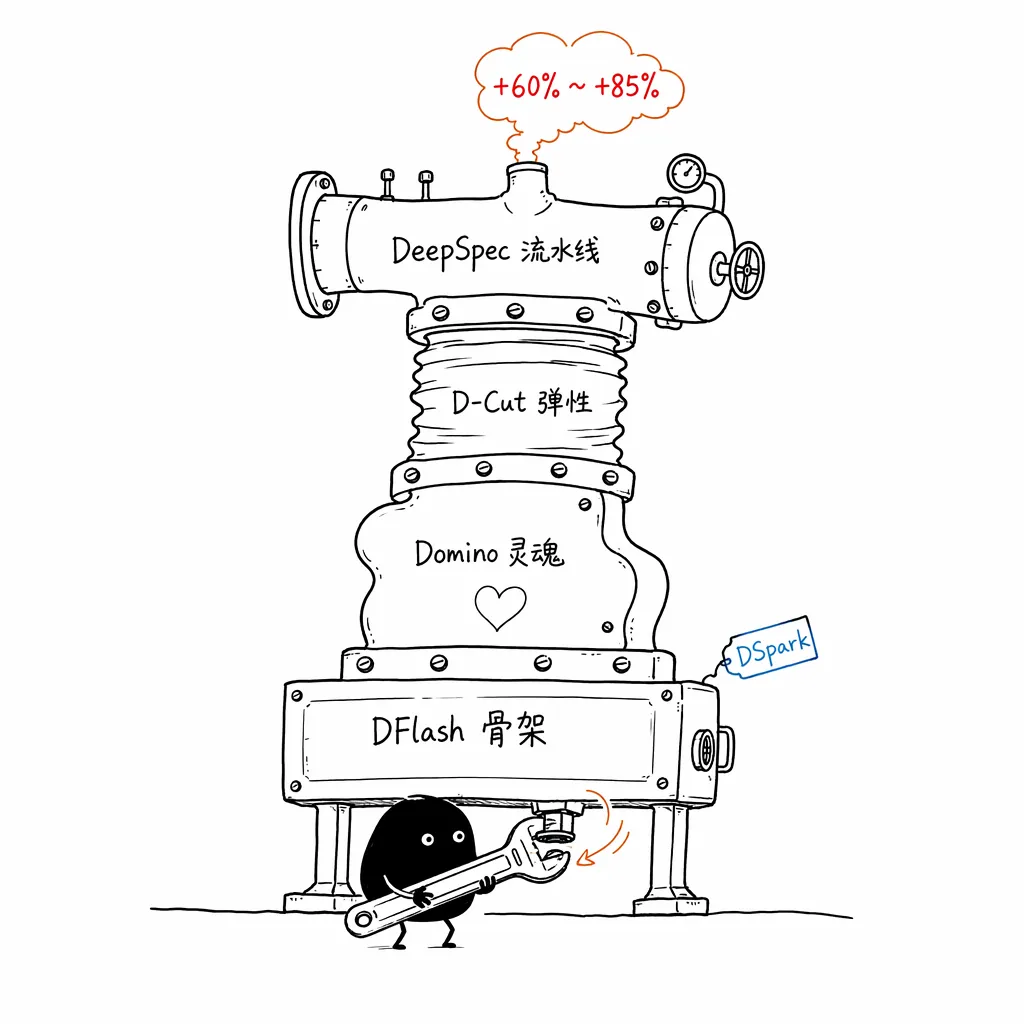
梳理完这条前沿脉络,我们可以清晰地看到这套方案的演进闭环:
- DFlash 贡献了速度的骨架(让草稿延迟从 变为 );
- Domino 思想 贡献了准度的灵魂(用低秩马尔可夫头抹平多模态冲突);
- D-Cut 思想 贡献了系统的弹性(用硬件感知与存活概率拒绝验证浪费);
- DeepSeek 用 DeepSpec 把散落的学术明珠组装成了 38TB 级别的工业流水线,并最终结出了 DSpark 这一颗无缝适配其最新 V4 大模型的全栈硕果。
这正是当前大模型推理系统(LLM Inference Optimization)最前沿、最硬核的演进方向。有了这套开源全栈方案,整个开源社区距离“天下武功,唯快不破”的终极推理体验,又向前跨出了一大步。